 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Detection of Baby Cry
Apr 19, 2023



Detection of baby cries is an important part of baby monitoring and health care. Almost all existing methods use supervised SVM, CNN, or their varieties. In this work, we propose to use weakly supervised anomaly detection to detect a baby cry. In this weak supervision, we only need weak annotation if there is a cry in an audio file. We design a data mining technique using the pre-trained VGGish feature extractor and an anomaly detection network on long untrimmed audio files. The obtained datasets are used to train a simple CNN feature network for cry/non-cry classification. This CNN is then used as a feature extractor in an anomaly detection framework to achieve better cry detection performance.
Overlooked Video Classification in Weakly Supervised Video Anomaly Detection
Oct 13, 2022

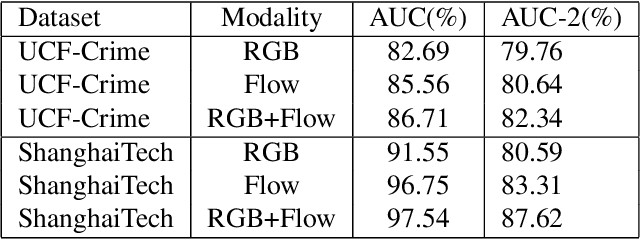
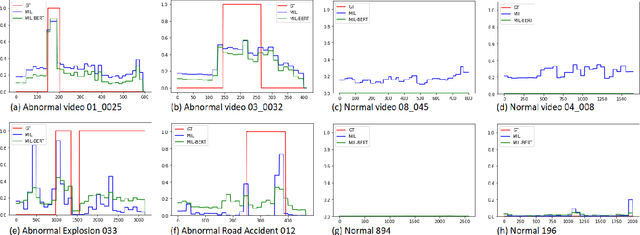
Current weakly supervised video anomaly detection algorithms mostly use multiple instance learning (MIL) or their varieties. Almost all recent approaches focus on how to select the correct snippets for training to improve the performance. They overlook or do not realize the power of video classification in boosting the performance of anomaly detection. In this paper, we study explicitly the power of video classification supervision using a BERT or LSTM. With this BERT or LSTM, CNN features of all snippets of a video can be aggregated into a single feature which can be used for video classification. This simple yet powerful video classification supervision, combined into the MIL framework, brings extraordinary performance improvement on all three major video anomaly detection datasets. Particularly it improves the mean average precision (mAP) on the XD-Violence from SOTA 78.84\% to new 82.10\%. The source code is available at https://github.com/wjtan99/BERT_Anomaly_Video_Classification.
Two-Stage COVID19 Classification Using BERT Features
Jun 29, 2022
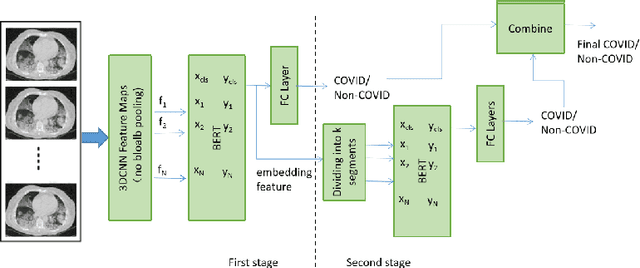
We propose an automatic COVID1-19 diagnosis framework from lung CT-scan slice images using double BERT feature extraction. In the first BERT feature extraction, A 3D-CNN is first used to extract CNN internal feature maps. Instead of using the global average pooling, a late BERT temporal pooing is used to aggregate the temporal information in these feature maps, followed by a classification layer. This 3D-CNN-BERT classification network is first trained on sampled fixed number of slice images from every original CT scan volume. In the second stage, the 3D-CNN-BERT embedding features are extracted on all slice images of every CT scan volume, and these features are averaged into a fixed number of segments. Then another BERT network is used to aggregate these multiple features into a single feature followed by another classification layer. The classification results of both stages are combined to generate final outputs. On the validation dataset, we achieve macro F1 score of 0.9164.
