 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeGA: Texture Space Gaussian Avatars for High-Resolution Dynamic Head Modeling
May 08, 2025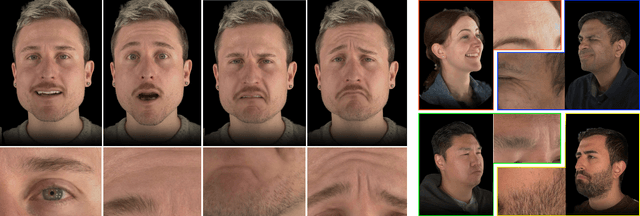
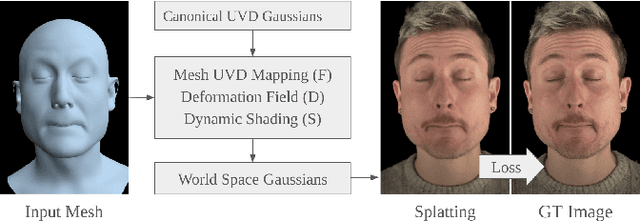


Sparse volumetric reconstruction and rendering via 3D Gaussian splatting have recently enabled animatable 3D head avatars that are rendered under arbitrary viewpoints with impressive photorealism. Today, such photoreal avatars are seen as a key component in emerging applications in telepresence, extended reality, and entertainment. Building a photoreal avatar requires estimating the complex non-rigid motion of different facial components as seen in input video images; due to inaccurate motion estimation, animatable models typically present a loss of fidelity and detail when compared to their non-animatable counterparts, built from an individual facial expression. Also, recent state-of-the-art models are often affected by memory limitations that reduce the number of 3D Gaussians used for modeling, leading to lower detail and quality. To address these problems, we present a new high-detail 3D head avatar model that improves upon the state of the art, largely increasing the number of 3D Gaussians and modeling quality for rendering at 4K resolution. Our high-quality model is reconstructed from multiview input video and builds on top of a mesh-based 3D morphable model, which provides a coarse deformation layer for the head. Photoreal appearance is modelled by 3D Gaussians embedded within the continuous UVD tangent space of this mesh, allowing for more effective densification where most needed. Additionally, these Gaussians are warped by a novel UVD deformation field to capture subtle, localized motion. Our key contribution is the novel deformable Gaussian encoding and overall fitting procedure that allows our head model to preserve appearance detail, while capturing facial motion and other transient high-frequency features such as skin wrinkling.
Pixels2Points: Fusing 2D and 3D Features for Facial Skin Segmentation
Apr 28, 2025Face registration deforms a template mesh to closely fit a 3D face scan, the quality of which commonly degrades in non-skin regions (e.g., hair, beard, accessories), because the optimized template-to-scan distance pulls the template mesh towards the noisy scan surface. Improving registration quality requires a clean separation of skin and non-skin regions on the scan mesh. Existing image-based (2D) or scan-based (3D) segmentation methods however perform poorly. Image-based segmentation outputs multi-view inconsistent masks, and they cannot account for scan inaccuracies or scan-image misalignment, while scan-based methods suffer from lower spatial resolution compared to images. In this work, we introduce a novel method that accurately separates skin from non-skin geometry on 3D human head scans. For this, our method extracts features from multi-view images using a frozen image foundation model and aggregates these features in 3D. These lifted 2D features are then fused with 3D geometric features extracted from the scan mesh, to then predict a segmentation mask directly on the scan mesh. We show that our segmentations improve the registration accuracy over pure 2D or 3D segmentation methods by 8.89% and 14.3%, respectively. Although trained only on synthetic data, our model generalizes well to real data.
Cafca: High-quality Novel View Synthesis of Expressive Faces from Casual Few-shot Captures
Oct 01, 2024
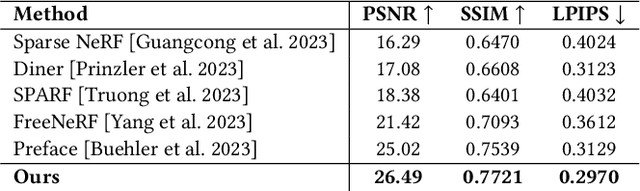

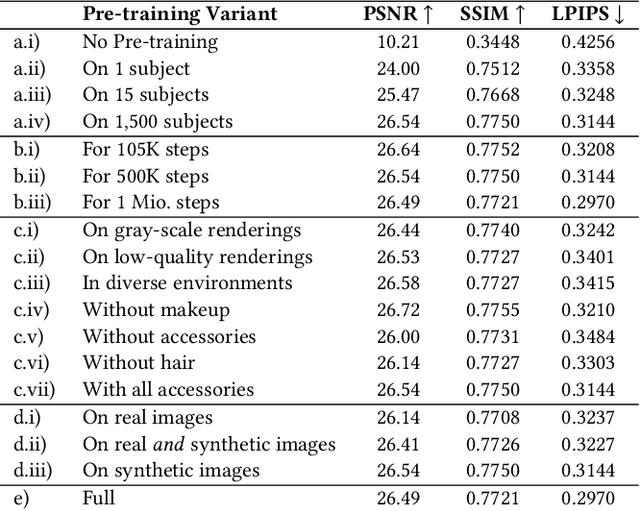
Volumetric modeling and neural radiance field representations have revolutionized 3D face capture and photorealistic novel view synthesis. However, these methods often require hundreds of multi-view input images and are thus inapplicable to cases with less than a handful of inputs. We present a novel volumetric prior on human faces that allows for high-fidelity expressive face modeling from as few as three input views captured in the wild. Our key insight is that an implicit prior trained on synthetic data alone can generalize to extremely challenging real-world identities and expressions and render novel views with fine idiosyncratic details like wrinkles and eyelashes. We leverage a 3D Morphable Face Model to synthesize a large training set, rendering each identity with different expressions, hair, clothing, and other assets. We then train a conditional Neural Radiance Field prior on this synthetic dataset and, at inference time, fine-tune the model on a very sparse set of real images of a single subject. On average, the fine-tuning requires only three inputs to cross the synthetic-to-real domain gap. The resulting personalized 3D model reconstructs strong idiosyncratic facial expressions and outperforms the state-of-the-art in high-quality novel view synthesis of faces from sparse inputs in terms of perceptual and photo-metric quality.
FaceFolds: Meshed Radiance Manifolds for Efficient Volumetric Rendering of Dynamic Faces
Apr 22, 2024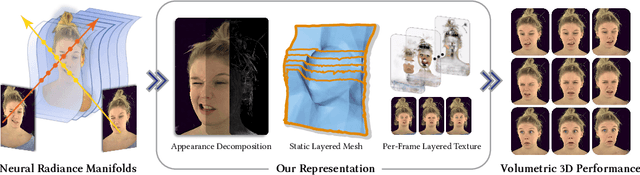

