 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyncTaichi: Whole-Program Optimizations for Megakernel Sparse Computation and Differentiable Programming
Dec 15, 2020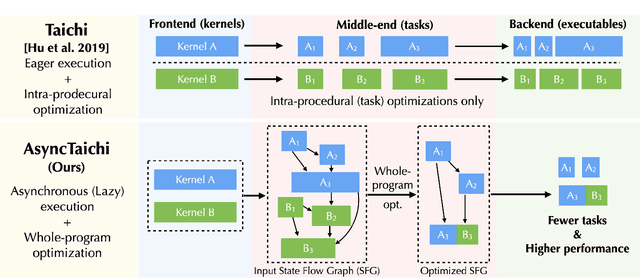
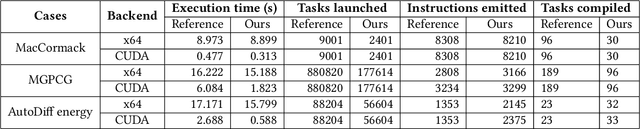

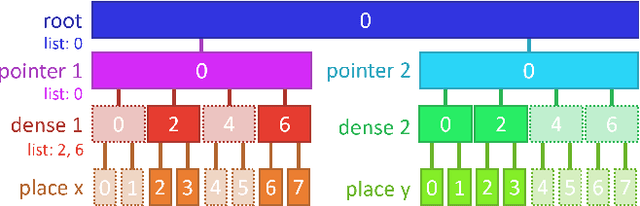
We present a whole-program optimization framework for the Taichi programming language. As an imperative language tailored for sparse and differentiable computation, Taichi's unique computational patterns lead to attractive optimization opportunities that do not present in other compiler or runtime systems. For example, to support iteration over sparse voxel grids, excessive list generation tasks are often inserted. By analyzing sparse computation programs at a higher level, our optimizer is able to remove the majority of unnecessary list generation tasks. To provide maximum programming flexibility, our optimization system conducts on-the-fly optimization of the whole computational graph consisting of Taichi kernels. The optimized Taichi kernels are then just-in-time compiled in parallel, and dispatched to parallel devices such as multithreaded CPU and massively parallel GPUs. Without any code modification on Taichi programs, our new system leads to $3.07 - 3.90\times$ fewer kernel launches and $1.73 - 2.76\times$ speed up on our benchmarks including sparse-grid physical simulation and differentiable programming.