 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePC-SRIF: Preconditioned Cholesky-based Square Root Information Filter for Vision-aided Inertial Navigation
Sep 17, 2024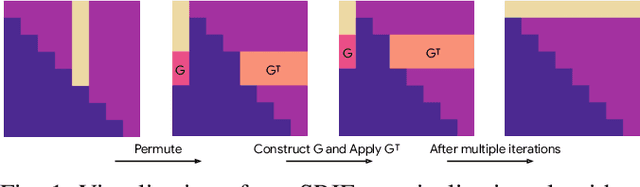
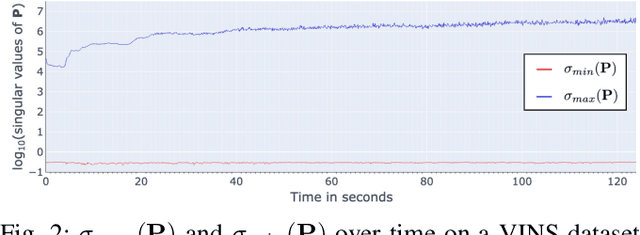
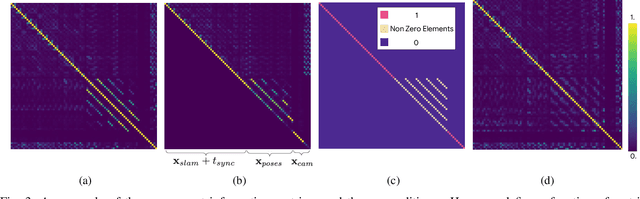
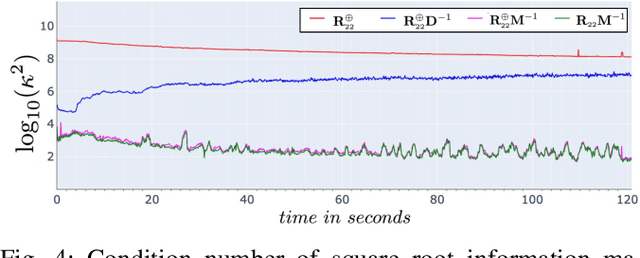
In this paper, we introduce a novel estimator for vision-aided inertial navigation systems (VINS), the Preconditioned Cholesky-based Square Root Information Filter (PC-SRIF). When solving linear systems, employing Cholesky decomposition offers superior efficiency but can compromise numerical stability. Due to this, existing VINS utilizing (Square Root) Information Filters often opt for QR decomposition on platforms where single precision is preferred, avoiding the numerical challenges associated with Cholesky decomposition. While these issues are often attributed to the ill-conditioned information matrix in VINS, our analysis reveals that this is not an inherent property of VINS but rather a consequence of specific parameterizations. We identify several factors that contribute to an ill-conditioned information matrix and propose a preconditioning technique to mitigate these conditioning issues. Building on this analysis, we present PC-SRIF, which exhibits remarkable stability in performing Cholesky decomposition in single precision when solving linear systems in VINS. Consequently, PC-SRIF achieves superior theoretical efficiency compared to alternative estimators. To validate the efficiency advantages and numerical stability of PC-SRIF based VINS, we have conducted well controlled experiments, which provide empirical evidence in support of our theoretical findings. Remarkably, in our VINS implementation, PC-SRIF's runtime is 41% faster than QR-based SRIF.
3D face reconstruction with dense landmarks
Apr 06, 2022



Landmarks often play a key role in face analysis, but many aspects of identity or expression cannot be represented by sparse landmarks alone. Thus, in order to reconstruct faces more accurately, landmarks are often combined with additional signals like depth images or techniques like differentiable rendering. Can we keep things simple by just using more landmarks? In answer, we present the first method that accurately predicts 10x as many landmarks as usual, covering the whole head, including the eyes and teeth. This is accomplished using synthetic training data, which guarantees perfect landmark annotations. By fitting a morphable model to these dense landmarks, we achieve state-of-the-art results for monocular 3D face reconstruction in the wild. We show that dense landmarks are an ideal signal for integrating face shape information across frames by demonstrating accurate and expressive facial performance capture in both monocular and multi-view scenarios. This approach is also highly efficient: we can predict dense landmarks and fit our 3D face model at over 150FPS on a single CPU thread.
The Phong Surface: Efficient 3D Model Fitting using Lifted Optimization
Jul 09, 2020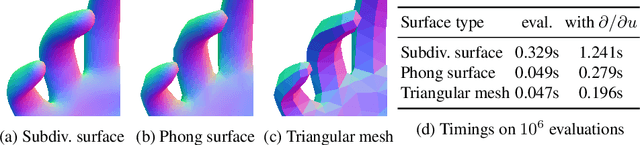
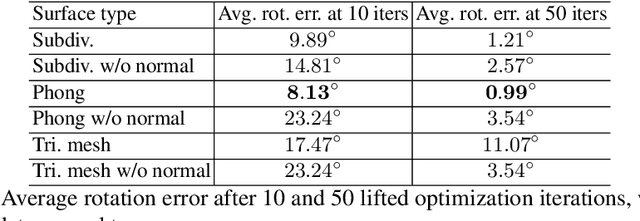
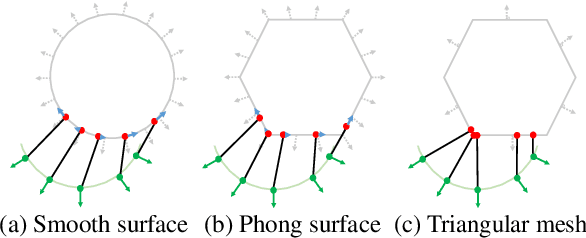
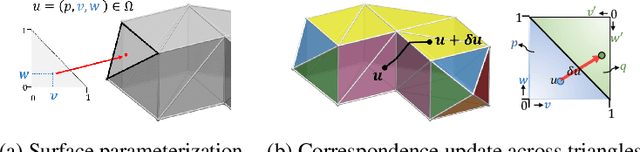
Realtime perceptual and interaction capabilities in mixed reality require a range of 3D tracking problems to be solved at low latency on resource-constrained hardware such as head-mounted devices. Indeed, for devices such as HoloLens 2 where the CPU and GPU are left available for applications, multiple tracking subsystems are required to run on a continuous, real-time basis while sharing a single Digital Signal Processor. To solve model-fitting problems for HoloLens 2 hand tracking, where the computational budget is approximately 100 times smaller than an iPhone 7, we introduce a new surface model: the `Phong surface'. Using ideas from computer graphics, the Phong surface describes the same 3D shape as a triangulated mesh model, but with continuous surface normals which enable the use of lifting-based optimization, providing significant efficiency gains over ICP-based methods. We show that Phong surfaces retain the convergence benefits of smoother surface models, while triangle meshes do not.