 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Driven Generative Completion of Lacunae in Molecular Data
Jul 29, 2022


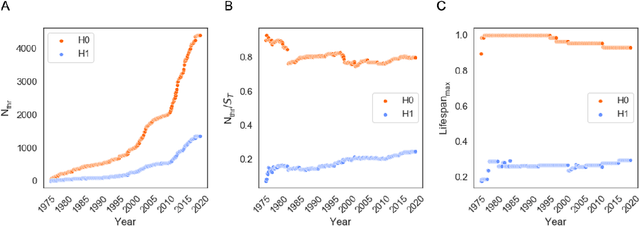
We introduce an approach to the targeted completion of lacunae in molecular data sets which is driven by topological data analysis, such as Mapper algorithm. Lacunae are filled in using scaffold-constrained generative models trained with different scoring functions. The approach enables addition of links and vertices to the skeletonized representations of the data, such as Mapper graph, and falls in the broad category of network completion methods. We illustrate application of the topology-driven data completion strategy by creating a lacuna in the data set of onium cations extracted from USPTO patents, and repairing it.
SAUCE: Truncated Sparse Document Signature Bit-Vectors for Fast Web-Scale Corpus Expansion
Aug 26, 2021

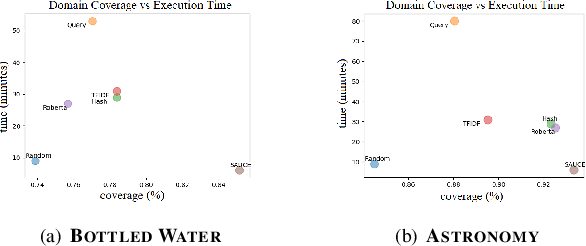
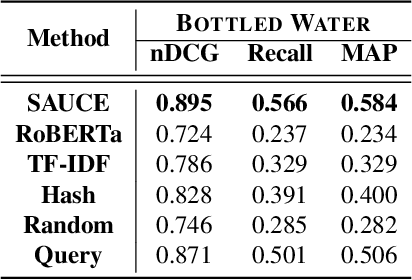
Recent advances in text representation have shown that training on large amounts of text is crucial for natural language understanding. However, models trained without predefined notions of topical interest typically require careful fine-tuning when transferred to specialized domains. When a sufficient amount of within-domain text may not be available, expanding a seed corpus of relevant documents from large-scale web data poses several challenges. First, corpus expansion requires scoring and ranking each document in the collection, an operation that can quickly become computationally expensive as the web corpora size grows. Relying on dense vector spaces and pairwise similarity adds to the computational expense. Secondly, as the domain concept becomes more nuanced, capturing the long tail of domain-specific rare terms becomes non-trivial, especially under limited seed corpora scenarios. In this paper, we consider the problem of fast approximate corpus expansion given a small seed corpus with a few relevant documents as a query, with the goal of capturing the long tail of a domain-specific set of concept terms. To efficiently collect large-scale domain-specific corpora with limited relevance feedback, we propose a novel truncated sparse document bit-vector representation, termed Signature Assisted Unsupervised Corpus Expansion (SAUCE). Experimental results show that SAUCE can reduce the computational burden while ensuring high within-domain lexical coverage.
Large-scale Taxonomy Induction Using Entity and Word Embeddings
May 04, 2021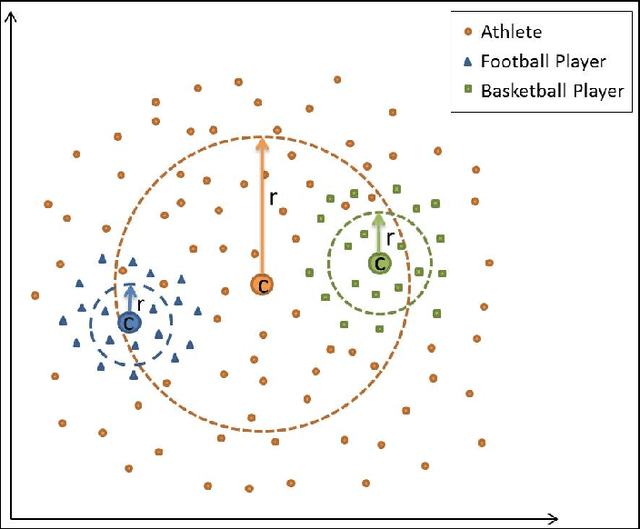
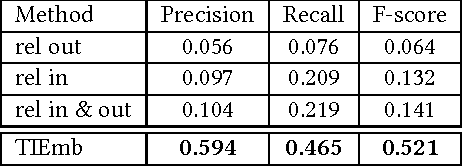