Detection of Fights in Videos: A Comparison Study of Anomaly Detection and Action Recognition
May 23, 2022
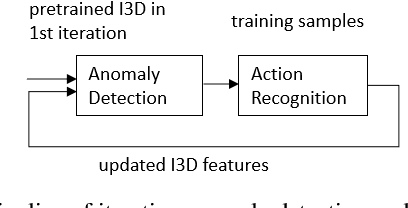
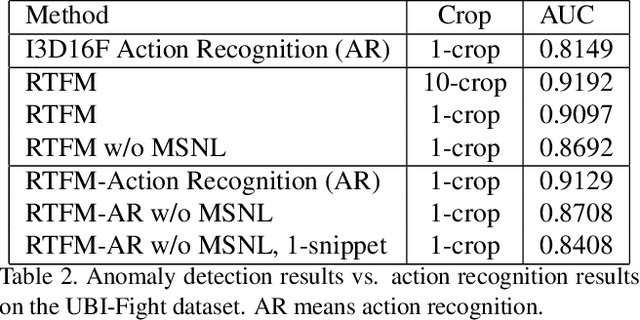
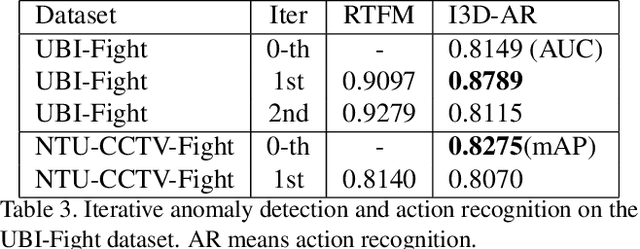
Detection of fights is an important surveillance application in videos. Most existing methods use supervised binary action recognition. Since frame-level annotations are very hard to get for anomaly detection, weakly supervised learning using multiple instance learning is widely used. This paper explores the detection of fights in videos as one special type of anomaly detection and as binary action recognition. We use the UBI-Fight and NTU-CCTV-Fight datasets for most of the study since they have frame-level annotations. We find that the anomaly detection has similar or even better performance than the action recognition. Furthermore, we study to use anomaly detection as a toolbox to generate training datasets for action recognition in an iterative way conditioned on the performance of the anomaly detection. Experiment results should show that we achieve state-of-the-art performance on three fight detection datasets.
Balanced Masked and Standard Face Recognition
Oct 04, 2021
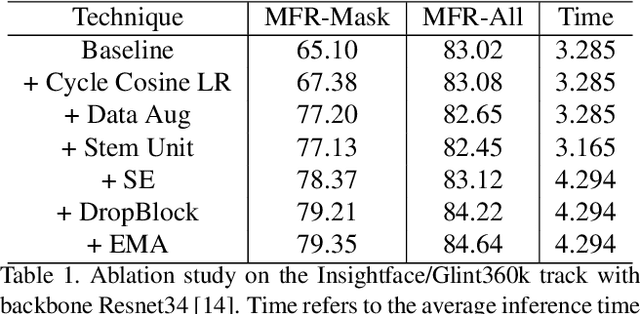

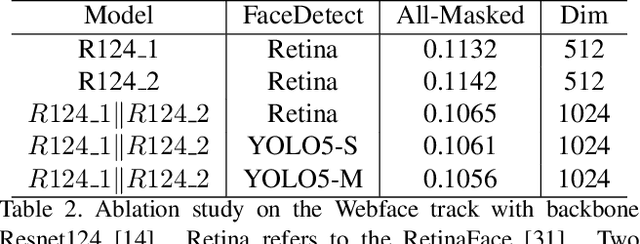
We present the improved network architecture, data augmentation, and training strategies for the Webface track and Insightface/Glint360K track of the masked face recognition challenge of ICCV2021. One of the key goals is to have a balanced performance of masked and standard face recognition. In order to prevent the overfitting for the masked face recognition, we control the total number of masked faces by not more than 10\% of the total face recognition in the training dataset. We propose a few key changes to the face recognition network including a new stem unit, drop block, face detection and alignment using YOLO5Face, feature concatenation, a cycle cosine learning rate, etc. With this strategy, we achieve good and balanced performance for both masked and standard face recognition.
