 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding 3D Generative Models from Minimal Data
Mar 04, 2022


We propose a method for constructing generative models of 3D objects from a single 3D mesh and improving them through unsupervised low-shot learning from 2D images. Our method produces a 3D morphable model that represents shape and albedo in terms of Gaussian processes. Whereas previous approaches have typically built 3D morphable models from multiple high-quality 3D scans through principal component analysis, we build 3D morphable models from a single scan or template. As we demonstrate in the face domain, these models can be used to infer 3D reconstructions from 2D data (inverse graphics) or 3D data (registration). Specifically, we show that our approach can be used to perform face recognition using only a single 3D template (one scan total, not one per person). We extend our model to a preliminary unsupervised learning framework that enables the learning of the distribution of 3D faces using one 3D template and a small number of 2D images. This approach could also provide a model for the origins of face perception in human infants, who appear to start with an innate face template and subsequently develop a flexible system for perceiving the 3D structure of any novel face from experience with only 2D images of a relatively small number of familiar faces.
Identity-Expression Ambiguity in 3D Morphable Face Models
Sep 29, 2021

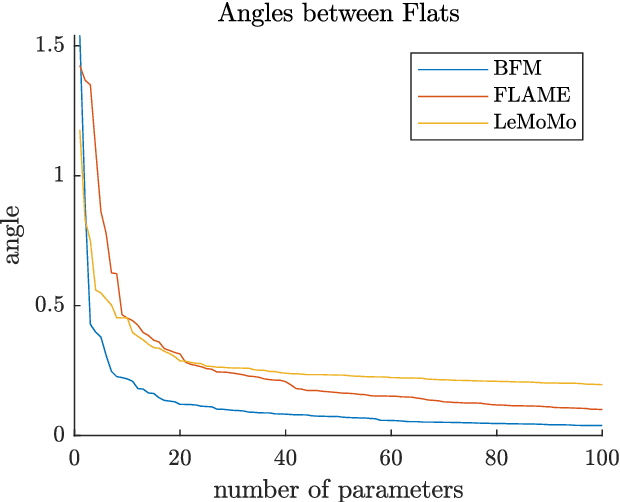
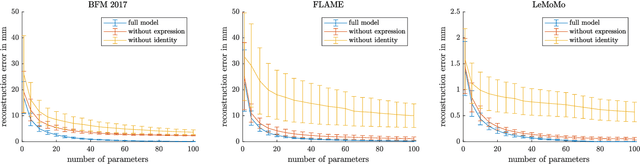
3D Morphable Models are a class of generative models commonly used to model faces. They are typically applied to ill-posed problems such as 3D reconstruction from 2D data. Several ambiguities in this problem's image formation process have been studied explicitly. We demonstrate that non-orthogonality of the variation in identity and expression can cause identity-expression ambiguity in 3D Morphable Models, and that in practice expression and identity are far from orthogonal and can explain each other surprisingly well. Whilst previously reported ambiguities only arise in an inverse rendering setting, identity-expression ambiguity emerges in the 3D shape generation process itself. We demonstrate this effect with 3D shapes directly as well as through an inverse rendering task, and use two popular models built from high quality 3D scans as well as a model built from a large collection of 2D images and videos. We explore this issue's implications for inverse rendering and observe that it cannot be resolved by a purely statistical prior on identity and expression deformations.
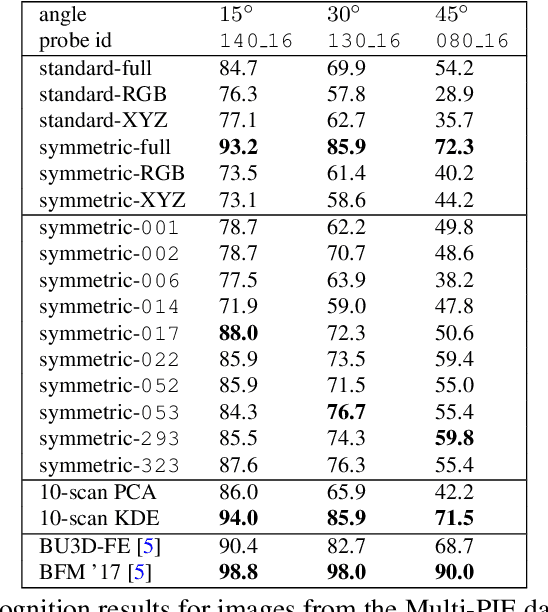
Building 3D Morphable Models from a Single Scan
Nov 24, 2020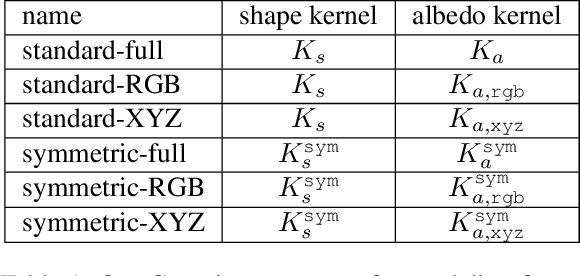

