 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePC-SRIF: Preconditioned Cholesky-based Square Root Information Filter for Vision-aided Inertial Navigation
Sep 17, 2024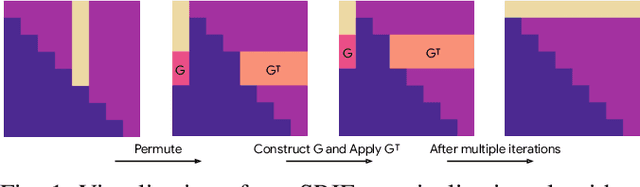
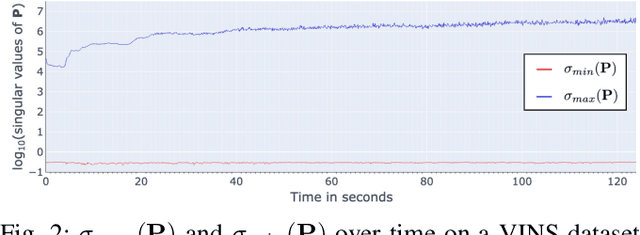
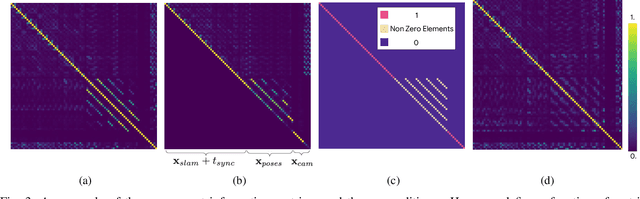
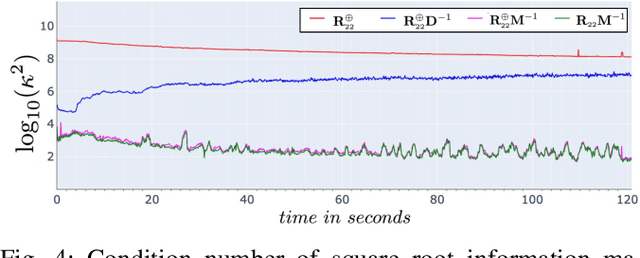
In this paper, we introduce a novel estimator for vision-aided inertial navigation systems (VINS), the Preconditioned Cholesky-based Square Root Information Filter (PC-SRIF). When solving linear systems, employing Cholesky decomposition offers superior efficiency but can compromise numerical stability. Due to this, existing VINS utilizing (Square Root) Information Filters often opt for QR decomposition on platforms where single precision is preferred, avoiding the numerical challenges associated with Cholesky decomposition. While these issues are often attributed to the ill-conditioned information matrix in VINS, our analysis reveals that this is not an inherent property of VINS but rather a consequence of specific parameterizations. We identify several factors that contribute to an ill-conditioned information matrix and propose a preconditioning technique to mitigate these conditioning issues. Building on this analysis, we present PC-SRIF, which exhibits remarkable stability in performing Cholesky decomposition in single precision when solving linear systems in VINS. Consequently, PC-SRIF achieves superior theoretical efficiency compared to alternative estimators. To validate the efficiency advantages and numerical stability of PC-SRIF based VINS, we have conducted well controlled experiments, which provide empirical evidence in support of our theoretical findings. Remarkably, in our VINS implementation, PC-SRIF's runtime is 41% faster than QR-based SRIF.