A 3D CNN Network with BERT For Automatic COVID-19 Diagnosis From CT-Scan Images
Jun 28, 2021

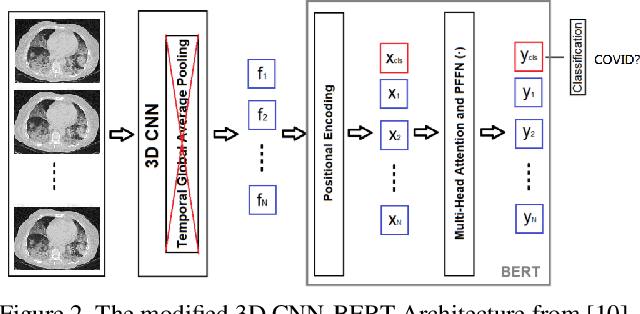

We present an automatic COVID1-19 diagnosis framework from lung CT-scan slice images. In this framework, the slice images of a CT-scan volume are first proprocessed using segmentation techniques to filter out images of closed lung, and to remove the useless background. Then a resampling method is used to select one or multiple sets of a fixed number of slice images for training and validation. A 3D CNN network with BERT is used to classify this set of selected slice images. In this network, an embedding feature is also extracted. In cases where there are more than one set of slice images in a volume, the features of all sets are extracted and pooled into a global feature vector for the whole CT-scan volume. A simple multiple-layer perceptron (MLP) network is used to further classify the aggregated feature vector. The models are trained and evaluated on the provided training and validation datasets. On the validation dataset, the accuracy is 0.9278 and the F1 score is 0.9261.
YOLO5Face: Why Reinventing a Face Detector
May 27, 2021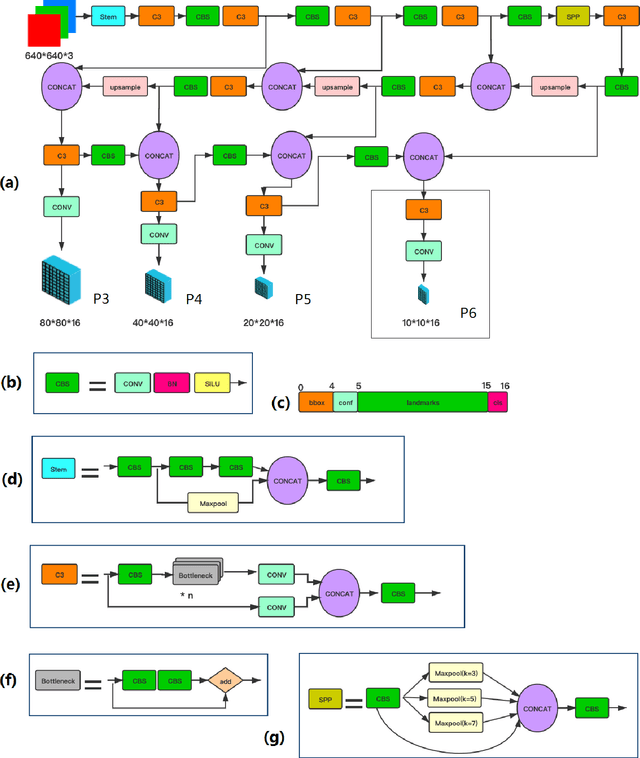
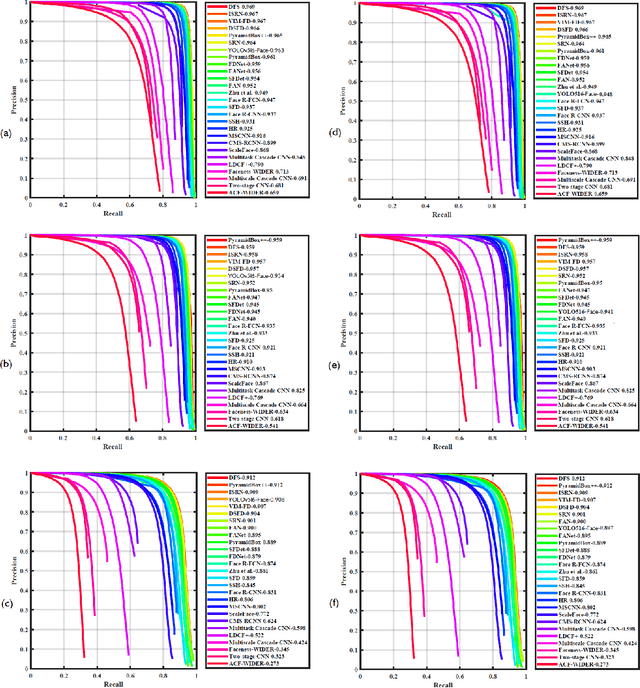
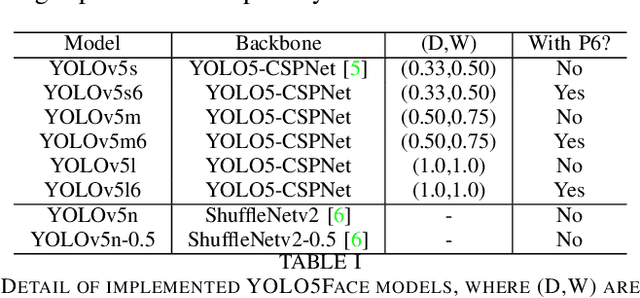

Tremendous progress has been made on face detection in recent years using convolutional neural networks. While many face detectors use designs designated for the detection of face, we treat face detection as a general object detection task. We implement a face detector based on YOLOv5 object detector and call it