 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny but Trusted: Efficient Vision-Language Reasoning for Time-Series Anomaly Detection
May 28, 2026Recent advances in Vision-Language Models (VLMs) have achieved impressive performance across many tasks, yet prior studies report unsatisfactory performance when applying large language or multimodal models to finding abnormal patterns in sequential data. Public anomaly detection benchmarks typically provide interval annotations but not natural-language rationales, making it difficult to fine-tune VLMs to produce grounded, interpretable decisions. To address this gap, we construct VisAnomBench, a curated benchmark built from public time-series datasets and augmented with high-quality anomaly explanations selected from multiple large VLMs using fine-grained, task-specific rewards. Through fine-tuning on this benchmark, we develop VisAnomReasoner, a parameter-efficient VLM for time-series anomaly detection. Experimental results on VisAnomBench show that VisAnomReasoner achieves more accurate anomaly localization and consistently outperforms all baselines, with improvements of at least 21.23 and 23.87 percentage points in precision and F1, respectively. Additional experiments on the TSB-AD-U benchmark demonstrate strong cross-benchmark generalization, with VisAnomReasoner improving precision and F1 by 9.57 and 13.39 percentage points, respectively.
RewardFlow: Generate Images by Optimizing What You Reward
Apr 09, 2026We introduce RewardFlow, an inversion-free framework that steers pretrained diffusion and flow-matching models at inference time through multi-reward Langevin dynamics. RewardFlow unifies complementary differentiable rewards for semantic alignment, perceptual fidelity, localized grounding, object consistency, and human preference, and further introduces a differentiable VQA-based reward that provides fine-grained semantic supervision through language-vision reasoning. To coordinate these heterogeneous objectives, we design a prompt-aware adaptive policy that extracts semantic primitives from the instruction, infers edit intent, and dynamically modulates reward weights and step sizes throughout sampling. Across several image editing and compositional generation benchmarks, RewardFlow delivers state-of-the-art edit fidelity and compositional alignment.
DreamPartGen: Semantically Grounded Part-Level 3D Generation via Collaborative Latent Denoising
Mar 19, 2026Understanding and generating 3D objects as compositions of meaningful parts is fundamental to human perception and reasoning. However, most text-to-3D methods overlook the semantic and functional structure of parts. While recent part-aware approaches introduce decomposition, they remain largely geometry-focused, lacking semantic grounding and failing to model how parts align with textual descriptions or their inter-part relations. We propose DreamPartGen, a framework for semantically grounded, part-aware text-to-3D generation. DreamPartGen introduces Duplex Part Latents (DPLs) that jointly model each part's geometry and appearance, and Relational Semantic Latents (RSLs) that capture inter-part dependencies derived from language. A synchronized co-denoising process enforces mutual geometric and semantic consistency, enabling coherent, interpretable, and text-aligned 3D synthesis. Across multiple benchmarks, DreamPartGen delivers state-of-the-art performance in geometric fidelity and text-shape alignment.
BAPPA: Benchmarking Agents, Plans, and Pipelines for Automated Text-to-SQL Generation
Nov 06, 2025



Text-to-SQL systems provide a natural language interface that can enable even laymen to access information stored in databases. However, existing Large Language Models (LLM) struggle with SQL generation from natural instructions due to large schema sizes and complex reasoning. Prior work often focuses on complex, somewhat impractical pipelines using flagship models, while smaller, efficient models remain overlooked. In this work, we explore three multi-agent LLM pipelines, with systematic performance benchmarking across a range of small to large open-source models: (1) Multi-agent discussion pipeline, where agents iteratively critique and refine SQL queries, and a judge synthesizes the final answer; (2) Planner-Coder pipeline, where a thinking model planner generates stepwise SQL generation plans and a coder synthesizes queries; and (3) Coder-Aggregator pipeline, where multiple coders independently generate SQL queries, and a reasoning agent selects the best query. Experiments on the Bird-Bench Mini-Dev set reveal that Multi-Agent discussion can improve small model performance, with up to 10.6% increase in Execution Accuracy for Qwen2.5-7b-Instruct seen after three rounds of discussion. Among the pipelines, the LLM Reasoner-Coder pipeline yields the best results, with DeepSeek-R1-32B and QwQ-32B planners boosting Gemma 3 27B IT accuracy from 52.4% to the highest score of 56.4%. Codes are available at https://github.com/treeDweller98/bappa-sql.
