 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxelPrompt: A Vision-Language Agent for Grounded Medical Image Analysis
Paper and Code
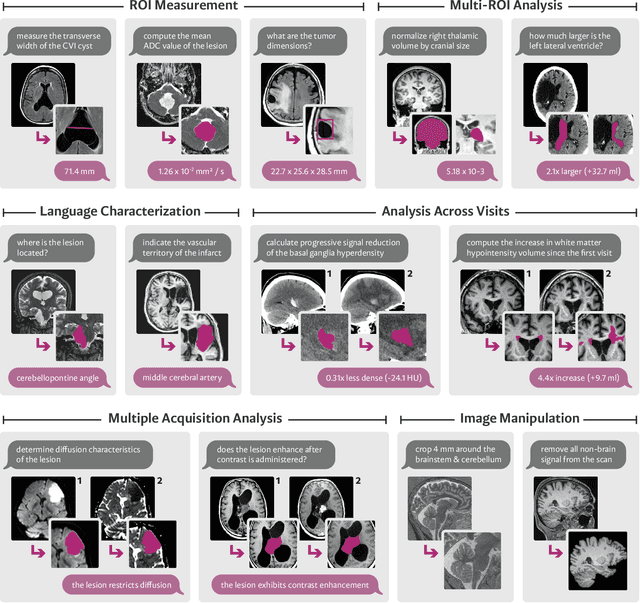
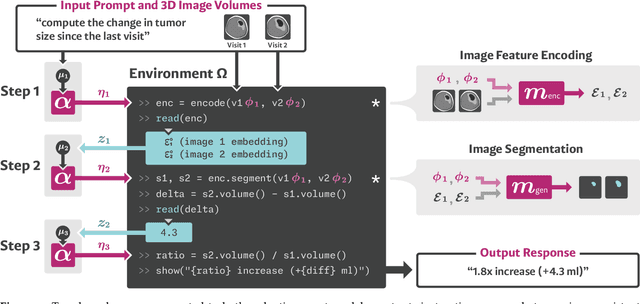
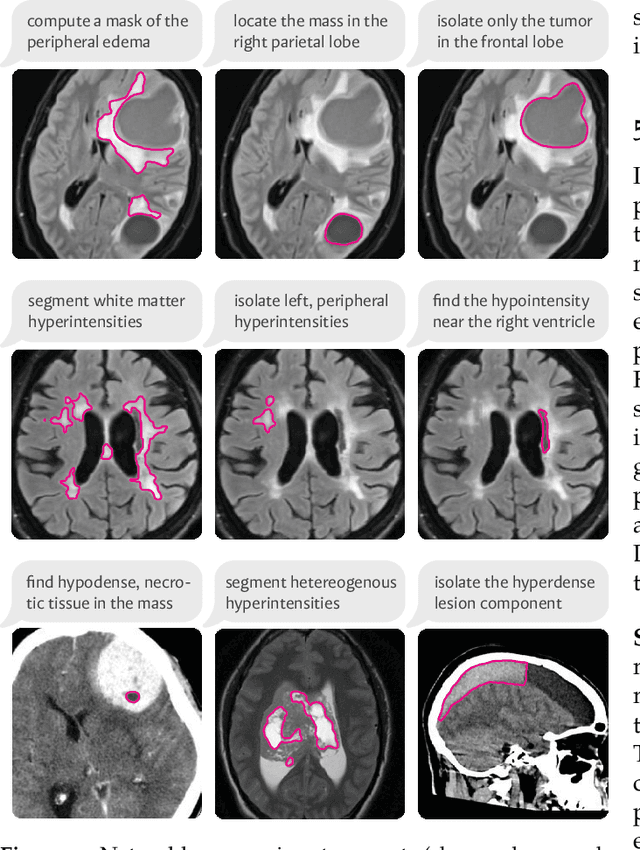
We present VoxelPrompt, an agent-driven vision-language framework that tackles diverse radiological tasks through joint modeling of natural language, image volumes, and analytical metrics. VoxelPrompt is multi-modal and versatile, leveraging the flexibility of language interaction while providing quantitatively grounded image analysis. Given a variable number of 3D medical volumes, such as MRI and CT scans, VoxelPrompt employs a language agent that iteratively predicts executable instructions to solve a task specified by an input prompt. These instructions communicate with a vision network to encode image features and generate volumetric outputs (e.g., segmentations). VoxelPrompt interprets the results of intermediate instructions and plans further actions to compute discrete measures (e.g., tumor growth across a series of scans) and present relevant outputs to the user. We evaluate this framework in a sandbox of diverse neuroimaging tasks, and we show that the single VoxelPrompt model can delineate hundreds of anatomical and pathological features, measure many complex morphological properties, and perform open-language analysis of lesion characteristics. VoxelPrompt carries out these objectives with accuracy similar to that of fine-tuned, single-task models for segmentation and visual question-answering, while facilitating a much larger range of tasks. Therefore, by supporting accurate image processing with language interaction, VoxelPrompt provides comprehensive utility for numerous imaging tasks that traditionally require specialized models to address.