 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGELDA: A generative language annotation framework to reveal visual biases in datasets
Nov 29, 2023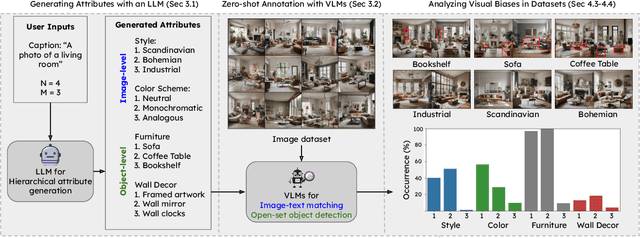

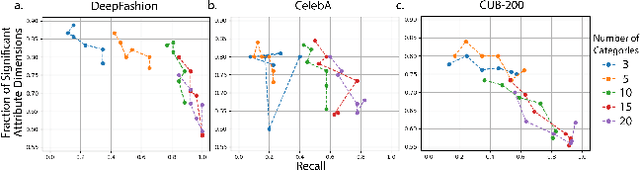

Bias analysis is a crucial step in the process of creating fair datasets for training and evaluating computer vision models. The bottleneck in dataset analysis is annotation, which typically requires: (1) specifying a list of attributes relevant to the dataset domain, and (2) classifying each image-attribute pair. While the second step has made rapid progress in automation, the first has remained human-centered, requiring an experimenter to compile lists of in-domain attributes. However, an experimenter may have limited foresight leading to annotation "blind spots," which in turn can lead to flawed downstream dataset analyses. To combat this, we propose GELDA, a nearly automatic framework that leverages large generative language models (LLMs) to propose and label various attributes for a domain. GELDA takes a user-defined domain caption (e.g., "a photo of a bird," "a photo of a living room") and uses an LLM to hierarchically generate attributes. In addition, GELDA uses the LLM to decide which of a set of vision-language models (VLMs) to use to classify each attribute in images. Results on real datasets show that GELDA can generate accurate and diverse visual attribute suggestions, and uncover biases such as confounding between class labels and background features. Results on synthetic datasets demonstrate that GELDA can be used to evaluate the biases of text-to-image diffusion models and generative adversarial networks. Overall, we show that while GELDA is not accurate enough to replace human annotators, it can serve as a complementary tool to help humans analyze datasets in a cheap, low-effort, and flexible manner.
GIST: Generating Image-Specific Text for Fine-grained Object Classification
Aug 04, 2023



Recent vision-language models outperform vision-only models on many image classification tasks. However, because of the absence of paired text/image descriptions, it remains difficult to fine-tune these models for fine-grained image classification. In this work, we propose a method, GIST, for generating image-specific fine-grained text descriptions from image-only datasets, and show that these text descriptions can be used to improve classification. Key parts of our method include 1. prompting a pretrained large language model with domain-specific prompts to generate diverse fine-grained text descriptions for each class and 2. using a pretrained vision-language model to match each image to label-preserving text descriptions that capture relevant visual features in the image. We demonstrate the utility of GIST by fine-tuning vision-language models on the image-and-generated-text pairs to learn an aligned vision-language representation space for improved classification. We evaluate our learned representation space in full-shot and few-shot scenarios across four diverse fine-grained classification datasets, each from a different domain. Our method achieves an average improvement of $4.1\%$ in accuracy over CLIP linear probes and an average of $1.1\%$ improvement in accuracy over the previous state-of-the-art image-text classification method on the full-shot datasets. Our method achieves similar improvements across few-shot regimes. Code is available at https://github.com/emu1729/GIST.
SizeGAN: Improving Size Representation in Clothing Catalogs
Nov 05, 2022
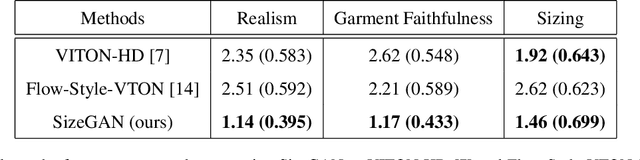
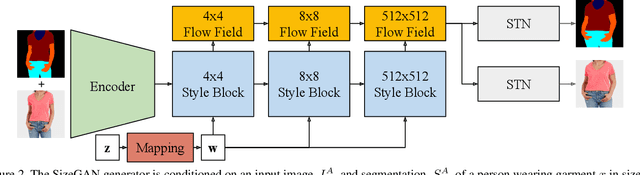

