 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeuaMix-MAE: Efficient Tuning of Pretrained Audio Transformers with Unsupervised Audio Mixtures
Mar 14, 2024Masked Autoencoders (MAEs) learn rich low-level representations from unlabeled data but require substantial labeled data to effectively adapt to downstream tasks. Conversely, Instance Discrimination (ID) emphasizes high-level semantics, offering a potential solution to alleviate annotation requirements in MAEs. Although combining these two approaches can address downstream tasks with limited labeled data, naively integrating ID into MAEs leads to extended training times and high computational costs. To address this challenge, we introduce uaMix-MAE, an efficient ID tuning strategy that leverages unsupervised audio mixtures. Utilizing contrastive tuning, uaMix-MAE aligns the representations of pretrained MAEs, thereby facilitating effective adaptation to task-specific semantics. To optimize the model with small amounts of unlabeled data, we propose an audio mixing technique that manipulates audio samples in both input and virtual label spaces. Experiments in low/few-shot settings demonstrate that \modelname achieves 4-6% accuracy improvements over various benchmarks when tuned with limited unlabeled data, such as AudioSet-20K. Code is available at https://github.com/PLAN-Lab/uamix-MAE
Hard Negative Sampling Strategies for Contrastive Representation Learning
Jun 02, 2022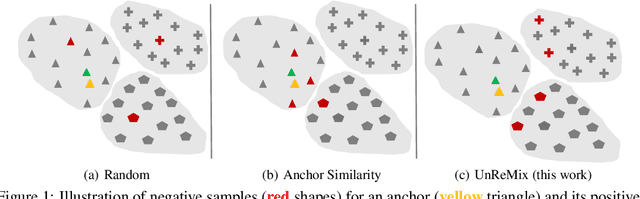
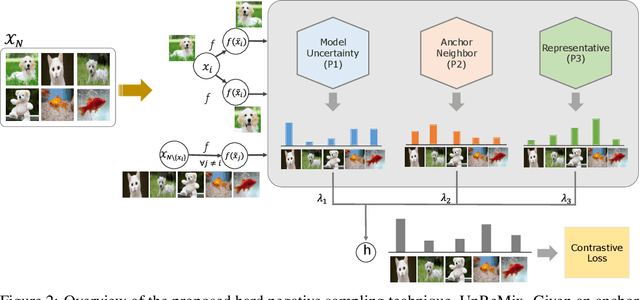
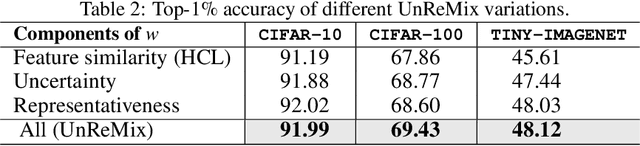

One of the challenges in contrastive learning is the selection of appropriate \textit{hard negative} examples, in the absence of label information. Random sampling or importance sampling methods based on feature similarity often lead to sub-optimal performance. In this work, we introduce UnReMix, a hard negative sampling strategy that takes into account anchor similarity, model uncertainty and representativeness. Experimental results on several benchmarks show that UnReMix improves negative sample selection, and subsequently downstream performance when compared to state-of-the-art contrastive learning methods.
Adversarial Contrastive Learning by Permuting Cluster Assignments
Apr 21, 2022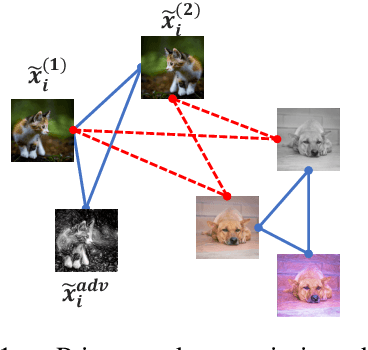
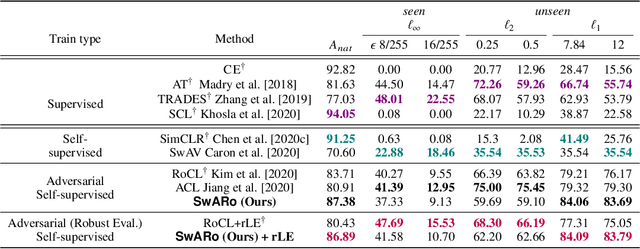
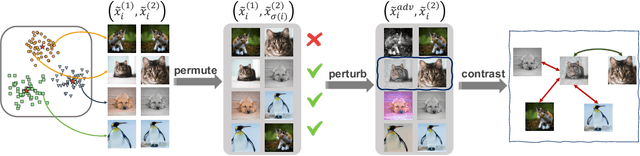
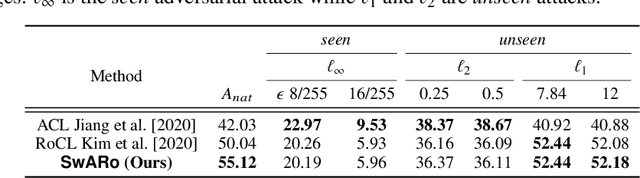
Contrastive learning has gained popularity as an effective self-supervised representation learning technique. Several research directions improve traditional contrastive approaches, e.g., prototypical contrastive methods better capture the semantic similarity among instances and reduce the computational burden by considering cluster prototypes or cluster assignments, while adversarial instance-wise contrastive methods improve robustness against a variety of attacks. To the best of our knowledge, no prior work jointly considers robustness, cluster-wise semantic similarity and computational efficiency. In this work, we propose SwARo, an adversarial contrastive framework that incorporates cluster assignment permutations to generate representative adversarial samples. We evaluate SwARo on multiple benchmark datasets and against various white-box and black-box attacks, obtaining consistent improvements over state-of-the-art baselines.