 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegacyAvatars: Volumetric Face Avatars For Traditional Graphics Pipelines
Jan 18, 2026We introduce a novel representation for efficient classical rendering of photorealistic 3D face avatars. Leveraging recent advances in radiance fields anchored to parametric face models, our approach achieves controllable volumetric rendering of complex facial features, including hair, skin, and eyes. At enrollment time, we learn a set of radiance manifolds in 3D space to extract an explicit layered mesh, along with appearance and warp textures. During deployment, this allows us to control and animate the face through simple linear blending and alpha compositing of textures over a static mesh. This explicit representation also enables the generated avatar to be efficiently streamed online and then rendered using classical mesh and shader-based rendering on legacy graphics platforms, eliminating the need for any custom engineering or integration.
FaceFolds: Meshed Radiance Manifolds for Efficient Volumetric Rendering of Dynamic Faces
Apr 22, 2024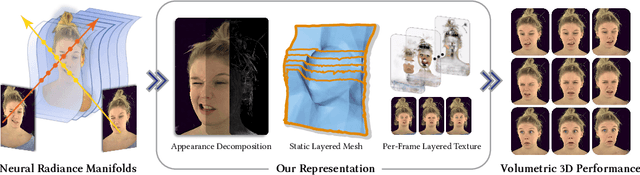

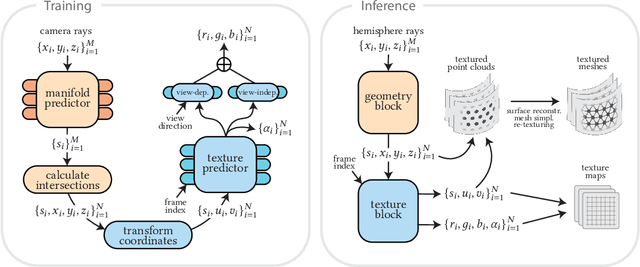
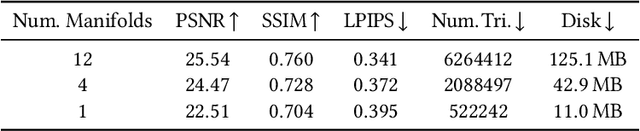
3D rendering of dynamic face captures is a challenging problem, and it demands improvements on several fronts$\unicode{x2014}$photorealism, efficiency, compatibility, and configurability. We present a novel representation that enables high-quality volumetric rendering of an actor's dynamic facial performances with minimal compute and memory footprint. It runs natively on commodity graphics soft- and hardware, and allows for a graceful trade-off between quality and efficiency. Our method utilizes recent advances in neural rendering, particularly learning discrete radiance manifolds to sparsely sample the scene to model volumetric effects. We achieve efficient modeling by learning a single set of manifolds for the entire dynamic sequence, while implicitly modeling appearance changes as temporal canonical texture. We export a single layered mesh and view-independent RGBA texture video that is compatible with legacy graphics renderers without additional ML integration. We demonstrate our method by rendering dynamic face captures of real actors in a game engine, at comparable photorealism to state-of-the-art neural rendering techniques at previously unseen frame rates.
Can Shadows Reveal Biometric Information?
Oct 04, 2022
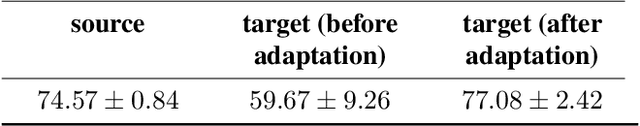


We study the problem of extracting biometric information of individuals by looking at shadows of objects cast on diffuse surfaces. We show that the biometric information leakage from shadows can be sufficient for reliable identity inference under representative scenarios via a maximum likelihood analysis. We then develop a learning-based method that demonstrates this phenomenon in real settings, exploiting the subtle cues in the shadows that are the source of the leakage without requiring any labeled real data. In particular, our approach relies on building synthetic scenes composed of 3D face models obtained from a single photograph of each identity. We transfer what we learn from the synthetic data to the real data using domain adaptation in a completely unsupervised way. Our model is able to generalize well to the real domain and is robust to several variations in the scenes. We report high classification accuracies in an identity classification task that takes place in a scene with unknown geometry and occluding objects.
MOST-GAN: 3D Morphable StyleGAN for Disentangled Face Image Manipulation
Nov 01, 2021

