 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixels2Points: Fusing 2D and 3D Features for Facial Skin Segmentation
Apr 28, 2025Face registration deforms a template mesh to closely fit a 3D face scan, the quality of which commonly degrades in non-skin regions (e.g., hair, beard, accessories), because the optimized template-to-scan distance pulls the template mesh towards the noisy scan surface. Improving registration quality requires a clean separation of skin and non-skin regions on the scan mesh. Existing image-based (2D) or scan-based (3D) segmentation methods however perform poorly. Image-based segmentation outputs multi-view inconsistent masks, and they cannot account for scan inaccuracies or scan-image misalignment, while scan-based methods suffer from lower spatial resolution compared to images. In this work, we introduce a novel method that accurately separates skin from non-skin geometry on 3D human head scans. For this, our method extracts features from multi-view images using a frozen image foundation model and aggregates these features in 3D. These lifted 2D features are then fused with 3D geometric features extracted from the scan mesh, to then predict a segmentation mask directly on the scan mesh. We show that our segmentations improve the registration accuracy over pure 2D or 3D segmentation methods by 8.89% and 14.3%, respectively. Although trained only on synthetic data, our model generalizes well to real data.
Learning to Stabilize Faces
Nov 22, 2024Nowadays, it is possible to scan faces and automatically register them with high quality. However, the resulting face meshes often need further processing: we need to stabilize them to remove unwanted head movement. Stabilization is important for tasks like game development or movie making which require facial expressions to be cleanly separated from rigid head motion. Since manual stabilization is labor-intensive, there have been attempts to automate it. However, previous methods remain impractical: they either still require some manual input, produce imprecise alignments, rely on dubious heuristics and slow optimization, or assume a temporally ordered input. Instead, we present a new learning-based approach that is simple and fully automatic. We treat stabilization as a regression problem: given two face meshes, our network directly predicts the rigid transform between them that brings their skulls into alignment. We generate synthetic training data using a 3D Morphable Model (3DMM), exploiting the fact that 3DMM parameters separate skull motion from facial skin motion. Through extensive experiments we show that our approach outperforms the state-of-the-art both quantitatively and qualitatively on the tasks of stabilizing discrete sets of facial expressions as well as dynamic facial performances. Furthermore, we provide an ablation study detailing the design choices and best practices to help others adopt our approach for their own uses. Supplementary videos can be found on the project webpage syntec-research.github.io/FaceStab.
Cafca: High-quality Novel View Synthesis of Expressive Faces from Casual Few-shot Captures
Oct 01, 2024
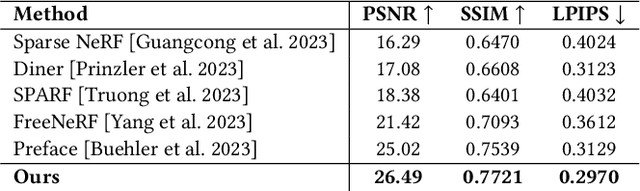

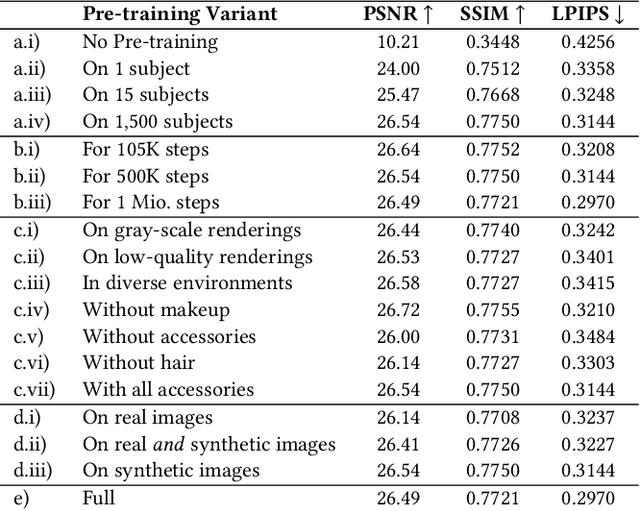
Volumetric modeling and neural radiance field representations have revolutionized 3D face capture and photorealistic novel view synthesis. However, these methods often require hundreds of multi-view input images and are thus inapplicable to cases with less than a handful of inputs. We present a novel volumetric prior on human faces that allows for high-fidelity expressive face modeling from as few as three input views captured in the wild. Our key insight is that an implicit prior trained on synthetic data alone can generalize to extremely challenging real-world identities and expressions and render novel views with fine idiosyncratic details like wrinkles and eyelashes. We leverage a 3D Morphable Face Model to synthesize a large training set, rendering each identity with different expressions, hair, clothing, and other assets. We then train a conditional Neural Radiance Field prior on this synthetic dataset and, at inference time, fine-tune the model on a very sparse set of real images of a single subject. On average, the fine-tuning requires only three inputs to cross the synthetic-to-real domain gap. The resulting personalized 3D model reconstructs strong idiosyncratic facial expressions and outperforms the state-of-the-art in high-quality novel view synthesis of faces from sparse inputs in terms of perceptual and photo-metric quality.