Unified Representation of Geometric Primitives for Graph-SLAM Optimization Using Decomposed Quadrics
Aug 20, 2021
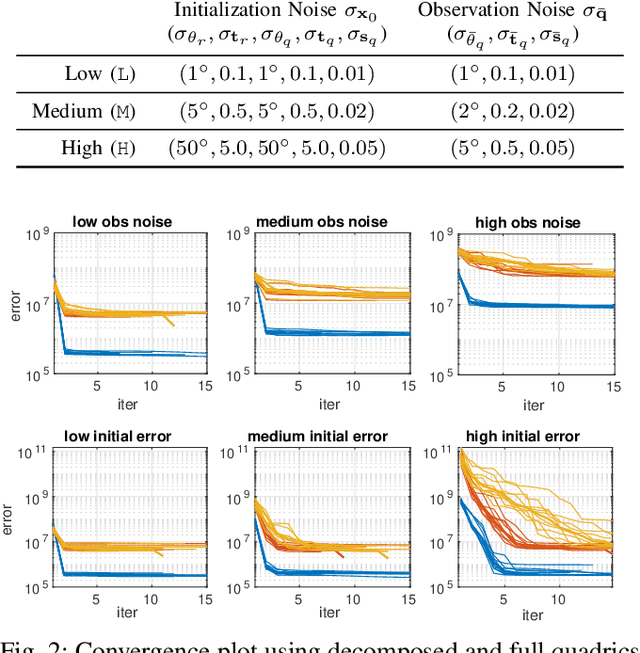

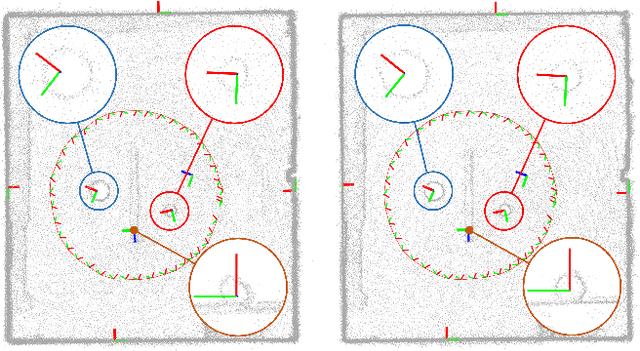
In Simultaneous Localization And Mapping (SLAM) problems, high-level landmarks have the potential to build compact and informative maps compared to traditional point-based landmarks. This work is focused on the parameterization problem of high-level geometric primitives that are most frequently used, including points, lines, planes, ellipsoids, cylinders, and cones. We first present a unified representation of those geometric primitives using \emph{quadrics} which yields a consistent and concise formulation. Then we further study a decomposed model of quadrics that discloses the symmetric and degenerated nature of quadrics. Based on the decomposition, we develop physically meaningful quadrics factors in the settings of the graph-SLAM problem. Finally, in simulation experiments, it is shown that the decomposed formulation has better efficiency and robustness to observation noises than baseline parameterizations. And in real-world experiments, the proposed back-end framework is demonstrated to be capable of building compact and regularized maps.
ORStereo: Occlusion-Aware Recurrent Stereo Matching for 4K-Resolution Images
Mar 13, 2021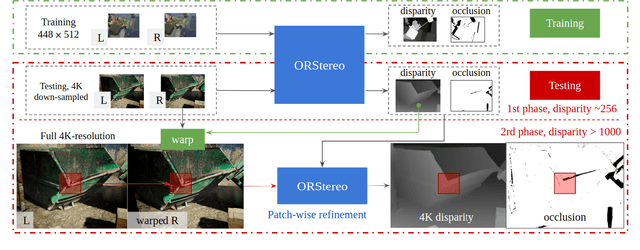

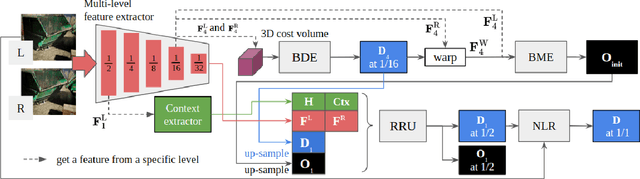
Stereo reconstruction models trained on small images do not generalize well to high-resolution data. Training a model on high-resolution image size faces difficulties of data availability and is often infeasible due to limited computing resources. In this work, we present the Occlusion-aware Recurrent binocular Stereo matching (ORStereo), which deals with these issues by only training on available low disparity range stereo images. ORStereo generalizes to unseen high-resolution images with large disparity ranges by formulating the task as residual updates and refinements of an initial prediction. ORStereo is trained on images with disparity ranges limited to 256 pixels, yet it can operate 4K-resolution input with over 1000 disparities using limited GPU memory. We test the model's capability on both synthetic and real-world high-resolution images. Experimental results demonstrate that ORStereo achieves comparable performance on 4K-resolution images compared to state-of-the-art methods trained on large disparity ranges. Compared to other methods that are only trained on low-resolution images, our method is 70% more accurate on 4K-resolution images.
