 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGELDA: A generative language annotation framework to reveal visual biases in datasets
Nov 29, 2023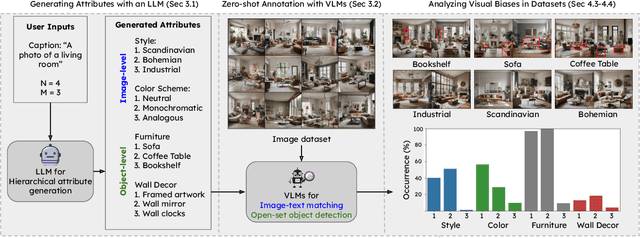

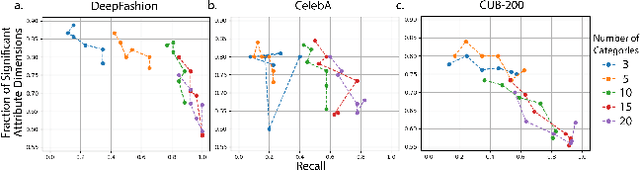

Bias analysis is a crucial step in the process of creating fair datasets for training and evaluating computer vision models. The bottleneck in dataset analysis is annotation, which typically requires: (1) specifying a list of attributes relevant to the dataset domain, and (2) classifying each image-attribute pair. While the second step has made rapid progress in automation, the first has remained human-centered, requiring an experimenter to compile lists of in-domain attributes. However, an experimenter may have limited foresight leading to annotation "blind spots," which in turn can lead to flawed downstream dataset analyses. To combat this, we propose GELDA, a nearly automatic framework that leverages large generative language models (LLMs) to propose and label various attributes for a domain. GELDA takes a user-defined domain caption (e.g., "a photo of a bird," "a photo of a living room") and uses an LLM to hierarchically generate attributes. In addition, GELDA uses the LLM to decide which of a set of vision-language models (VLMs) to use to classify each attribute in images. Results on real datasets show that GELDA can generate accurate and diverse visual attribute suggestions, and uncover biases such as confounding between class labels and background features. Results on synthetic datasets demonstrate that GELDA can be used to evaluate the biases of text-to-image diffusion models and generative adversarial networks. Overall, we show that while GELDA is not accurate enough to replace human annotators, it can serve as a complementary tool to help humans analyze datasets in a cheap, low-effort, and flexible manner.
F?D: On understanding the role of deep feature spaces on face generation evaluation
Jun 01, 2023