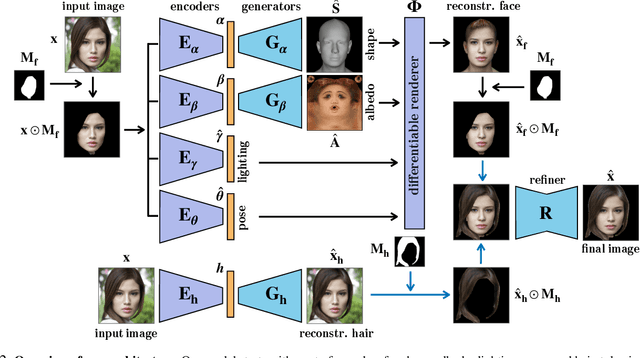

Recent advances in generative adversarial networks (GANs) have led to remarkable achievements in face image synthesis. While methods that use style-based GANs can generate strikingly photorealistic face images, it is often difficult to control the characteristics of the generated faces in a meaningful and disentangled way. Prior approaches aim to achieve such semantic control and disentanglement within the latent space of a previously trained GAN. In contrast, we propose a framework that a priori models physical attributes of the face such as 3D shape, albedo, pose, and lighting explicitly, thus providing disentanglement by design. Our method, MOST-GAN, integrates the expressive power and photorealism of style-based GANs with the physical disentanglement and flexibility of nonlinear 3D morphable models, which we couple with a state-of-the-art 2D hair manipulation network. MOST-GAN achieves photorealistic manipulation of portrait images with fully disentangled 3D control over their physical attributes, enabling extreme manipulation of lighting, facial expression, and pose variations up to full profile view.
Identity-Expression Ambiguity in 3D Morphable Face Models
Sep 29, 2021