Online clothing catalogs lack diversity in body shape and garment size. Brands commonly display their garments on models of one or two sizes, rarely including plus-size models. In this work, we propose a new method, SizeGAN, for generating images of garments on different-sized models. To change the garment and model size while maintaining a photorealistic image, we incorporate image alignment ideas from the medical imaging literature into the StyleGAN2-ADA architecture. Our method learns deformation fields at multiple resolutions and uses a spatial transformer to modify the garment and model size. We evaluate our approach along three dimensions: realism, garment faithfulness, and size. To our knowledge, SizeGAN is the first method to focus on this size under-representation problem for modeling clothing. We provide an analysis comparing SizeGAN to other plausible approaches and additionally provide the first clothing dataset with size labels. In a user study comparing SizeGAN and two recent virtual try-on methods, we show that our method ranks first in each dimension, and was vastly preferred for realism and garment faithfulness. In comparison to most previous work, which has focused on generating photorealistic images of garments, our work shows that it is possible to generate images that are both photorealistic and cover diverse garment sizes.
Intuitively Assessing ML Model Reliability through Example-Based Explanations and Editing Model Inputs
Feb 17, 2021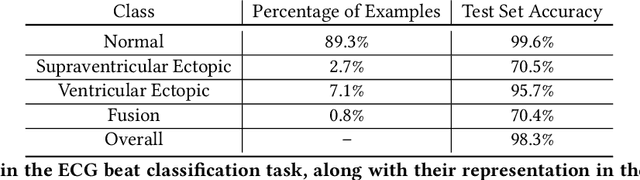
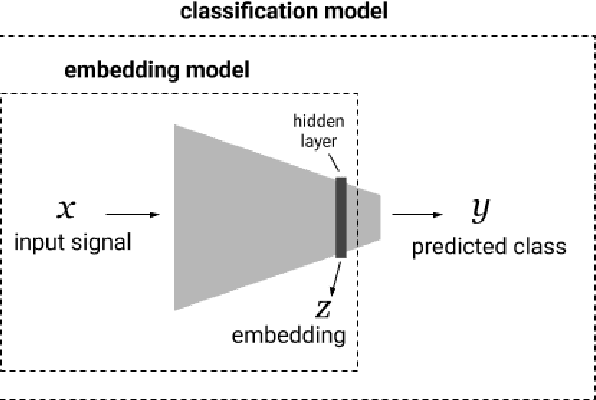
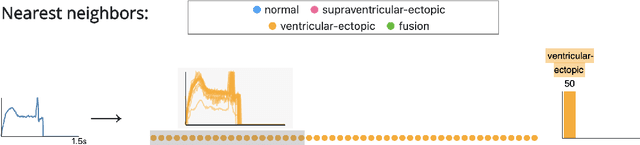
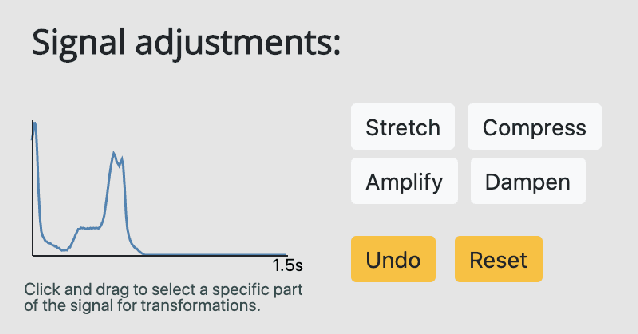
Interpretability methods aim to help users build trust in and understand the capabilities of machine learning models. However, existing approaches often rely on abstract, complex visualizations that poorly map to the task at hand or require non-trivial ML expertise to interpret. Here, we present two interface modules to facilitate a more intuitive assessment of model reliability. To help users better characterize and reason about a model's uncertainty, we visualize raw and aggregate information about a given input's nearest neighbors in the training dataset. Using an interactive editor, users can manipulate this input in semantically-meaningful ways, determine the effect on the output, and compare against their prior expectations. We evaluate our interface using an electrocardiogram beat classification case study. Compared to a baseline feature importance interface, we find that 9 physicians are better able to align the model's uncertainty with clinically relevant factors and build intuition about its capabilities and limitations.
Painting Many Pasts: Synthesizing Time Lapse Videos of Paintings
Jan 04, 2020
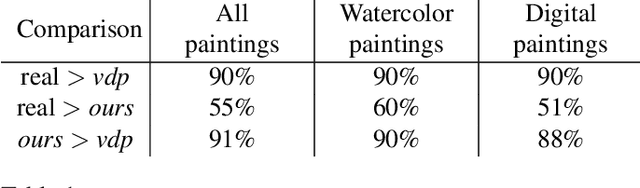
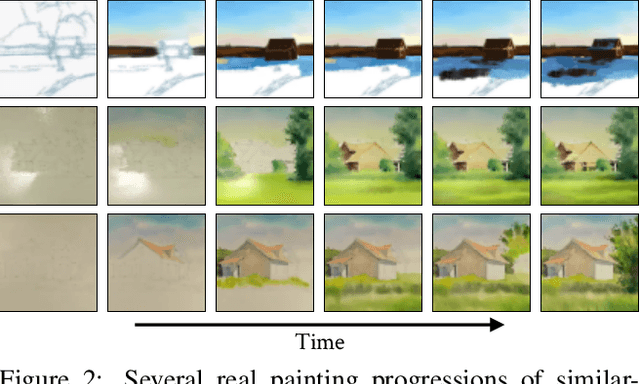
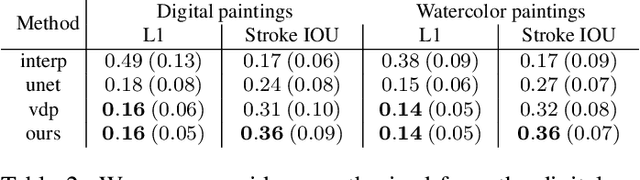
We introduce a new video synthesis task: synthesizing time lapse videos depicting how a given painting might have been created. Artists paint using unique combinations of brushes, strokes, colors, and layers. There are often many possible ways to create a given painting. Our goal is to learn to capture this rich range of possibilities. Creating distributions of long-term videos is a challenge for learning-based video synthesis methods. We present a probabilistic model that, given a single image of a completed painting, recurrently synthesizes steps of the painting process. We implement this model as a convolutional neural network, and introduce a training scheme to facilitate learning from a limited dataset of painting time lapses. We demonstrate that this model can be used to sample many time steps, enabling long-term stochastic video synthesis. We evaluate our method on digital and watercolor paintings collected from video websites, and show that human raters find our synthesized videos to be similar to time lapses produced by real artists.
Fast Learning-based Registration of Sparse Clinical Images
Dec 17, 2018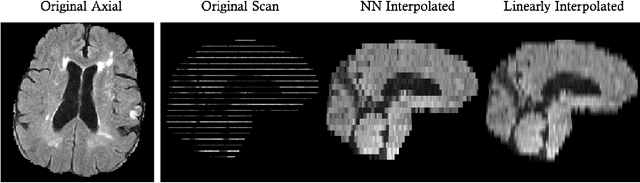