Monocular Camera Localization in Prior LiDAR Maps with 2D-3D Line Correspondences
Apr 01, 2020
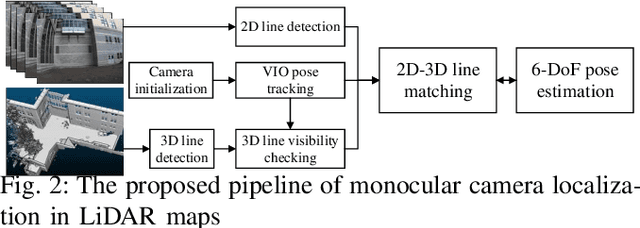

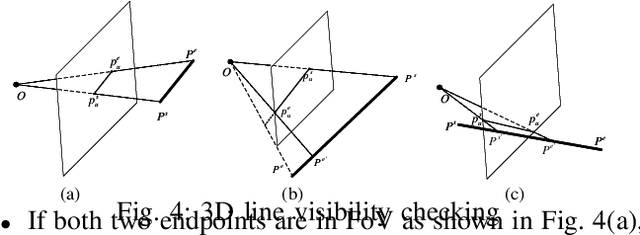
Light-weight camera localization in existing maps is essential for vision-based navigation. Currently, visual and visual-inertial odometry (VO\&VIO) techniques are well-developed for state estimation but with inevitable accumulated drifts and pose jumps upon loop closure. To overcome these problems, we propose an efficient monocular camera localization method in prior LiDAR maps using directly estimated 2D-3D line correspondences. To handle the appearance differences and modality gaps between untextured point clouds and images, geometric 3D lines are extracted offline from LiDAR maps while robust 2D lines are extracted online from video sequences. With the pose prediction from VIO, we can efficiently obtain coarse 2D-3D line correspondences. After that, the camera poses and 2D-3D correspondences are iteratively optimized by minimizing the projection error of correspondences and rejecting outliers. The experiment results on the EurocMav dataset and our collected dataset demonstrate that the proposed method can efficiently estimate camera poses without accumulated drifts or pose jumps in urban environments. The code and our collected data are available at https://github.com/levenberg/2D-3D-pose-tracking.
