 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEAR 2021: Holistic Evaluation of Audio Representations
Mar 26, 2022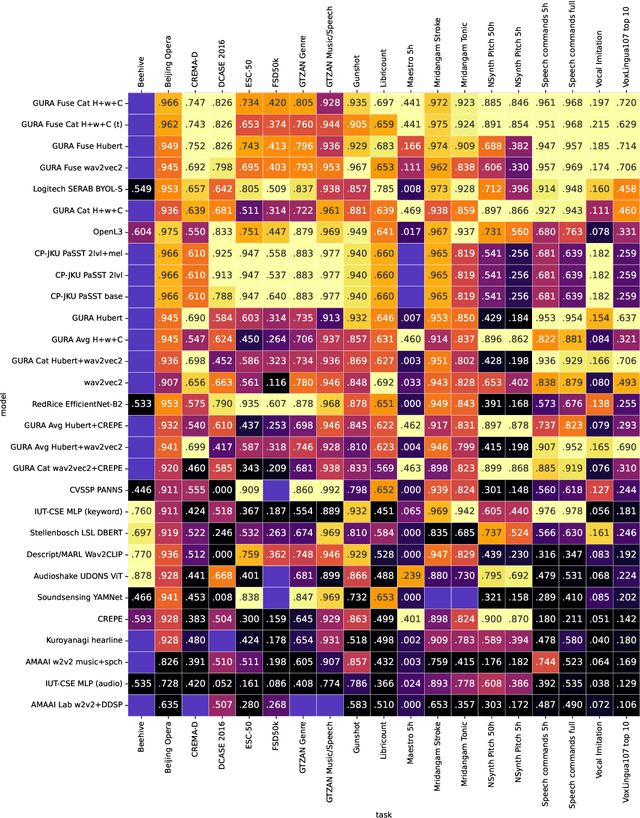
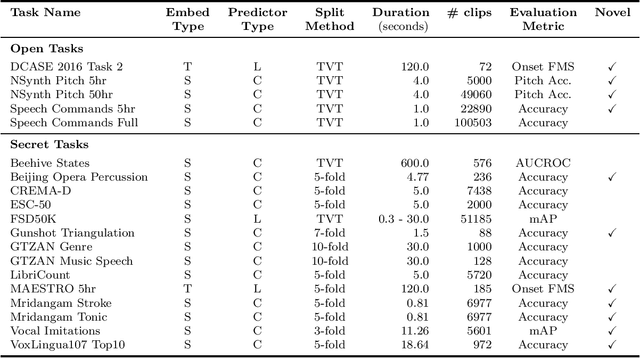

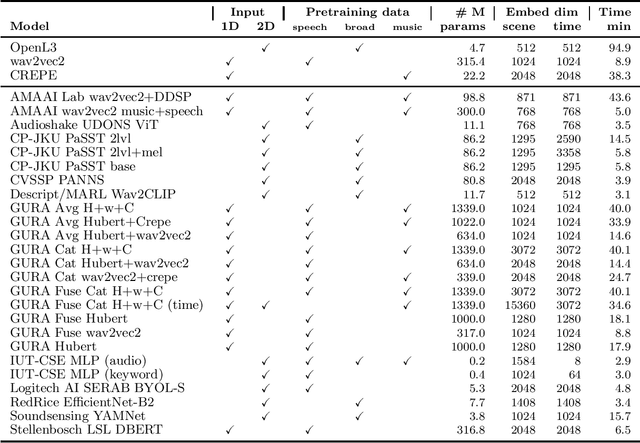
What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR 2021 NeurIPS challenge is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR 2021 evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.