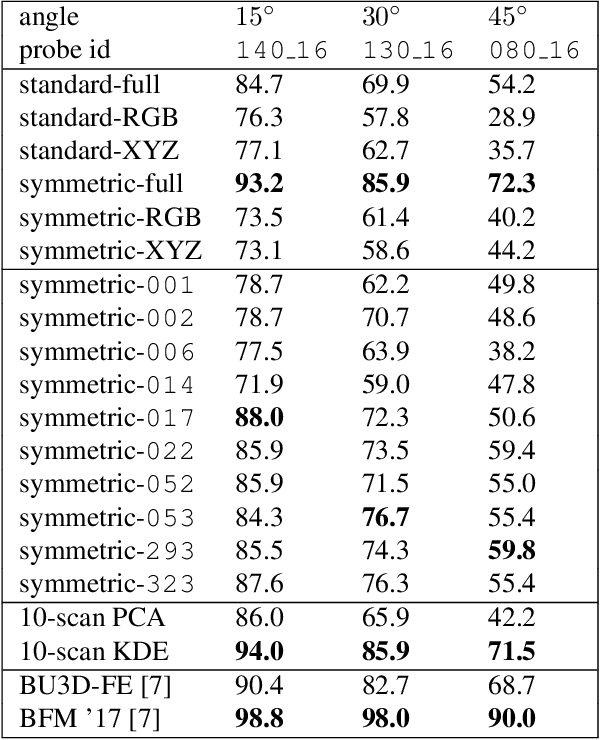
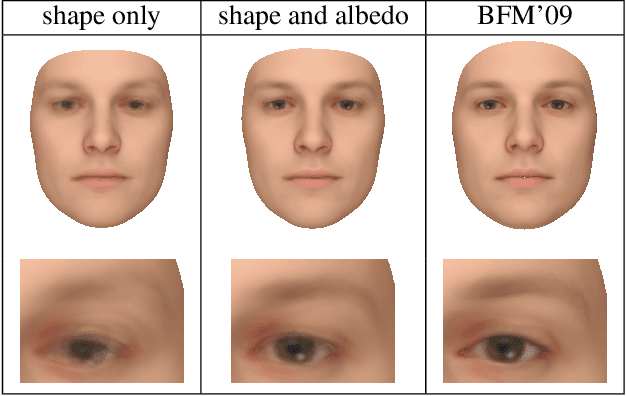
We propose a method for constructing generative models of 3D objects from a single 3D mesh. Our method produces a 3D morphable model that represents shape and albedo in terms of Gaussian processes. We define the shape deformations in physical (3D) space and the albedo deformations as a combination of physical-space and color-space deformations. Whereas previous approaches have typically built 3D morphable models from multiple high-quality 3D scans through principal component analysis, we build 3D morphable models from a single scan or template. We demonstrate the utility of these models in the domain of face modeling through inverse rendering and registration tasks. Specifically, we show that our approach can be used to perform face recognition using only a single 3D scan (one scan total, not one per person), and further demonstrate how multiple scans can be incorporated to improve performance without requiring dense correspondence. Our approach enables the synthesis of 3D morphable models for 3D object categories where dense correspondence between multiple scans is unavailable. We demonstrate this by constructing additional 3D morphable models for fish and birds and use them to perform simple inverse rendering tasks.