HalluSegBench: Counterfactual Visual Reasoning for Segmentation Hallucination Evaluation
Jun 26, 2025Recent progress in vision-language segmentation has significantly advanced grounded visual understanding. However, these models often exhibit hallucinations by producing segmentation masks for objects not grounded in the image content or by incorrectly labeling irrelevant regions. Existing evaluation protocols for segmentation hallucination primarily focus on label or textual hallucinations without manipulating the visual context, limiting their capacity to diagnose critical failures. In response, we introduce HalluSegBench, the first benchmark specifically designed to evaluate hallucinations in visual grounding through the lens of counterfactual visual reasoning. Our benchmark consists of a novel dataset of 1340 counterfactual instance pairs spanning 281 unique object classes, and a set of newly introduced metrics that quantify hallucination sensitivity under visually coherent scene edits. Experiments on HalluSegBench with state-of-the-art vision-language segmentation models reveal that vision-driven hallucinations are significantly more prevalent than label-driven ones, with models often persisting in false segmentation, highlighting the need for counterfactual reasoning to diagnose grounding fidelity.
Uncertainty in Action: Confidence Elicitation in Embodied Agents
Mar 13, 2025Expressing confidence is challenging for embodied agents navigating dynamic multimodal environments, where uncertainty arises from both perception and decision-making processes. We present the first work investigating embodied confidence elicitation in open-ended multimodal environments. We introduce Elicitation Policies, which structure confidence assessment across inductive, deductive, and abductive reasoning, along with Execution Policies, which enhance confidence calibration through scenario reinterpretation, action sampling, and hypothetical reasoning. Evaluating agents in calibration and failure prediction tasks within the Minecraft environment, we show that structured reasoning approaches, such as Chain-of-Thoughts, improve confidence calibration. However, our findings also reveal persistent challenges in distinguishing uncertainty, particularly under abductive settings, underscoring the need for more sophisticated embodied confidence elicitation methods.
CALICO: Part-Focused Semantic Co-Segmentation with Large Vision-Language Models
Dec 26, 2024Recent advances in Large Vision-Language Models (LVLMs) have sparked significant progress in general-purpose vision tasks through visual instruction tuning. While some works have demonstrated the capability of LVLMs to generate segmentation masks that align phrases with natural language descriptions in a single image, they struggle with segmentation-grounded comparisons across multiple images, particularly at finer granularities such as object parts. In this paper, we introduce the new task of part-focused semantic co-segmentation, which seeks to identify and segment common and unique objects and parts across images. To address this task, we present CALICO, the first LVLM that can segment and reason over multiple masks across images, enabling object comparison based on their constituent parts. CALICO features two proposed components, a novel Correspondence Extraction Module, which captures semantic-rich information to identify part-level correspondences between objects, and a Correspondence Adaptation Module, which embeds this information into the LVLM to facilitate multi-image understanding in a parameter-efficient manner. To support training and evaluation, we curate MixedParts, a comprehensive multi-image segmentation dataset containing $\sim$2.4M samples across $\sim$44K images with diverse object and part categories. Experimental results show CALICO, finetuned on only 0.3% of its architecture, achieves robust performance in part-focused semantic co-segmentation.