YOLO5Face. We add a five-point landmark regression head into it and use the Wing loss function. We design detectors with different model sizes, from a large model to achieve the best performance, to a super small model for real-time detection on an embedded or mobile device. Experiment results on the WiderFace dataset show that our face detectors can achieve state-of-the-art performance in almost all the Easy, Medium, and Hard subsets, exceeding the more complex designated face detectors. The code is available at \url{https://www.github.com/deepcam-cn/yolov5-face}.
A Gun Detection Dataset and Searching for Embedded Device Solutions
May 03, 2021

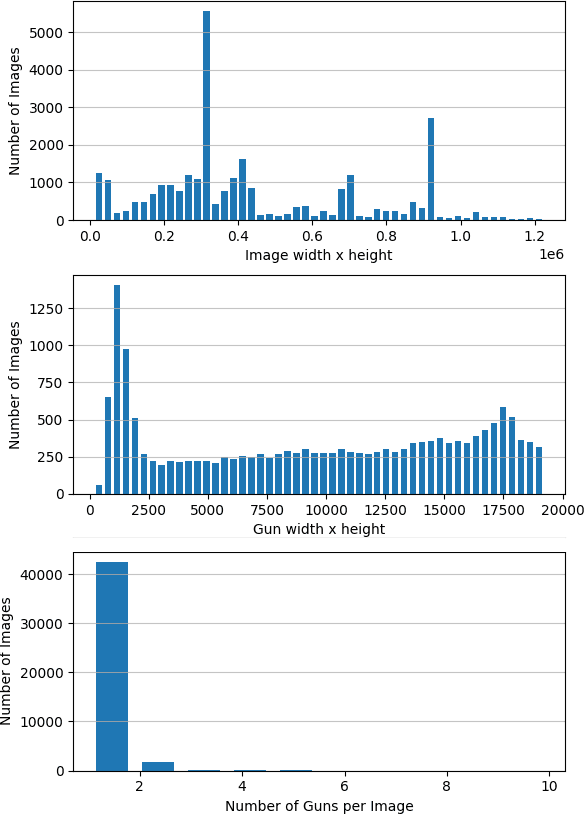
Gun violence is a severe problem in the world, particularly in the United States. Computer vision methods have been studied to detect guns in surveillance video cameras or smart IP cameras and to send a real-time alert to safety personals. However, due to no public datasets, it is hard to benchmark how well such methods work in real applications. In this paper we publish a dataset with 51K annotated gun images for gun detection and other 51K cropped gun chip images for gun classification we collect from a few different sources. To our knowledge, this is the largest dataset for the study of gun detection. This dataset can be downloaded at www.linksprite.com/gun-detection-datasets. We also study to search for solutions for gun detection in embedded edge device (camera) and a gun/non-gun classification on a cloud server. This edge/cloud framework makes possible the deployment of gun detection in the real world.
