 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet Me Think! A Long Chain-of-Thought Can Be Worth Exponentially Many Short Ones
May 27, 2025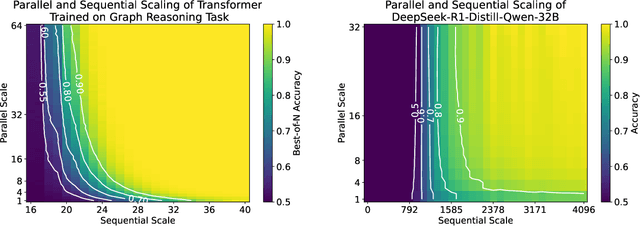

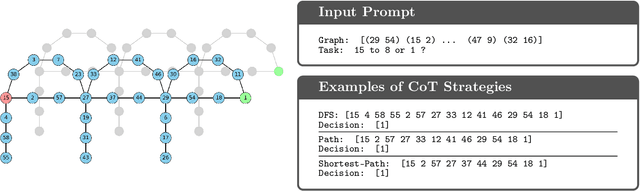
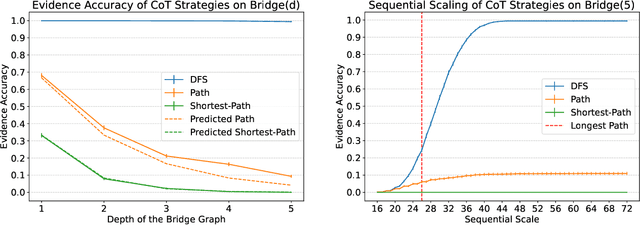
Inference-time computation has emerged as a promising scaling axis for improving large language model reasoning. However, despite yielding impressive performance, the optimal allocation of inference-time computation remains poorly understood. A central question is whether to prioritize sequential scaling (e.g., longer chains of thought) or parallel scaling (e.g., majority voting across multiple short chains of thought). In this work, we seek to illuminate the landscape of test-time scaling by demonstrating the existence of reasoning settings where sequential scaling offers an exponential advantage over parallel scaling. These settings are based on graph connectivity problems in challenging distributions of graphs. We validate our theoretical findings with comprehensive experiments across a range of language models, including models trained from scratch for graph connectivity with different chain of thought strategies as well as large reasoning models.
Direct Alignment with Heterogeneous Preferences
Feb 22, 2025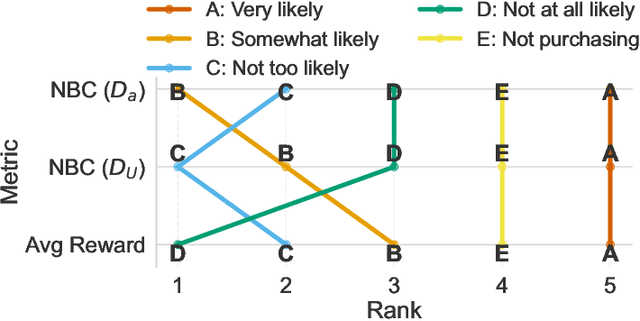

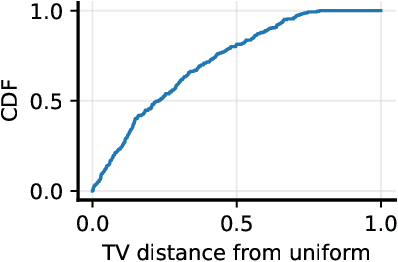
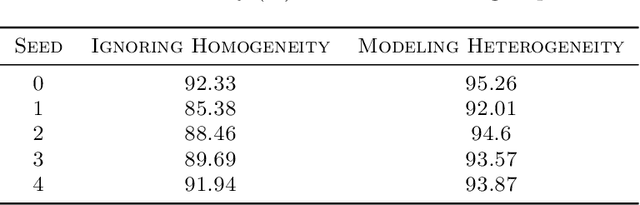
Alignment with human preferences is commonly framed using a universal reward function, even though human preferences are inherently heterogeneous. We formalize this heterogeneity by introducing user types and examine the limits of the homogeneity assumption. We show that aligning to heterogeneous preferences with a single policy is best achieved using the average reward across user types. However, this requires additional information about annotators. We examine improvements under different information settings, focusing on direct alignment methods. We find that minimal information can yield first-order improvements, while full feedback from each user type leads to consistent learning of the optimal policy. Surprisingly, however, no sample-efficient consistent direct loss exists in this latter setting. These results reveal a fundamental tension between consistency and sample efficiency in direct policy alignment.