Perceptual metrics, like the Fr\'echet Inception Distance (FID), are widely used to assess the similarity between synthetically generated and ground truth (real) images. The key idea behind these metrics is to compute errors in a deep feature space that captures perceptually and semantically rich image features. Despite their popularity, the effect that different deep features and their design choices have on a perceptual metric has not been well studied. In this work, we perform a causal analysis linking differences in semantic attributes and distortions between face image distributions to Fr\'echet distances (FD) using several popular deep feature spaces. A key component of our analysis is the creation of synthetic counterfactual faces using deep face generators. Our experiments show that the FD is heavily influenced by its feature space's training dataset and objective function. For example, FD using features extracted from ImageNet-trained models heavily emphasize hats over regions like the eyes and mouth. Moreover, FD using features from a face gender classifier emphasize hair length more than distances in an identity (recognition) feature space. Finally, we evaluate several popular face generation models across feature spaces and find that StyleGAN2 consistently ranks higher than other face generators, except with respect to identity (recognition) features. This suggests the need for considering multiple feature spaces when evaluating generative models and using feature spaces that are tuned to nuances of the domain of interest.
Deep object detection for waterbird monitoring using aerial imagery
Oct 10, 2022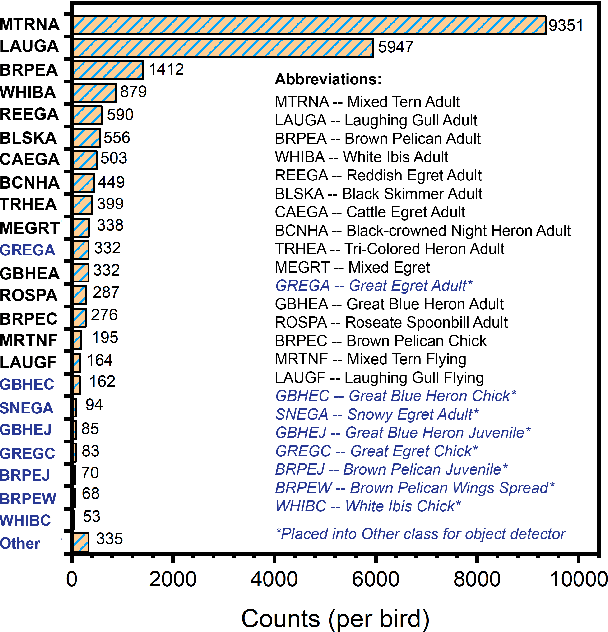
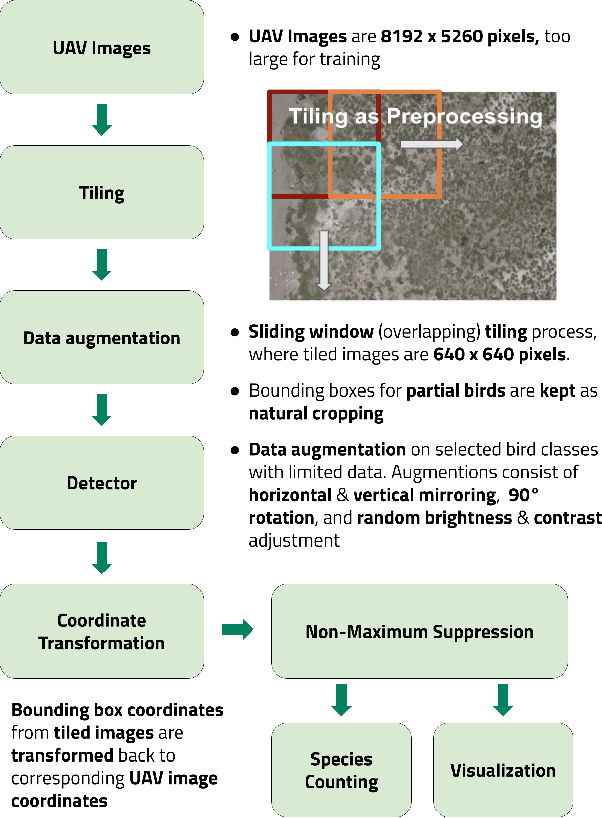
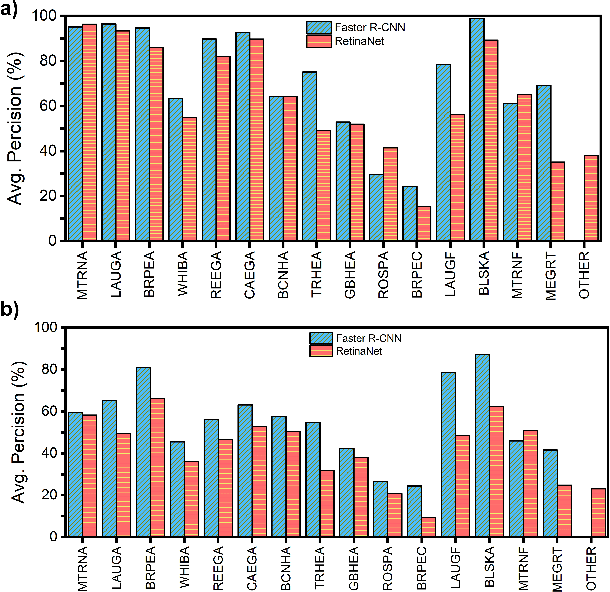
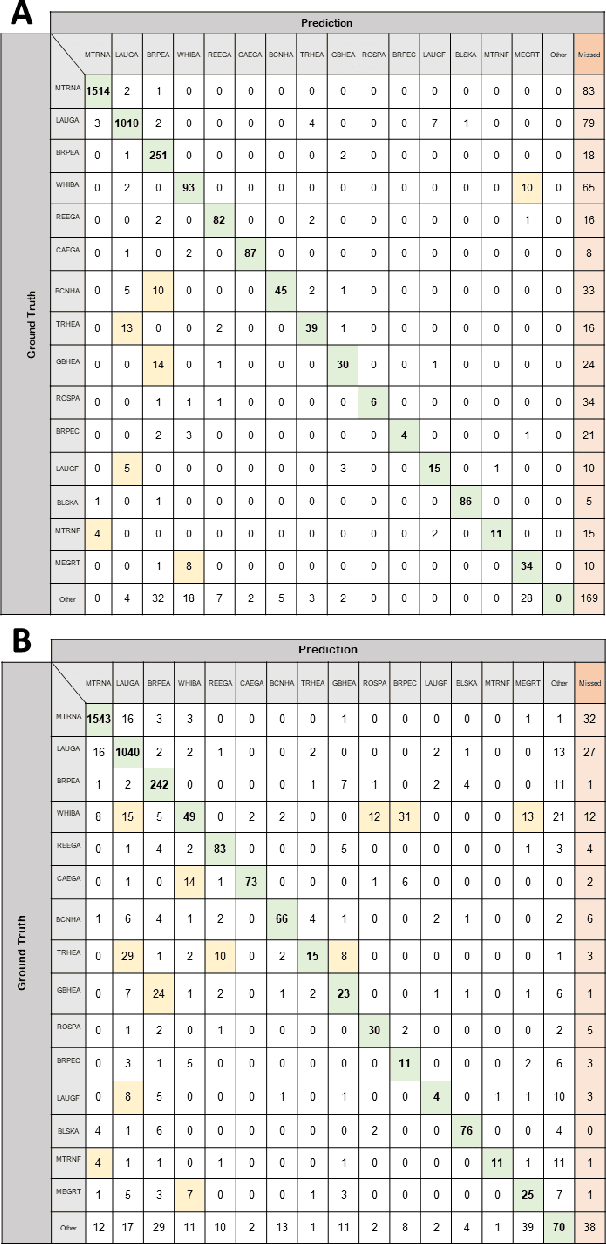
Monitoring of colonial waterbird nesting islands is essential to tracking waterbird population trends, which are used for evaluating ecosystem health and informing conservation management decisions. Recently, unmanned aerial vehicles, or drones, have emerged as a viable technology to precisely monitor waterbird colonies. However, manually counting waterbirds from hundreds, or potentially thousands, of aerial images is both difficult and time-consuming. In this work, we present a deep learning pipeline that can be used to precisely detect, count, and monitor waterbirds using aerial imagery collected by a commercial drone. By utilizing convolutional neural network-based object detectors, we show that we can detect 16 classes of waterbird species that are commonly found in colonial nesting islands along the Texas coast. Our experiments using Faster R-CNN and RetinaNet object detectors give mean interpolated average precision scores of 67.9% and 63.1% respectively.