 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny but Trusted: Efficient Vision-Language Reasoning for Time-Series Anomaly Detection
May 28, 2026Recent advances in Vision-Language Models (VLMs) have achieved impressive performance across many tasks, yet prior studies report unsatisfactory performance when applying large language or multimodal models to finding abnormal patterns in sequential data. Public anomaly detection benchmarks typically provide interval annotations but not natural-language rationales, making it difficult to fine-tune VLMs to produce grounded, interpretable decisions. To address this gap, we construct VisAnomBench, a curated benchmark built from public time-series datasets and augmented with high-quality anomaly explanations selected from multiple large VLMs using fine-grained, task-specific rewards. Through fine-tuning on this benchmark, we develop VisAnomReasoner, a parameter-efficient VLM for time-series anomaly detection. Experimental results on VisAnomBench show that VisAnomReasoner achieves more accurate anomaly localization and consistently outperforms all baselines, with improvements of at least 21.23 and 23.87 percentage points in precision and F1, respectively. Additional experiments on the TSB-AD-U benchmark demonstrate strong cross-benchmark generalization, with VisAnomReasoner improving precision and F1 by 9.57 and 13.39 percentage points, respectively.
Phantom: Physics-Infused Video Generation via Joint Modeling of Visual and Latent Physical Dynamics
Apr 09, 2026Recent advances in generative video modeling, driven by large-scale datasets and powerful architectures, have yielded remarkable visual realism. However, emerging evidence suggests that simply scaling data and model size does not endow these systems with an understanding of the underlying physical laws that govern real-world dynamics. Existing approaches often fail to capture or enforce such physical consistency, resulting in unrealistic motion and dynamics. In his work, we investigate whether integrating the inference of latent physical properties directly into the video generation process can equip models with the ability to produce physically plausible videos. To this end, we propose Phantom, a Physics-Infused Video Generation model that jointly models the visual content and latent physical dynamics. Conditioned on observed video frames and inferred physical states, Phantom jointly predicts latent physical dynamics and generates future video frames. Phantom leverages a physics-aware video representation that serves as an abstract yet informaive embedding of the underlying physics, facilitating the joint prediction of physical dynamics alongside video content without requiring an explicit specification of a complex set of physical dynamics and properties. By integrating the inference of physical-aware video representation directly into the video generation process, Phantom produces video sequences that are both visually realistic and physically consistent. Quantitative and qualitative results on both standard video generation and physics-aware benchmarks demonstrate that Phantom not only outperforms existing methods in terms of adherence to physical dynamics but also delivers competitive perceptual fidelity.
EgoForge: Goal-Directed Egocentric World Simulator
Mar 20, 2026Generative world models have shown promise for simulating dynamic environments, yet egocentric video remains challenging due to rapid viewpoint changes, frequent hand-object interactions, and goal-directed procedures whose evolution depends on latent human intent. Existing approaches either focus on hand-centric instructional synthesis with limited scene evolution, perform static view translation without modeling action dynamics, or rely on dense supervision, such as camera trajectories, long video prefixes, synchronized multicamera capture, etc. In this work, we introduce EgoForge, an egocentric goal-directed world simulator that generates coherent, first-person video rollouts from minimal static inputs: a single egocentric image, a high-level instruction, and an optional auxiliary exocentric view. To improve intent alignment and temporal consistency, we propose VideoDiffusionNFT, a trajectory-level reward-guided refinement that optimizes goal completion, temporal causality, scene consistency, and perceptual fidelity during diffusion sampling. Extensive experiments show EgoForge achieves consistent gains in semantic alignment, geometric stability, and motion fidelity over strong baselines, and robust performance in real-world smart-glasses experiments.
DreamPartGen: Semantically Grounded Part-Level 3D Generation via Collaborative Latent Denoising
Mar 19, 2026Understanding and generating 3D objects as compositions of meaningful parts is fundamental to human perception and reasoning. However, most text-to-3D methods overlook the semantic and functional structure of parts. While recent part-aware approaches introduce decomposition, they remain largely geometry-focused, lacking semantic grounding and failing to model how parts align with textual descriptions or their inter-part relations. We propose DreamPartGen, a framework for semantically grounded, part-aware text-to-3D generation. DreamPartGen introduces Duplex Part Latents (DPLs) that jointly model each part's geometry and appearance, and Relational Semantic Latents (RSLs) that capture inter-part dependencies derived from language. A synchronized co-denoising process enforces mutual geometric and semantic consistency, enabling coherent, interpretable, and text-aligned 3D synthesis. Across multiple benchmarks, DreamPartGen delivers state-of-the-art performance in geometric fidelity and text-shape alignment.
PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
Jan 11, 2026Recent advancements in vision-language-action (VLA) models have shown promise in robotic manipulation, yet they continue to struggle with long-horizon, multi-step tasks. Existing methods lack internal reasoning mechanisms that can identify task-relevant interaction cues or track progress within a subtask, leading to critical execution errors such as repeated actions, missed steps, and premature termination. To address these challenges, we introduce PALM, a VLA framework that structures policy learning around interaction-centric affordance reasoning and subtask progress cues. PALM distills complementary affordance representations that capture object relevance, contact geometry, spatial placements, and motion dynamics, and serve as task-relevant anchors for visuomotor control. To further stabilize long-horizon execution, PALM predicts continuous within-subtask progress, enabling seamless subtask transitions. Across extensive simulation and real-world experiments, PALM consistently outperforms baselines, achieving a 91.8% success rate on LIBERO-LONG, a 12.5% improvement in average length on CALVIN ABC->D, and a 2x improvement over real-world baselines across three long-horizon generalization settings.
CoRe3D: Collaborative Reasoning as a Foundation for 3D Intelligence
Dec 14, 2025Recent advances in large multimodal models suggest that explicit reasoning mechanisms play a critical role in improving model reliability, interpretability, and cross-modal alignment. While such reasoning-centric approaches have been proven effective in language and vision tasks, their extension to 3D remains underdeveloped. CoRe3D introduces a unified 3D understanding and generation reasoning framework that jointly operates over semantic and spatial abstractions, enabling high-level intent inferred from language to directly guide low-level 3D content formation. Central to this design is a spatially grounded reasoning representation that decomposes 3D latent space into localized regions, allowing the model to reason over geometry in a compositional and procedural manner. By tightly coupling semantic chain-of-thought inference with structured spatial reasoning, CoRe3D produces 3D outputs that exhibit strong local consistency and faithful alignment with linguistic descriptions.
Uncertainty in Action: Confidence Elicitation in Embodied Agents
Mar 13, 2025Expressing confidence is challenging for embodied agents navigating dynamic multimodal environments, where uncertainty arises from both perception and decision-making processes. We present the first work investigating embodied confidence elicitation in open-ended multimodal environments. We introduce Elicitation Policies, which structure confidence assessment across inductive, deductive, and abductive reasoning, along with Execution Policies, which enhance confidence calibration through scenario reinterpretation, action sampling, and hypothetical reasoning. Evaluating agents in calibration and failure prediction tasks within the Minecraft environment, we show that structured reasoning approaches, such as Chain-of-Thoughts, improve confidence calibration. However, our findings also reveal persistent challenges in distinguishing uncertainty, particularly under abductive settings, underscoring the need for more sophisticated embodied confidence elicitation methods.
CALICO: Part-Focused Semantic Co-Segmentation with Large Vision-Language Models
Dec 26, 2024Recent advances in Large Vision-Language Models (LVLMs) have sparked significant progress in general-purpose vision tasks through visual instruction tuning. While some works have demonstrated the capability of LVLMs to generate segmentation masks that align phrases with natural language descriptions in a single image, they struggle with segmentation-grounded comparisons across multiple images, particularly at finer granularities such as object parts. In this paper, we introduce the new task of part-focused semantic co-segmentation, which seeks to identify and segment common and unique objects and parts across images. To address this task, we present CALICO, the first LVLM that can segment and reason over multiple masks across images, enabling object comparison based on their constituent parts. CALICO features two proposed components, a novel Correspondence Extraction Module, which captures semantic-rich information to identify part-level correspondences between objects, and a Correspondence Adaptation Module, which embeds this information into the LVLM to facilitate multi-image understanding in a parameter-efficient manner. To support training and evaluation, we curate MixedParts, a comprehensive multi-image segmentation dataset containing $\sim$2.4M samples across $\sim$44K images with diverse object and part categories. Experimental results show CALICO, finetuned on only 0.3% of its architecture, achieves robust performance in part-focused semantic co-segmentation.
