 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstrained Monotonic Neural Networks
Paper and Code
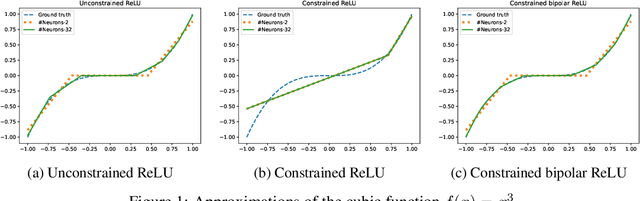
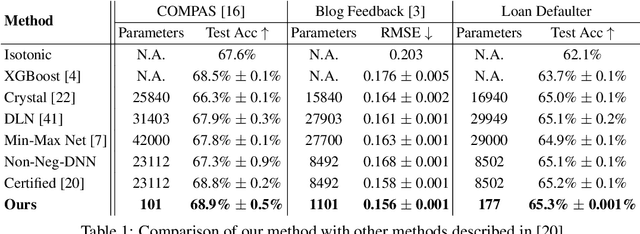
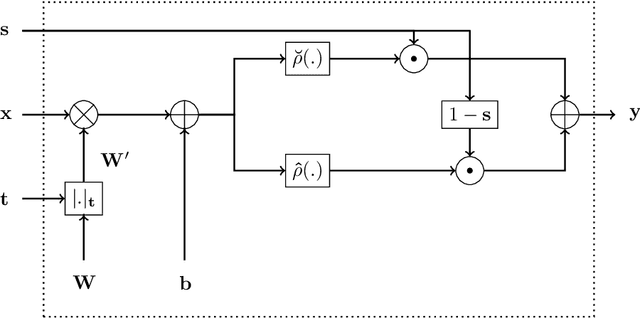
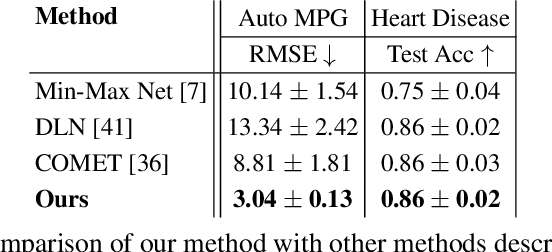
Deep neural networks are becoming increasingly popular in approximating arbitrary functions from noisy data. But wider adoption is being hindered by the need to explain such models and to impose additional constraints on them. Monotonicity constraint is one of the most requested properties in real-world scenarios and is the focus of this paper. One of the oldest ways to construct a monotonic fully connected neural network is to constrain its weights to be non-negative while employing a monotonic activation function. Unfortunately, this construction does not work with popular non-saturated activation functions such as ReLU, ELU, SELU etc, as it can only approximate convex functions. We show this shortcoming can be fixed by employing the original activation function for a part of the neurons in the layer, and employing its point reflection for the other part. Our experiments show this approach of building monotonic deep neural networks have matching or better accuracy when compared to other state-of-the-art methods such as deep lattice networks or monotonic networks obtained by heuristic regularization. This method is the simplest one in the sense of having the least number of parameters, not requiring any modifications to the learning procedure or steps post-learning steps.