 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Alignment with Heterogeneous Preferences
Feb 22, 2025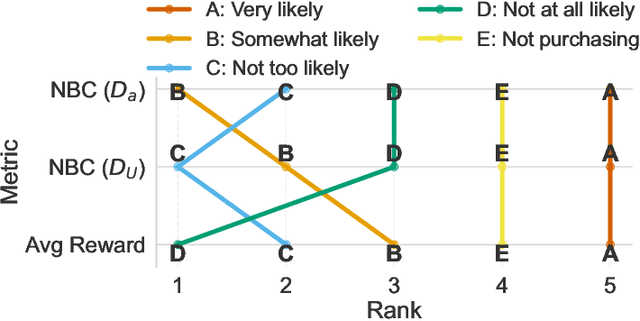

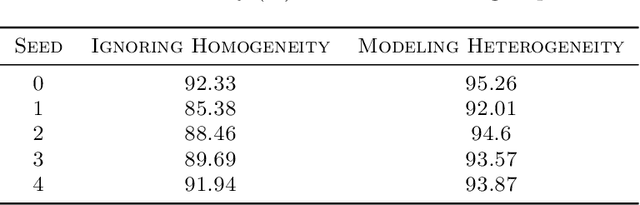
Alignment with human preferences is commonly framed using a universal reward function, even though human preferences are inherently heterogeneous. We formalize this heterogeneity by introducing user types and examine the limits of the homogeneity assumption. We show that aligning to heterogeneous preferences with a single policy is best achieved using the average reward across user types. However, this requires additional information about annotators. We examine improvements under different information settings, focusing on direct alignment methods. We find that minimal information can yield first-order improvements, while full feedback from each user type leads to consistent learning of the optimal policy. Surprisingly, however, no sample-efficient consistent direct loss exists in this latter setting. These results reveal a fundamental tension between consistency and sample efficiency in direct policy alignment.
Lawma: The Power of Specialization for Legal Tasks
Jul 23, 2024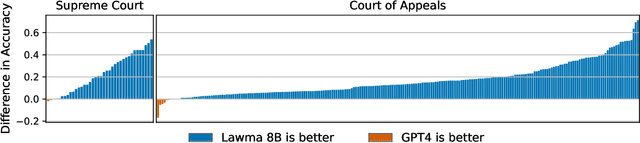


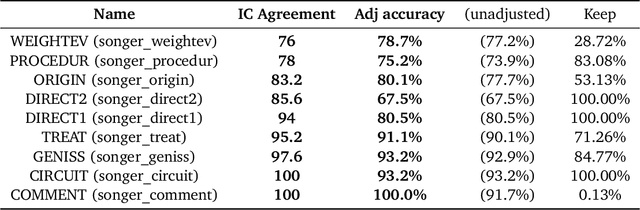
Annotation and classification of legal text are central components of empirical legal research. Traditionally, these tasks are often delegated to trained research assistants. Motivated by the advances in language modeling, empirical legal scholars are increasingly turning to prompting commercial models, hoping that it will alleviate the significant cost of human annotation. Despite growing use, our understanding of how to best utilize large language models for legal tasks remains limited. We conduct a comprehensive study of 260 legal text classification tasks, nearly all new to the machine learning community. Starting from GPT-4 as a baseline, we show that it has non-trivial but highly varied zero-shot accuracy, often exhibiting performance that may be insufficient for legal work. We then demonstrate that a lightly fine-tuned Llama 3 model vastly outperforms GPT-4 on almost all tasks, typically by double-digit percentage points. We find that larger models respond better to fine-tuning than smaller models. A few tens to hundreds of examples suffice to achieve high classification accuracy. Notably, we can fine-tune a single model on all 260 tasks simultaneously at a small loss in accuracy relative to having a separate model for each task. Our work points to a viable alternative to the predominant practice of prompting commercial models. For concrete legal tasks with some available labeled data, researchers are better off using a fine-tuned open-source model.
Allocation Requires Prediction Only if Inequality Is Low
Jun 19, 2024
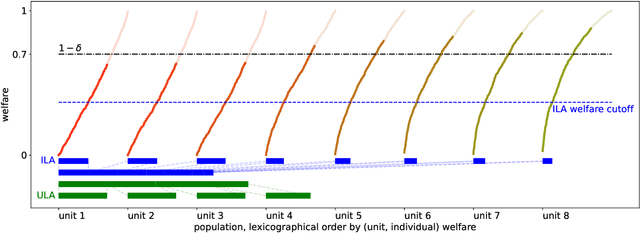
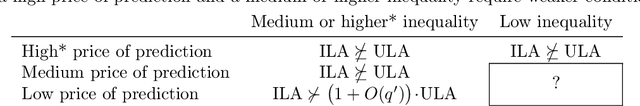

Algorithmic predictions are emerging as a promising solution concept for efficiently allocating societal resources. Fueling their use is an underlying assumption that such systems are necessary to identify individuals for interventions. We propose a principled framework for assessing this assumption: Using a simple mathematical model, we evaluate the efficacy of prediction-based allocations in settings where individuals belong to larger units such as hospitals, neighborhoods, or schools. We find that prediction-based allocations outperform baseline methods using aggregate unit-level statistics only when between-unit inequality is low and the intervention budget is high. Our results hold for a wide range of settings for the price of prediction, treatment effect heterogeneity, and unit-level statistics' learnability. Combined, we highlight the potential limits to improving the efficacy of interventions through prediction.