PRIMA: Multi-Image Vision-Language Models for Reasoning Segmentation
Dec 19, 2024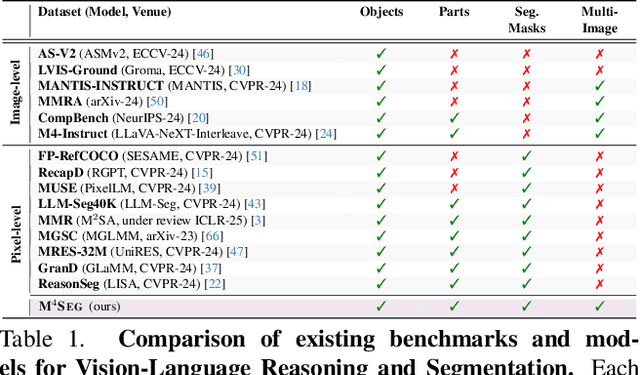
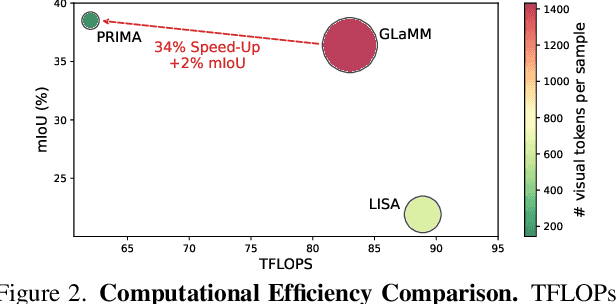
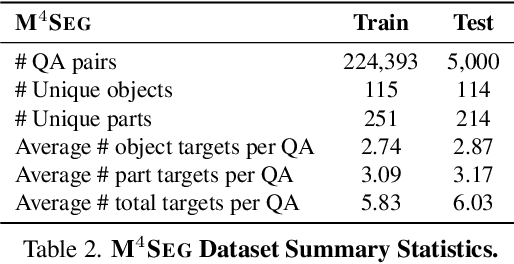
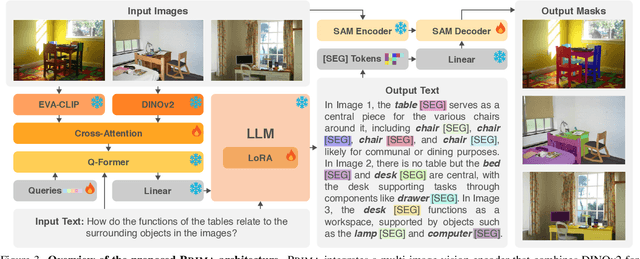
Despite significant advancements in Large Vision-Language Models (LVLMs), existing pixel-grounding models operate on single-image settings, limiting their ability to perform detailed, fine-grained comparisons across multiple images. Conversely, current multi-image understanding models lack pixel-level grounding. Our work addresses this gap by introducing the task of multi-image pixel-grounded reasoning segmentation, and PRIMA, a novel LVLM that integrates pixel-level grounding with robust multi-image reasoning capabilities to produce contextually rich, pixel-grounded explanations. Central to PRIMA is an efficient vision module that queries fine-grained visual representations across multiple images, reducing TFLOPs by $25.3\%$. To support training and evaluation, we curate $M^4Seg$, a new reasoning segmentation benchmark consisting of $\sim$224K question-answer pairs that require fine-grained visual understanding across multiple images. Experimental results demonstrate PRIMA outperforms state-of-the-art baselines.