Preface: A Data-driven Volumetric Prior for Few-shot Ultra High-resolution Face Synthesis
Sep 28, 2023NeRFs have enabled highly realistic synthesis of human faces including complex appearance and reflectance effects of hair and skin. These methods typically require a large number of multi-view input images, making the process hardware intensive and cumbersome, limiting applicability to unconstrained settings. We propose a novel volumetric human face prior that enables the synthesis of ultra high-resolution novel views of subjects that are not part of the prior's training distribution. This prior model consists of an identity-conditioned NeRF, trained on a dataset of low-resolution multi-view images of diverse humans with known camera calibration. A simple sparse landmark-based 3D alignment of the training dataset allows our model to learn a smooth latent space of geometry and appearance despite a limited number of training identities. A high-quality volumetric representation of a novel subject can be obtained by model fitting to 2 or 3 camera views of arbitrary resolution. Importantly, our method requires as few as two views of casually captured images as input at inference time.
Deep Dynamic Scene Deblurring from Optical Flow
Jan 18, 2023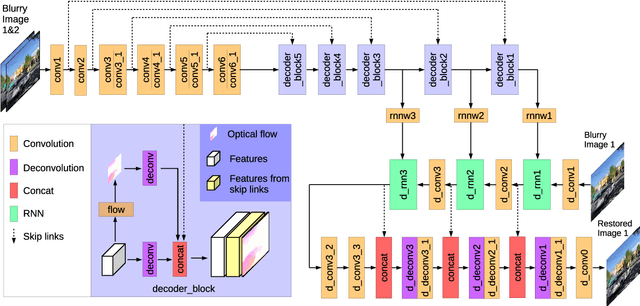



Deblurring can not only provide visually more pleasant pictures and make photography more convenient, but also can improve the performance of objection detection as well as tracking. However, removing dynamic scene blur from images is a non-trivial task as it is difficult to model the non-uniform blur mathematically. Several methods first use single or multiple images to estimate optical flow (which is treated as an approximation of blur kernels) and then adopt non-blind deblurring algorithms to reconstruct the sharp images. However, these methods cannot be trained in an end-to-end manner and are usually computationally expensive. In this paper, we explore optical flow to remove dynamic scene blur by using the multi-scale spatially variant recurrent neural network (RNN). We utilize FlowNets to estimate optical flow from two consecutive images in different scales. The estimated optical flow provides the RNN weights in different scales so that the weights can better help RNNs to remove blur in the feature spaces. Finally, we develop a convolutional neural network (CNN) to restore the sharp images from the deblurred features. Both quantitative and qualitative evaluations on the benchmark datasets demonstrate that the proposed method performs favorably against state-of-the-art algorithms in terms of accuracy, speed, and model size.