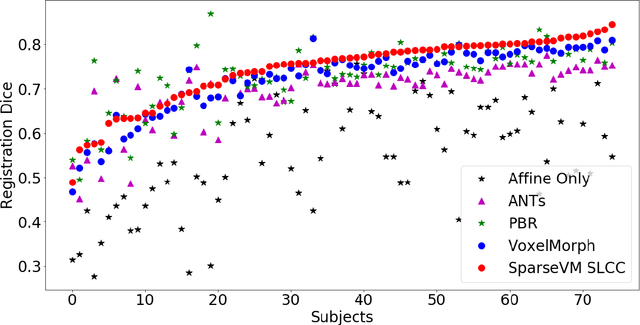
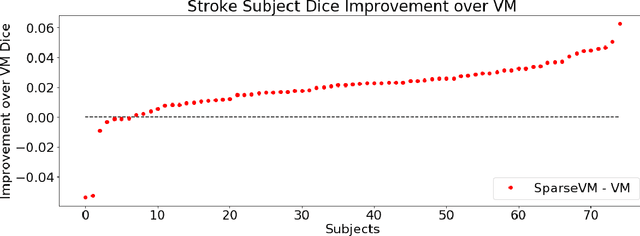
Deformable registration of clinical scans is a fundamental task for many applications, such as population studies or the monitoring of long-term disease progression in individual patients. This task is challenging because, in contrast to high-resolution research-quality scans, clinical images are often sparse, missing up to 85% of the slices in comparison. Furthermore, the anatomy in the acquired slices is not consistent across scans because of variations in patient orientation with respect to the scanner. In this work, we introduce Sparse VoxelMorph (SparseVM), which adapts a state-of-the-art learning-based registration method to improve the registration of sparse clinical images. SparseVM is a fast, unsupervised method that weights voxel contributions to registration in proportion to confidence in the voxels. This leads to improved registration performance on volumes with voxels of varying reliability, such as interpolated clinical scans. SparseVM registers 3D scans in under a second on the GPU, which is orders of magnitudes faster than the best performing clinical registration methods, while still achieving comparable accuracy. Because of its short runtimes and accurate behavior, SparseVM can enable clinical analyses not previously possible. The code is publicly available at voxelmorph.mit.edu.