One Billion Audio Sounds from GPU-enabled Modular Synthesis
Apr 27, 2021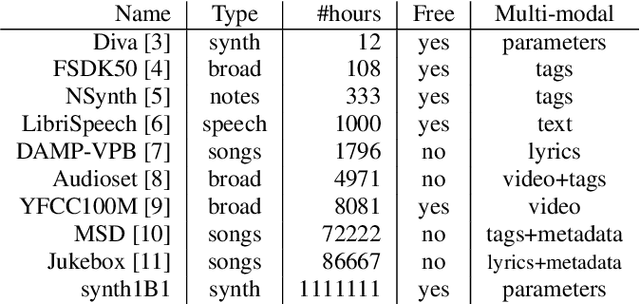
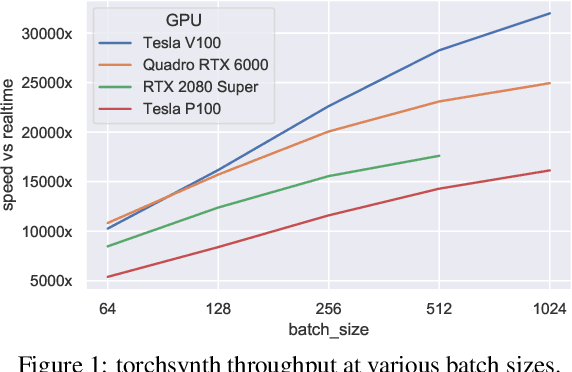
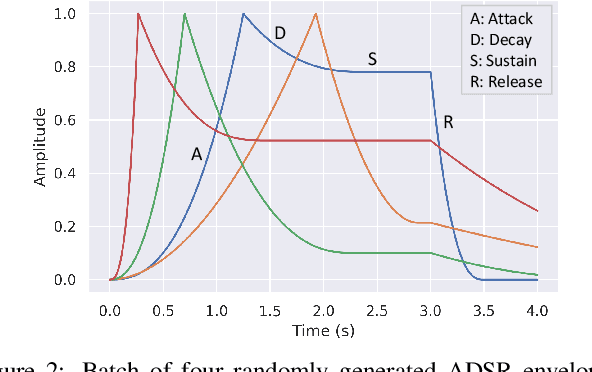
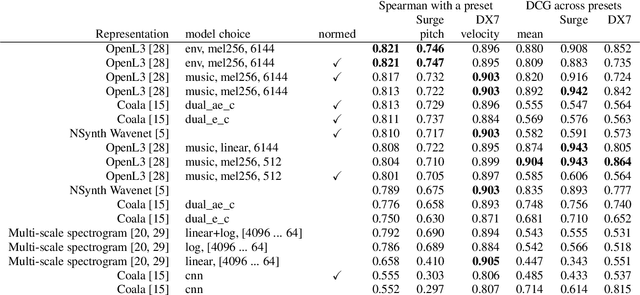
We release synth1B1, a multi-modal audio corpus consisting of 1 billion 4-second synthesized sounds, which is 100x larger than any audio dataset in the literature. Each sound is paired with the corresponding latent parameters used to generate it. synth1B1 samples are deterministically generated on-the-fly 16200x faster than real-time (714MHz) on a single GPU using torchsynth (https://github.com/torchsynth/torchsynth), an open-source modular synthesizer we release. Additionally, we release two new audio datasets: FM synth timbre (https://zenodo.org/record/4677102) and subtractive synth pitch (https://zenodo.org/record/4677097). Using these datasets, we demonstrate new rank-based synthesizer-motivated evaluation criteria for existing audio representations. Finally, we propose novel approaches to synthesizer hyperparameter optimization, and demonstrate how perceptually-correlated auditory distances could enable new applications in synthesizer design.
I'm Sorry for Your Loss: Spectrally-Based Audio Distances Are Bad at Pitch
Dec 09, 2020
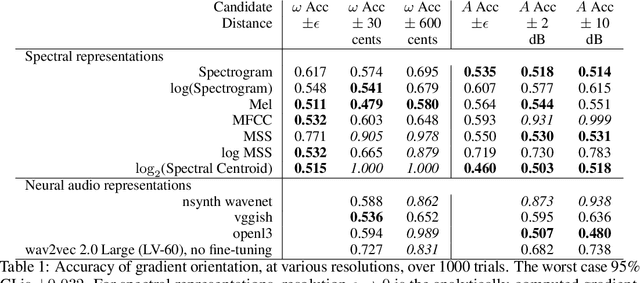
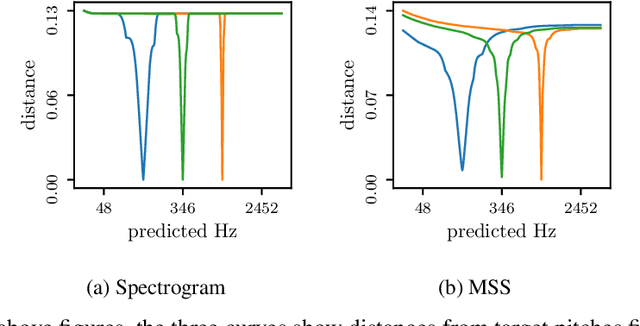
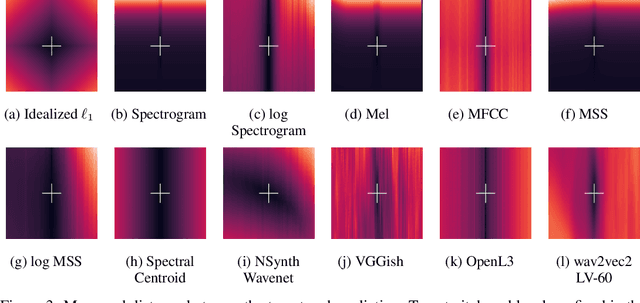
Growing research demonstrates that synthetic failure modes imply poor generalization. We compare commonly used audio-to-audio losses on a synthetic benchmark, measuring the pitch distance between two stationary sinusoids. The results are surprising: many have poor sense of pitch direction. These shortcomings are exposed using simple rank assumptions. Our task is trivial for humans but difficult for these audio distances, suggesting significant progress can be made in self-supervised audio learning by improving current losses.