A Joint Optimization Approach of LiDAR-Camera Fusion for Accurate Dense 3D Reconstructions
Jul 01, 2019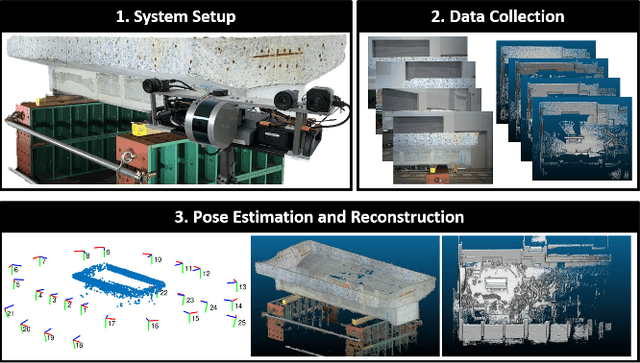

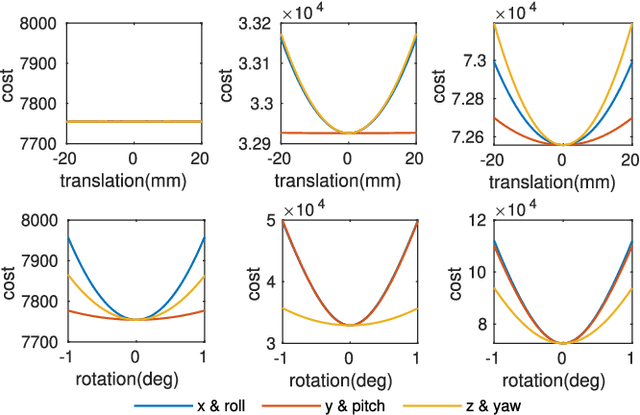
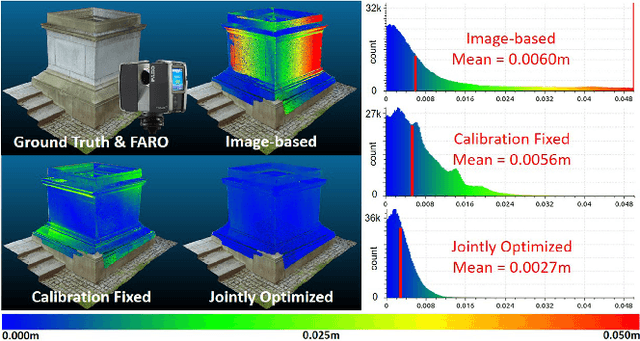
Fusing data from LiDAR and camera is conceptually attractive because of their complementary properties. For instance, camera images are higher resolution and have colors, while LiDAR data provide more accurate range measurements and have a wider Field Of View (FOV). However, the sensor fusion problem remains challenging since it is difficult to find reliable correlations between data of very different characteristics (geometry vs. texture, sparse vs. dense). This paper proposes an offline LiDAR-camera fusion method to build dense, accurate 3D models. Specifically, our method jointly solves a bundle adjustment (BA) problem and a cloud registration problem to compute camera poses and the sensor extrinsic calibration. In experiments, we show that our method can achieve an averaged accuracy of 2.7mm and resolution of 70 points per square cm by comparing to the ground truth data from a survey scanner. Furthermore, the extrinsic calibration result is discussed and shown to outperform the state-of-the-art method.