When the Majority is Wrong: Modeling Annotator Disagreement for Subjective Tasks
May 24, 2023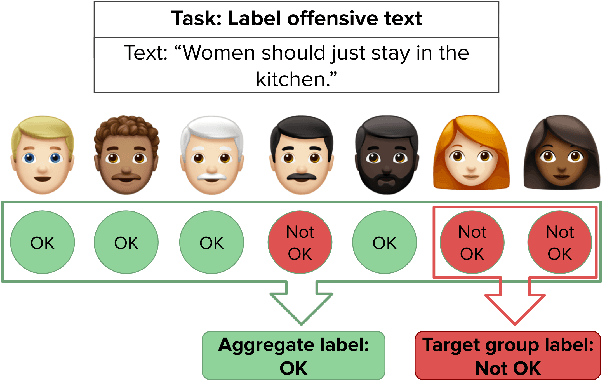
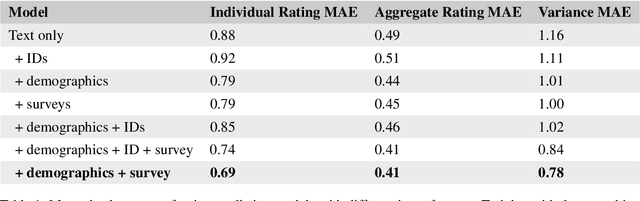

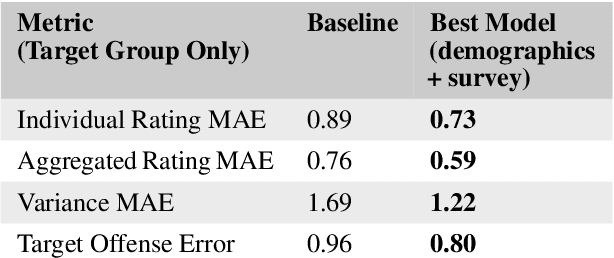
Though majority vote among annotators is typically used for ground truth labels in natural language processing, annotator disagreement in tasks such as hate speech detection may reflect differences in opinion across groups, not noise. Thus, a crucial problem in hate speech detection is determining whether a statement is offensive to the demographic group that it targets, when that group may constitute a small fraction of the annotator pool. We construct a model that predicts individual annotator ratings on potentially offensive text and combines this information with the predicted target group of the text to model the opinions of target group members. We show gains across a range of metrics, including raising performance over the baseline by 22% at predicting individual annotators' ratings and by 33% at predicting variance among annotators, which provides a metric for model uncertainty downstream. We find that annotator ratings can be predicted using their demographic information and opinions on online content, without the need to track identifying annotator IDs that link each annotator to their ratings. We also find that use of non-invasive survey questions on annotators' online experiences helps to maximize privacy and minimize unnecessary collection of demographic information when predicting annotators' opinions.