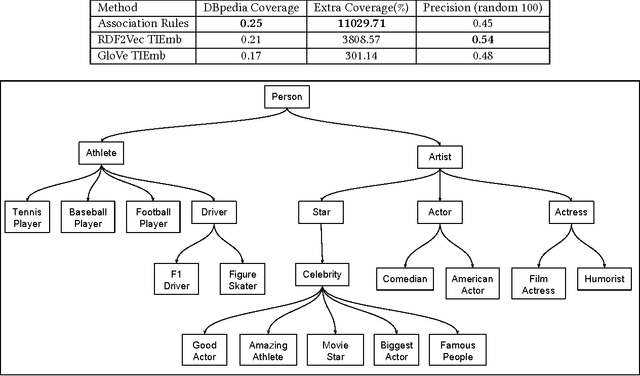
Taxonomies are an important ingredient of knowledge organization, and serve as a backbone for more sophisticated knowledge representations in intelligent systems, such as formal ontologies. However, building taxonomies manually is a costly endeavor, and hence, automatic methods for taxonomy induction are a good alternative to build large-scale taxonomies. In this paper, we propose TIEmb, an approach for automatic unsupervised class subsumption axiom extraction from knowledge bases using entity and text embeddings. We apply the approach on the WebIsA database, a database of subsumption relations extracted from the large portion of the World Wide Web, to extract class hierarchies in the Person and Place domain.
Walk Extraction Strategies for Node Embeddings with RDF2Vec in Knowledge Graphs
Sep 09, 2020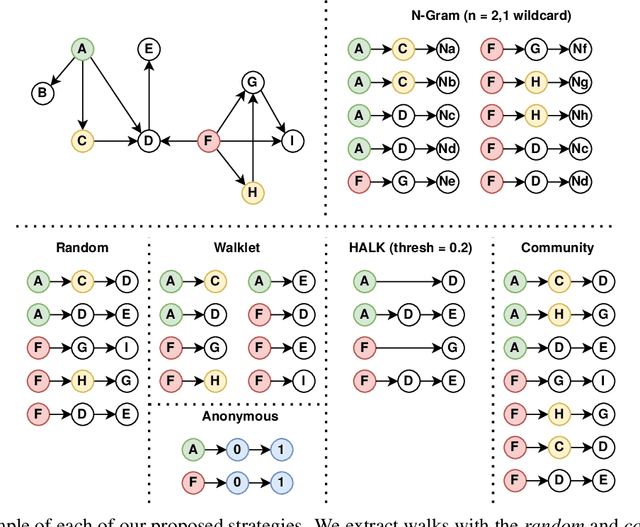
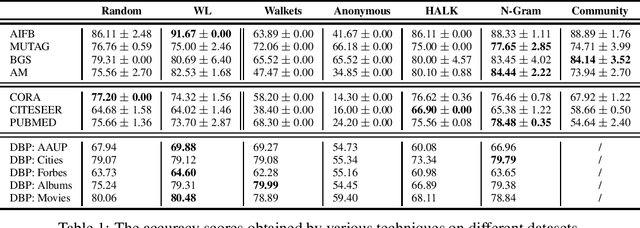

As KGs are symbolic constructs, specialized techniques have to be applied in order to make them compatible with data mining techniques. RDF2Vec is an unsupervised technique that can create task-agnostic numerical representations of the nodes in a KG by extending successful language modelling techniques. The original work proposed the Weisfeiler-Lehman (WL) kernel to improve the quality of the representations. However, in this work, we show both formally and empirically that the WL kernel does little to improve walk embeddings in the context of a single KG. As an alternative to the WL kernel, we propose five different strategies to extract information complementary to basic random walks. We compare these walks on several benchmark datasets to show that the \emph{n-gram} strategy performs best on average on node classification tasks and that tuning the walk strategy can result in improved predictive performances.