Experience Grounds Language
Apr 21, 2020Successful linguistic communication relies on a shared experience of the world, and it is this shared experience that makes utterances meaningful. Despite the incredible effectiveness of language processing models trained on text alone, today's best systems still make mistakes that arise from a failure to relate language to the physical world it describes and to the social interactions it facilitates. Natural Language Processing is a diverse field, and progress throughout its development has come from new representational theories, modeling techniques, data collection paradigms, and tasks. We posit that the present success of representation learning approaches trained on large text corpora can be deeply enriched from the parallel tradition of research on the contextual and social nature of language. In this article, we consider work on the contextual foundations of language: grounding, embodiment, and social interaction. We describe a brief history and possible progression of how contextual information can factor into our representations, with an eye towards how this integration can move the field forward and where it is currently being pioneered. We believe this framing will serve as a roadmap for truly contextual language understanding.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016
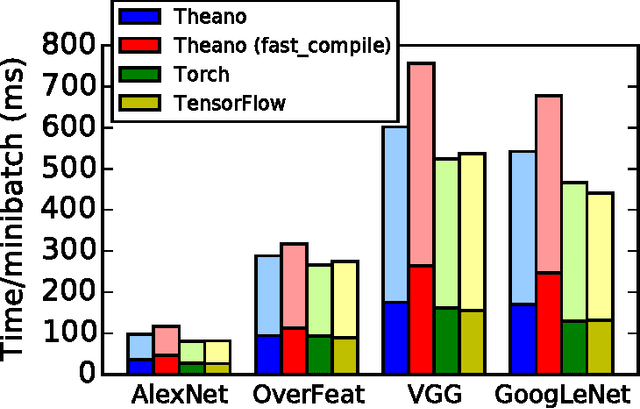
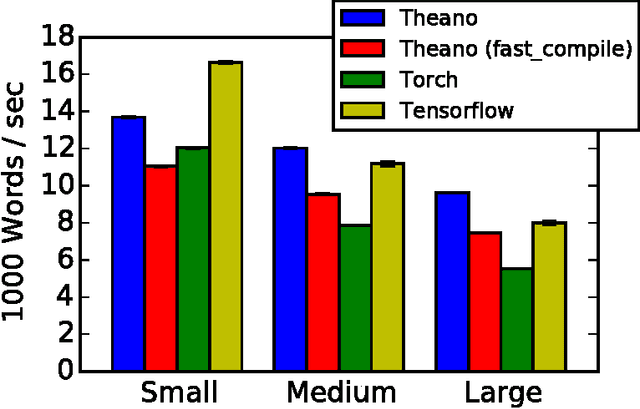
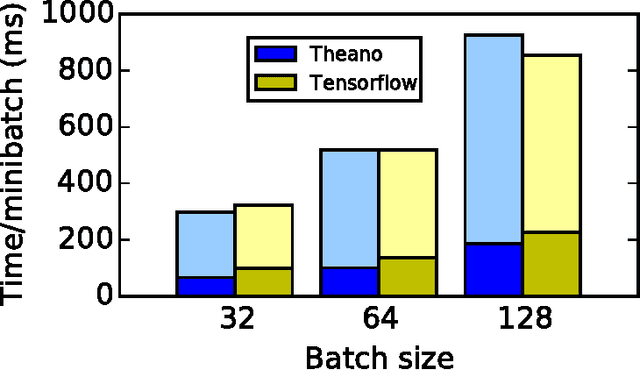
Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.