Hard Negative Sampling Strategies for Contrastive Representation Learning
Jun 02, 2022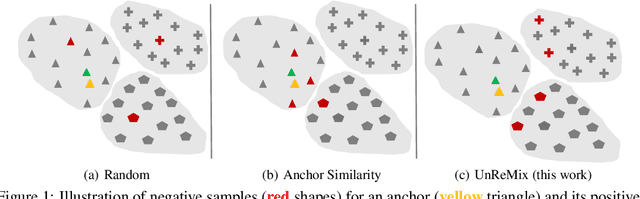
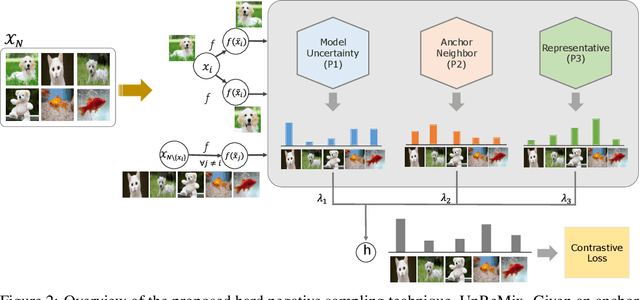
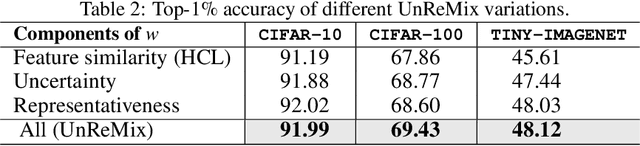

One of the challenges in contrastive learning is the selection of appropriate \textit{hard negative} examples, in the absence of label information. Random sampling or importance sampling methods based on feature similarity often lead to sub-optimal performance. In this work, we introduce UnReMix, a hard negative sampling strategy that takes into account anchor similarity, model uncertainty and representativeness. Experimental results on several benchmarks show that UnReMix improves negative sample selection, and subsequently downstream performance when compared to state-of-the-art contrastive learning methods.
Adversarial Contrastive Learning by Permuting Cluster Assignments
Apr 21, 2022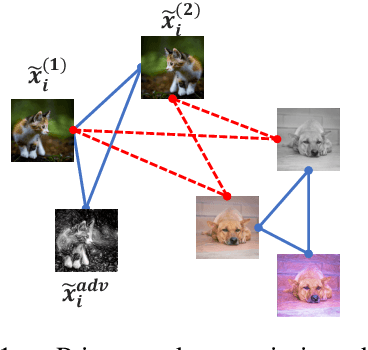
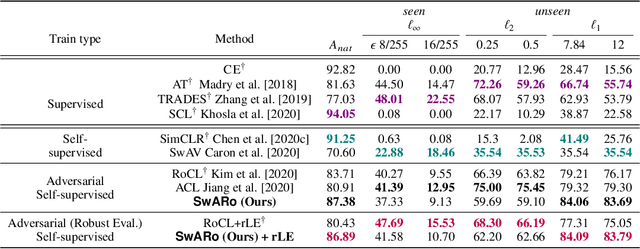
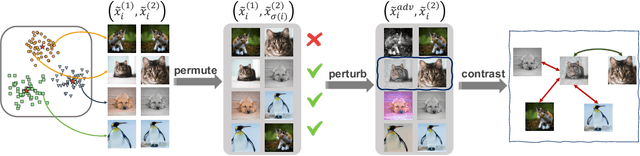
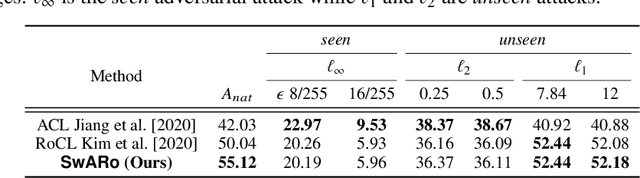
Contrastive learning has gained popularity as an effective self-supervised representation learning technique. Several research directions improve traditional contrastive approaches, e.g., prototypical contrastive methods better capture the semantic similarity among instances and reduce the computational burden by considering cluster prototypes or cluster assignments, while adversarial instance-wise contrastive methods improve robustness against a variety of attacks. To the best of our knowledge, no prior work jointly considers robustness, cluster-wise semantic similarity and computational efficiency. In this work, we propose SwARo, an adversarial contrastive framework that incorporates cluster assignment permutations to generate representative adversarial samples. We evaluate SwARo on multiple benchmark datasets and against various white-box and black-box attacks, obtaining consistent improvements over state-of-the-art baselines.