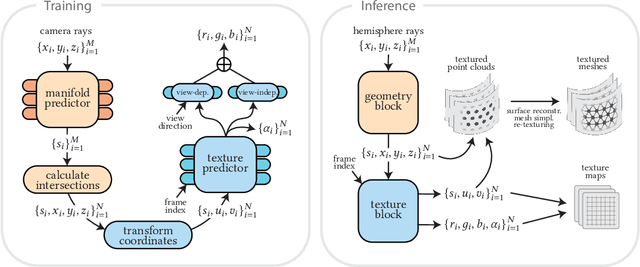
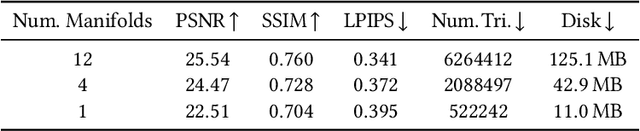
3D rendering of dynamic face captures is a challenging problem, and it demands improvements on several fronts$\unicode{x2014}$photorealism, efficiency, compatibility, and configurability. We present a novel representation that enables high-quality volumetric rendering of an actor's dynamic facial performances with minimal compute and memory footprint. It runs natively on commodity graphics soft- and hardware, and allows for a graceful trade-off between quality and efficiency. Our method utilizes recent advances in neural rendering, particularly learning discrete radiance manifolds to sparsely sample the scene to model volumetric effects. We achieve efficient modeling by learning a single set of manifolds for the entire dynamic sequence, while implicitly modeling appearance changes as temporal canonical texture. We export a single layered mesh and view-independent RGBA texture video that is compatible with legacy graphics renderers without additional ML integration. We demonstrate our method by rendering dynamic face captures of real actors in a game engine, at comparable photorealism to state-of-the-art neural rendering techniques at previously unseen frame rates.
Binary Opacity Grids: Capturing Fine Geometric Detail for Mesh-Based View Synthesis
Feb 19, 2024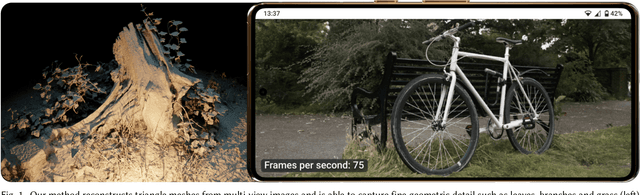



While surface-based view synthesis algorithms are appealing due to their low computational requirements, they often struggle to reproduce thin structures. In contrast, more expensive methods that model the scene's geometry as a volumetric density field (e.g. NeRF) excel at reconstructing fine geometric detail. However, density fields often represent geometry in a "fuzzy" manner, which hinders exact localization of the surface. In this work, we modify density fields to encourage them to converge towards surfaces, without compromising their ability to reconstruct thin structures. First, we employ a discrete opacity grid representation instead of a continuous density field, which allows opacity values to discontinuously transition from zero to one at the surface. Second, we anti-alias by casting multiple rays per pixel, which allows occlusion boundaries and subpixel structures to be modelled without using semi-transparent voxels. Third, we minimize the binary entropy of the opacity values, which facilitates the extraction of surface geometry by encouraging opacity values to binarize towards the end of training. Lastly, we develop a fusion-based meshing strategy followed by mesh simplification and appearance model fitting. The compact meshes produced by our model can be rendered in real-time on mobile devices and achieve significantly higher view synthesis quality compared to existing mesh-based approaches.
3D face reconstruction with dense landmarks
Apr 06, 2022



Landmarks often play a key role in face analysis, but many aspects of identity or expression cannot be represented by sparse landmarks alone. Thus, in order to reconstruct faces more accurately, landmarks are often combined with additional signals like depth images or techniques like differentiable rendering. Can we keep things simple by just using more landmarks? In answer, we present the first method that accurately predicts 10x as many landmarks as usual, covering the whole head, including the eyes and teeth. This is accomplished using synthetic training data, which guarantees perfect landmark annotations. By fitting a morphable model to these dense landmarks, we achieve state-of-the-art results for monocular 3D face reconstruction in the wild. We show that dense landmarks are an ideal signal for integrating face shape information across frames by demonstrating accurate and expressive facial performance capture in both monocular and multi-view scenarios. This approach is also highly efficient: we can predict dense landmarks and fit our 3D face model at over 150FPS on a single CPU thread.