Line-based Camera Pose Estimation in Point Cloud of Structured Environments
Dec 12, 2019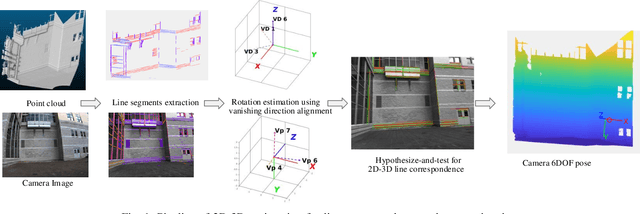

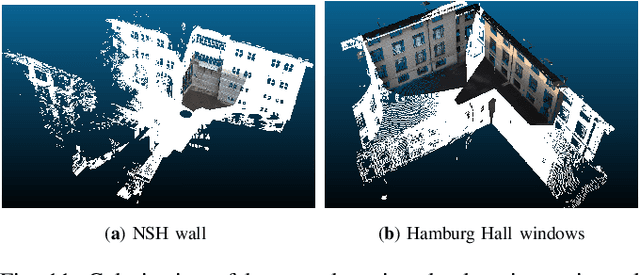
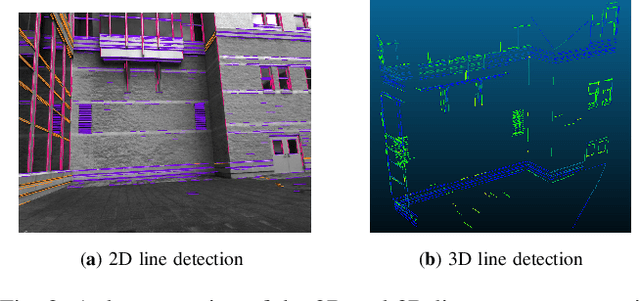
Accurate registration of 2D imagery with point clouds is a key technology for image-LiDAR point cloud fusion, camera to laser scanner calibration and camera localization. Despite continuous improvements, automatic registration of 2D and 3D data without using additional textured information still faces great challenges. In this paper, we propose a new 2D-3D registration method to estimate 2D-3D line feature correspondences and the camera pose in untextured point clouds of structured environments. Specifically, we first use geometric constraints between vanishing points and 3D parallel lines to compute all feasible camera rotations. Then, we utilize a hypothesis testing strategy to estimate the 2D-3D line correspondences and the translation vector. By checking the consistency with computed correspondences, the best rotation matrix can be found. Finally, the camera pose is further refined using non-linear optimization with all the 2D-3D line correspondences. The experimental results demonstrate the effectiveness of the proposed method on the synthetic and real dataset (outdoors and indoors) with repeated structures and rapid depth changes.
Deep-Learning Assisted High-Resolution Binocular Stereo Depth Reconstruction
Nov 23, 2019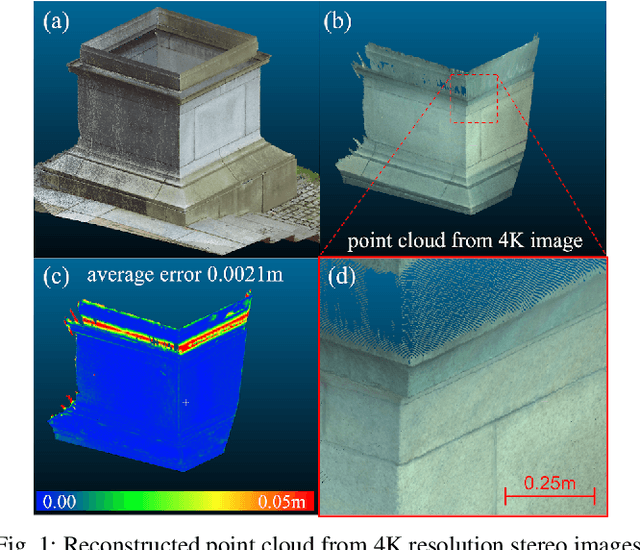
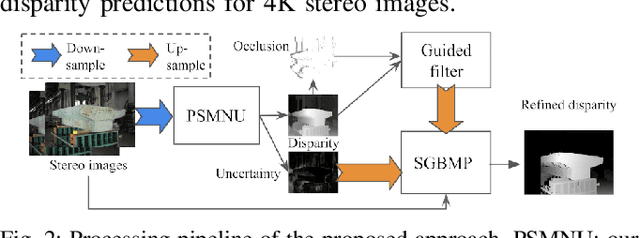


This work presents dense stereo reconstruction using high-resolution images for infrastructure inspections. The state-of-the-art stereo reconstruction methods, both learning and non-learning ones, consume too much computational resource on high-resolution data. Recent learning-based methods achieve top ranks on most benchmarks. However, they suffer from the generalization issue due to lack of task-specific training data. We propose to use a less resource demanding non-learning method, guided by a learning-based model, to handle high-resolution images and achieve accurate stereo reconstruction. The deep-learning model produces an initial disparity prediction with uncertainty for each pixel of the down-sampled stereo image pair. The uncertainty serves as a self-measurement of its generalization ability and the per-pixel searching range around the initially predicted disparity. The downstream process performs a modified version of the Semi-Global Block Matching method with the up-sampled per-pixel searching range. The proposed deep-learning assisted method is evaluated on the Middlebury dataset and high-resolution stereo images collected by our customized binocular stereo camera. The combination of learning and non-learning methods achieves better performance on 12 out of 15 cases of the Middlebury dataset. In our infrastructure inspection experiments, the average 3D reconstruction error is less than 0.004m.