PRIMA: Multi-Image Vision-Language Models for Reasoning Segmentation
Dec 19, 2024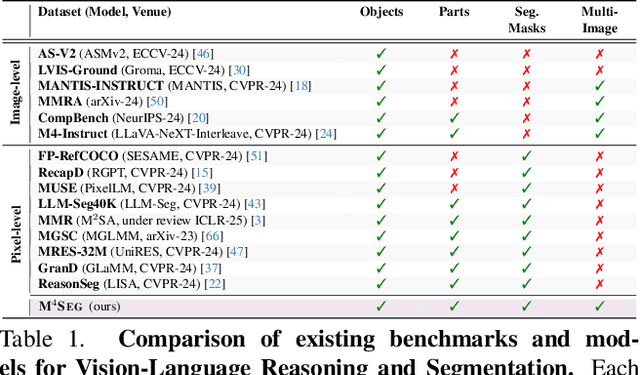
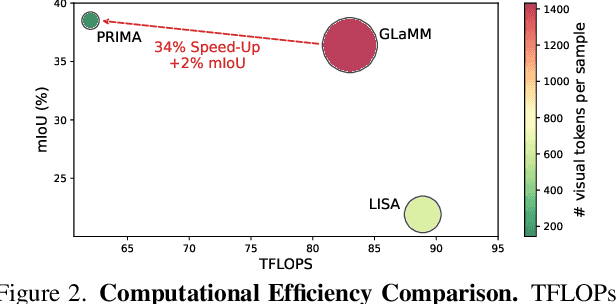
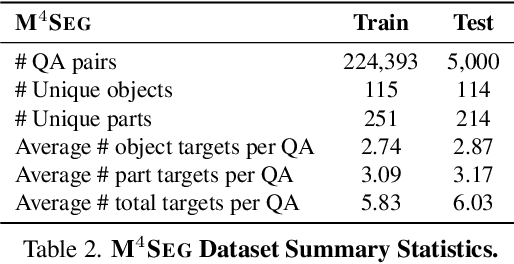
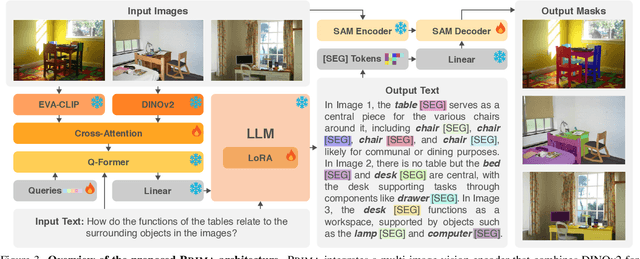
Despite significant advancements in Large Vision-Language Models (LVLMs), existing pixel-grounding models operate on single-image settings, limiting their ability to perform detailed, fine-grained comparisons across multiple images. Conversely, current multi-image understanding models lack pixel-level grounding. Our work addresses this gap by introducing the task of multi-image pixel-grounded reasoning segmentation, and PRIMA, a novel LVLM that integrates pixel-level grounding with robust multi-image reasoning capabilities to produce contextually rich, pixel-grounded explanations. Central to PRIMA is an efficient vision module that queries fine-grained visual representations across multiple images, reducing TFLOPs by $25.3\%$. To support training and evaluation, we curate $M^4Seg$, a new reasoning segmentation benchmark consisting of $\sim$224K question-answer pairs that require fine-grained visual understanding across multiple images. Experimental results demonstrate PRIMA outperforms state-of-the-art baselines.
Sedition Hunters: A Quantitative Study of the Crowdsourced Investigation into the 2021 U.S. Capitol Attack
Feb 21, 2023



Social media platforms have enabled extremists to organize violent events, such as the 2021 U.S. Capitol Attack. Simultaneously, these platforms enable professional investigators and amateur sleuths to collaboratively collect and identify imagery of suspects with the goal of holding them accountable for their actions. Through a case study of Sedition Hunters, a Twitter community whose goal is to identify individuals who participated in the 2021 U.S. Capitol Attack, we explore what are the main topics or targets of the community, who participates in the community, and how. Using topic modeling, we find that information sharing is the main focus of the community. We also note an increase in awareness of privacy concerns. Furthermore, using social network analysis, we show how some participants played important roles in the community. Finally, we discuss implications for the content and structure of online crowdsourced investigations.