 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAUCE: Truncated Sparse Document Signature Bit-Vectors for Fast Web-Scale Corpus Expansion
Aug 26, 2021

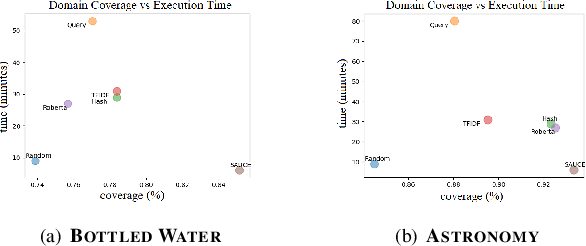
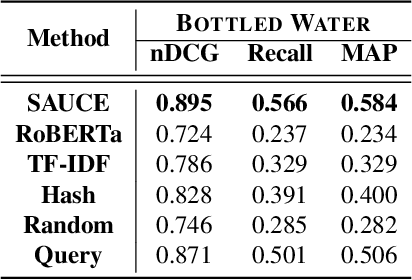
Recent advances in text representation have shown that training on large amounts of text is crucial for natural language understanding. However, models trained without predefined notions of topical interest typically require careful fine-tuning when transferred to specialized domains. When a sufficient amount of within-domain text may not be available, expanding a seed corpus of relevant documents from large-scale web data poses several challenges. First, corpus expansion requires scoring and ranking each document in the collection, an operation that can quickly become computationally expensive as the web corpora size grows. Relying on dense vector spaces and pairwise similarity adds to the computational expense. Secondly, as the domain concept becomes more nuanced, capturing the long tail of domain-specific rare terms becomes non-trivial, especially under limited seed corpora scenarios. In this paper, we consider the problem of fast approximate corpus expansion given a small seed corpus with a few relevant documents as a query, with the goal of capturing the long tail of a domain-specific set of concept terms. To efficiently collect large-scale domain-specific corpora with limited relevance feedback, we propose a novel truncated sparse document bit-vector representation, termed Signature Assisted Unsupervised Corpus Expansion (SAUCE). Experimental results show that SAUCE can reduce the computational burden while ensuring high within-domain lexical coverage.