LiDAR Enhanced Structure-from-Motion
Nov 08, 2019

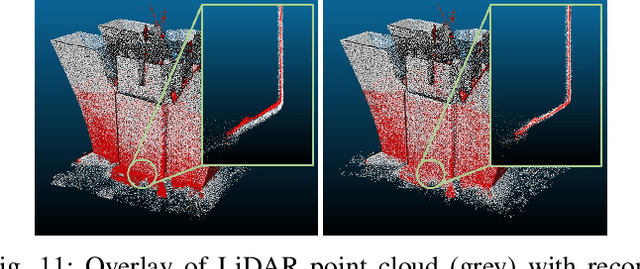
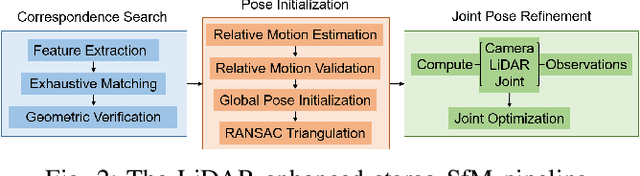
Although Structure-from-Motion (SfM) as a maturing technique has been widely used in many applications, state-of-the-art SfM algorithms are still not robust enough in certain situations. For example, images for inspection purposes are often taken in close distance to obtain detailed textures, which will result in less overlap between images and thus decrease the accuracy of estimated motion. In this paper, we propose a LiDAR-enhanced SfM pipeline that jointly processes data from a rotating LiDAR and a stereo camera pair to estimate sensor motions. We show that incorporating LiDAR helps to effectively reject falsely matched images and significantly improve the model consistency in large-scale environments. Experiments are conducted in different environments to test the performance of the proposed pipeline and comparison results with the state-of-the-art SfM algorithms are reported.
A Joint Optimization Approach of LiDAR-Camera Fusion for Accurate Dense 3D Reconstructions
Jul 01, 2019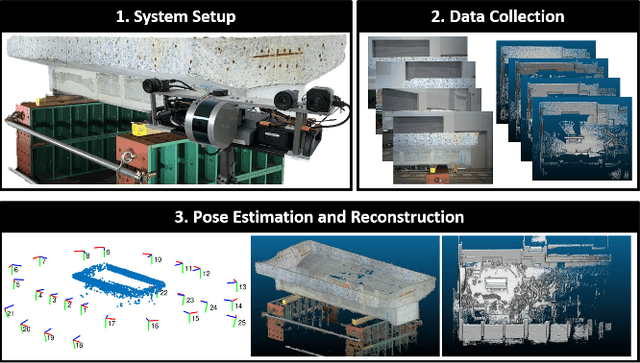

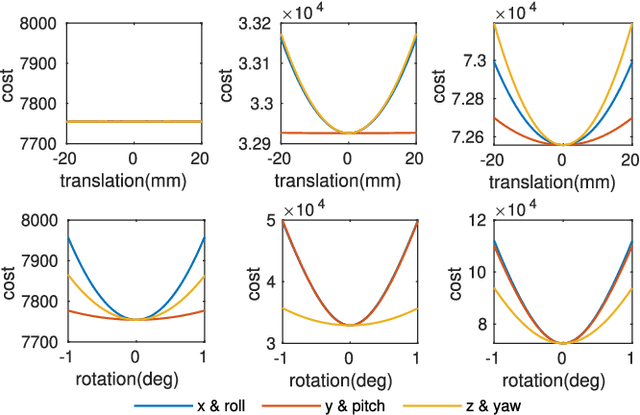
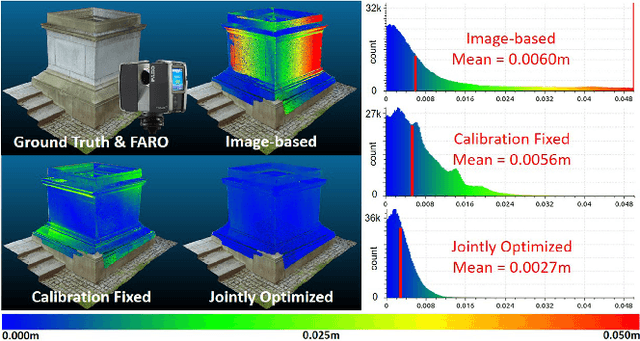
Fusing data from LiDAR and camera is conceptually attractive because of their complementary properties. For instance, camera images are higher resolution and have colors, while LiDAR data provide more accurate range measurements and have a wider Field Of View (FOV). However, the sensor fusion problem remains challenging since it is difficult to find reliable correlations between data of very different characteristics (geometry