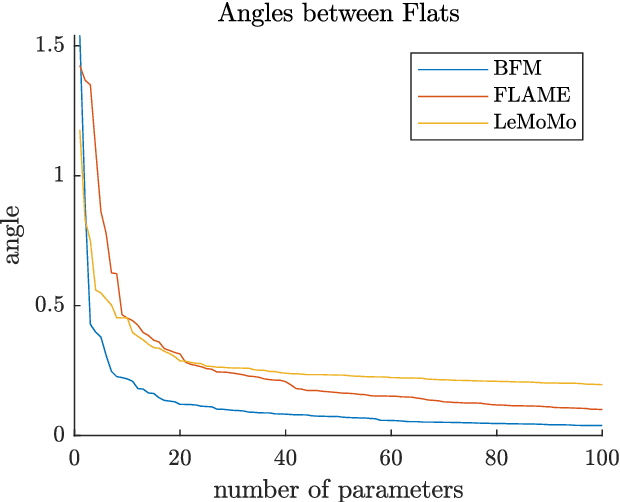
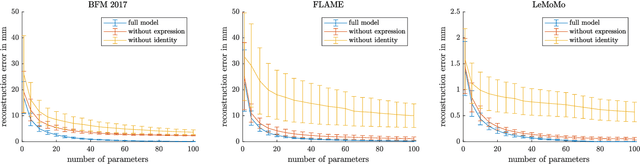
3D Morphable Models are a class of generative models commonly used to model faces. They are typically applied to ill-posed problems such as 3D reconstruction from 2D data. Several ambiguities in this problem's image formation process have been studied explicitly. We demonstrate that non-orthogonality of the variation in identity and expression can cause identity-expression ambiguity in 3D Morphable Models, and that in practice expression and identity are far from orthogonal and can explain each other surprisingly well. Whilst previously reported ambiguities only arise in an inverse rendering setting, identity-expression ambiguity emerges in the 3D shape generation process itself. We demonstrate this effect with 3D shapes directly as well as through an inverse rendering task, and use two popular models built from high quality 3D scans as well as a model built from a large collection of 2D images and videos. We explore this issue's implications for inverse rendering and observe that it cannot be resolved by a purely statistical prior on identity and expression deformations.
Beyond Binomial and Negative Binomial: Adaptation in Bernoulli Parameter Estimation
Sep 24, 2018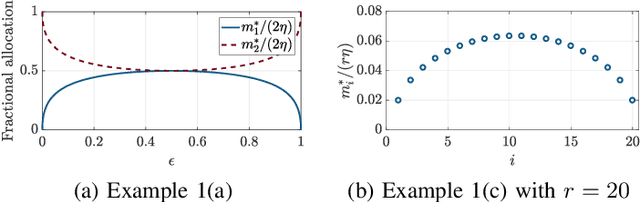
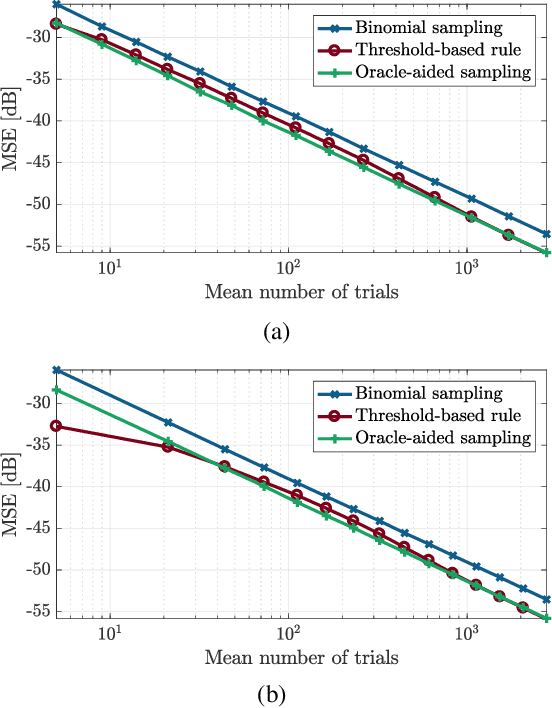
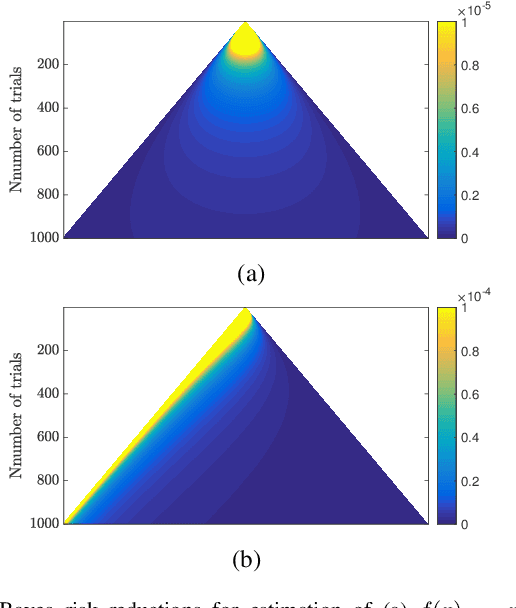
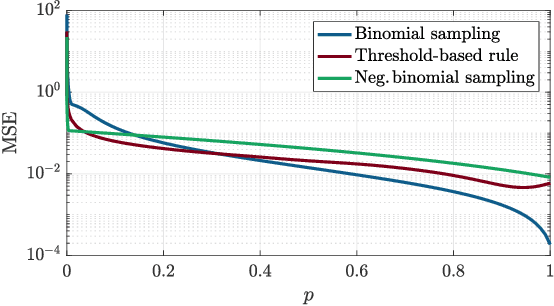
Estimating the parameter of a Bernoulli process arises in many applications, including photon-efficient active imaging where each illumination period is regarded as a single Bernoulli trial. Motivated by acquisition efficiency when multiple Bernoulli processes are of interest, we formulate the allocation of trials under a constraint on the mean as an optimal resource allocation problem. An oracle-aided trial allocation demonstrates that there can be a significant advantage from varying the allocation for different processes and inspires a simple trial allocation gain quantity. Motivated by realizing this gain without an oracle, we present a trellis-based framework for representing and optimizing stopping rules. Considering the convenient case of Beta priors, three implementable stopping rules with similar performances are explored, and the simplest of these is shown to asymptotically achieve the oracle-aided trial allocation. These approaches are further extended to estimating functions of a Bernoulli parameter. In simulations inspired by realistic active imaging scenarios, we demonstrate significant mean-squared error improvements: up to 4.36 dB for the estimation of p and up to 1.80 dB for the estimation of log p.