Low-Dose CT Denoising Using a Structure-Preserving Kernel Prediction Network
May 31, 2021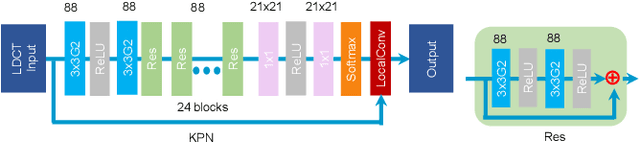
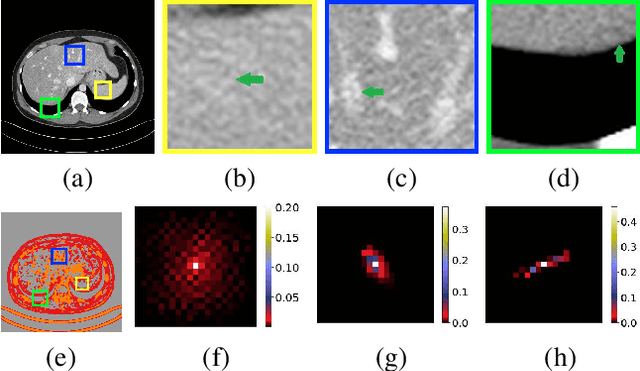


Low-dose CT has been a key diagnostic imaging modality to reduce the potential risk of radiation overdose to patient health. Despite recent advances, CNN-based approaches typically apply filters in a spatially invariant way and adopt similar pixel-level losses, which treat all regions of the CT image equally and can be inefficient when fine-grained structures coexist with non-uniformly distributed noises. To address this issue, we propose a Structure-preserving Kernel Prediction Network (StructKPN) that combines the kernel prediction network with a structure-aware loss function that utilizes the pixel gradient statistics and guides the model towards spatially-variant filters that enhance noise removal, prevent over-smoothing and preserve detailed structures for different regions in CT imaging. Extensive experiments demonstrated that our approach achieved superior performance on both synthetic and non-synthetic datasets, and better preserves structures that are highly desired in clinical screening and low-dose protocol optimization.
Dual Student: Breaking the Limits of the Teacher in Semi-supervised Learning
Sep 03, 2019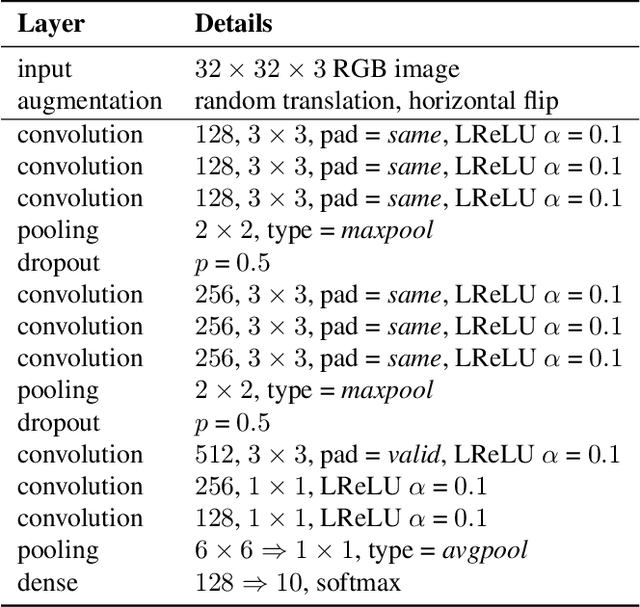

Recently, consistency-based methods have achieved state-of-the-art results in semi-supervised learning (SSL). These methods always involve two roles, an explicit or implicit teacher model and a student model, and penalize predictions under different perturbations by a consistency constraint. However, the weights of these two roles are tightly coupled since the teacher is essentially an exponential moving average (EMA) of the student. In this work, we show that the coupled EMA teacher causes a performance bottleneck. To address this problem, we introduce Dual Student, which replaces the teacher with another student. We also define a novel concept, stable sample, following which a stabilization constraint is designed for our structure to be trainable. Further, we discuss two variants of our method, which produce even higher performance. Extensive experiments show that our method improves the classification performance significantly on several main SSL benchmarks. Specifically, it reduces the error rate of the 13-layer CNN from 16.84% to 12.39% on CIFAR-10 with 1k labels and from 34.10% to 31.56% on CIFAR-100 with 10k labels. In addition, our method also achieves a clear improvement in domain adaptation.