vs. texture, sparse vs. dense). This paper proposes an offline LiDAR-camera fusion method to build dense, accurate 3D models. Specifically, our method jointly solves a bundle adjustment (BA) problem and a cloud registration problem to compute camera poses and the sensor extrinsic calibration. In experiments, we show that our method can achieve an averaged accuracy of 2.7mm and resolution of 70 points per square cm by comparing to the ground truth data from a survey scanner. Furthermore, the extrinsic calibration result is discussed and shown to outperform the state-of-the-art method.
A Unified 3D Mapping Framework using a 3D or 2D LiDAR
Oct 30, 2018

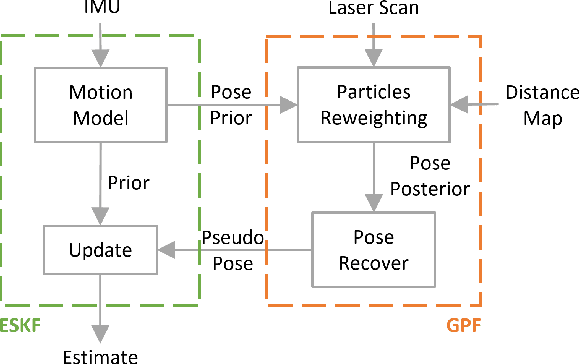
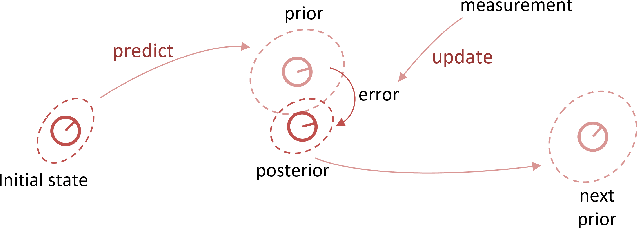
Simultaneous Localization and Mapping (SLAM) has been considered as a solved problem thanks to the progress made in the past few years. However, the great majority of LiDAR-based SLAM algorithms are designed for a specific type of payload and therefore don't generalize across different platforms. In practice, this drawback causes the development, deployment and maintenance of an algorithm difficult. Consequently, our work focuses on improving the compatibility across different sensing payloads. Specifically, we extend the Cartographer SLAM library to handle different types of LiDAR including fixed or rotating, 2D or 3D LiDARs. By replacing the localization module of Cartographer and maintaining the sparse pose graph (SPG), the proposed framework can create high-quality 3D maps in real-time on different sensing payloads. Additionally, it brings the benefit of simplicity with only a few parameters need to be adjusted for each sensor type.