Difficult Lessons on Social Prediction from Wisconsin Public Schools
Apr 13, 2023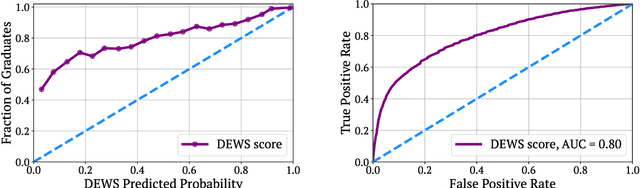

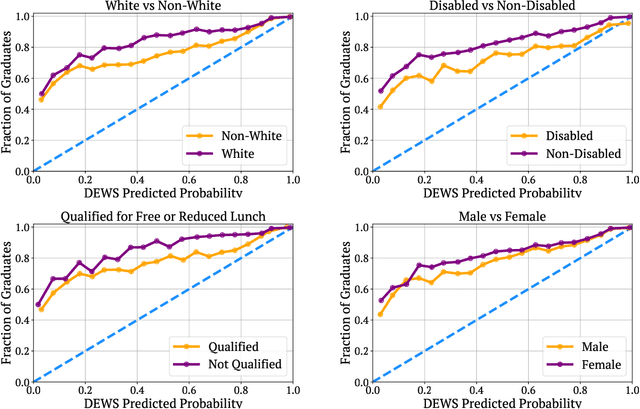
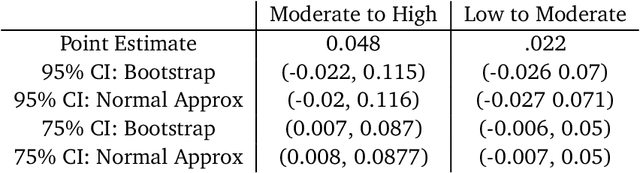
Early warning systems (EWS) are prediction algorithms that have recently taken a central role in efforts to improve graduation rates in public schools across the US. These systems assist in targeting interventions at individual students by predicting which students are at risk of dropping out. Despite significant investments and adoption, there remain significant gaps in our understanding of the efficacy of EWS. In this work, we draw on nearly a decade's worth of data from a system used throughout Wisconsin to provide the first large-scale evaluation of the long-term impact of EWS on graduation outcomes. We present evidence that risk assessments made by the prediction system are highly accurate, including for students from marginalized backgrounds. Despite the system's accuracy and widespread use, we find no evidence that it has led to improved graduation rates. We surface a robust statistical pattern that can explain why these seemingly contradictory insights hold. Namely, environmental features, measured at the level of schools, contain significant signal about dropout risk. Within each school, however, academic outcomes are essentially independent of individual student performance. This empirical observation indicates that assigning all students within the same school the same probability of graduation is a nearly optimal prediction. Our work provides an empirical backbone for the robust, qualitative understanding among education researchers and policy-makers that dropout is structurally determined. The primary barrier to improving outcomes lies not in identifying students at risk of dropping out within specific schools, but rather in overcoming structural differences across different school districts. Our findings indicate that we should carefully evaluate the decision to fund early warning systems without also devoting resources to interventions tackling structural barriers.
A Theory of Dynamic Benchmarks
Oct 06, 2022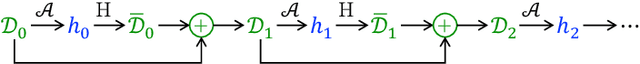
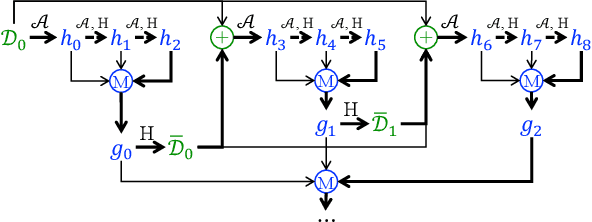
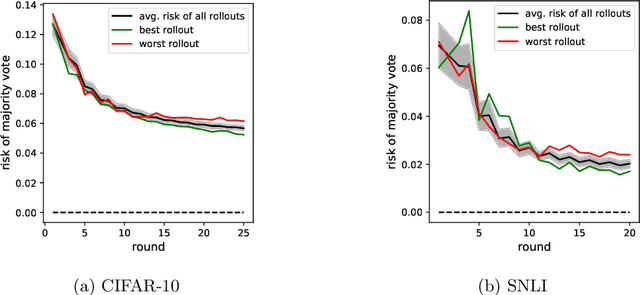
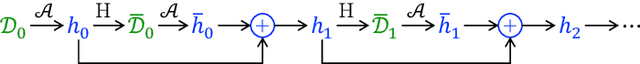
Dynamic benchmarks interweave model fitting and data collection in an attempt to mitigate the limitations of static benchmarks. In contrast to an extensive theoretical and empirical study of the static setting, the dynamic counterpart lags behind due to limited empirical studies and no apparent theoretical foundation to date. Responding to this deficit, we initiate a theoretical study of dynamic benchmarking. We examine two realizations, one capturing current practice and the other modeling more complex settings. In the first model, where data collection and model fitting alternate sequentially, we prove that model performance improves initially but can stall after only three rounds. Label noise arising from, for instance, annotator disagreement leads to even stronger negative results. Our second model generalizes the first to the case where data collection and model fitting have a hierarchical dependency structure. We show that this design guarantees strictly more progress than the first, albeit at a significant increase in complexity. We support our theoretical analysis by simulating dynamic benchmarks on two popular datasets. These results illuminate the benefits and practical limitations of dynamic benchmarking, providing both a theoretical foundation and a causal explanation for observed bottlenecks in empirical work.
Lost in Translation: Reimagining the Machine Learning Life Cycle in Education
Sep 08, 2022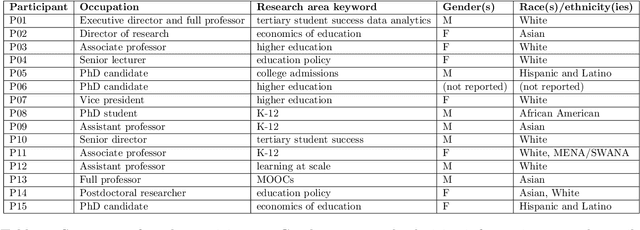
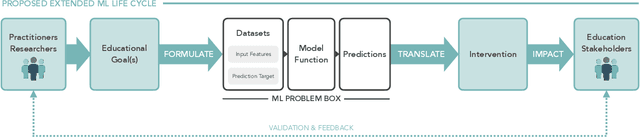
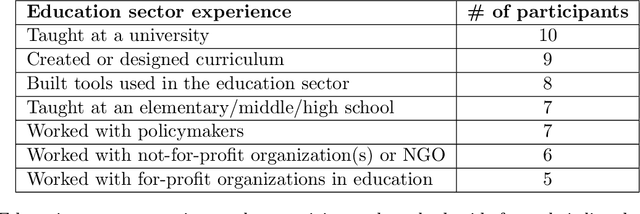
Machine learning (ML) techniques are increasingly prevalent in education, from their use in predicting student dropout, to assisting in university admissions, and facilitating the rise of MOOCs. Given the rapid growth of these novel uses, there is a pressing need to investigate how ML techniques support long-standing education principles and goals. In this work, we shed light on this complex landscape drawing on qualitative insights from interviews with education experts. These interviews comprise in-depth evaluations of ML for education (ML4Ed) papers published in preeminent applied ML conferences over the past decade. Our central research goal is to critically examine how the stated or implied education and societal objectives of these papers are aligned with the ML problems they tackle. That is, to what extent does the technical problem formulation, objectives, approach, and interpretation of results align with the education problem at hand. We find that a cross-disciplinary gap exists and is particularly salient in two parts of the ML life cycle: the formulation of an ML problem from education goals and the translation of predictions to interventions. We use these insights to propose an extended ML life cycle, which may also apply to the use of ML in other domains. Our work joins a growing number of meta-analytical studies across education and ML research, as well as critical analyses of the societal impact of ML. Specifically, it fills a gap between the prevailing technical understanding of machine learning and the perspective of education researchers working with students and in policy.
Adversarial Scrutiny of Evidentiary Statistical Software
Jun 19, 2022
The U.S. criminal legal system increasingly relies on software output to convict and incarcerate people. In a large number of cases each year, the government makes these consequential decisions based on evidence from statistical software -- such as probabilistic genotyping, environmental audio detection, and toolmark analysis tools -- that defense counsel cannot fully cross-examine or scrutinize. This undermines the commitments of the adversarial criminal legal system, which relies on the defense's ability to probe and test the prosecution's case to safeguard individual rights. Responding to this need to adversarially scrutinize output from such software, we propose robust adversarial testing as an audit framework to examine the validity of evidentiary statistical software. We define and operationalize this notion of robust adversarial testing for defense use by drawing on a large body of recent work in robust machine learning and algorithmic fairness. We demonstrate how this framework both standardizes the process for scrutinizing such tools and empowers defense lawyers to examine their validity for instances most relevant to the case at hand. We further discuss existing structural and institutional challenges within the U.S. criminal legal system that may create barriers for implementing this and other such audit frameworks and close with a discussion on policy changes that could help address these concerns.
An Algorithmic Introduction to Savings Circles
Mar 23, 2022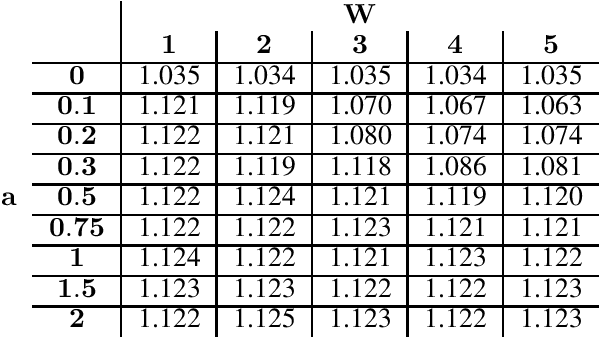
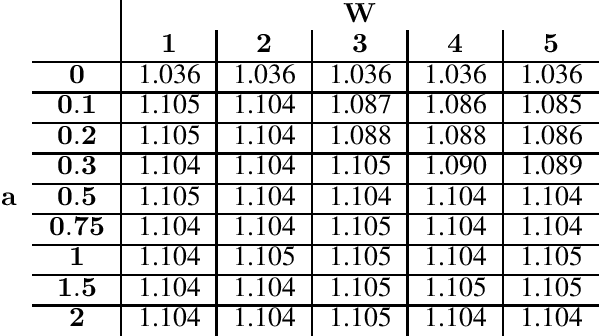
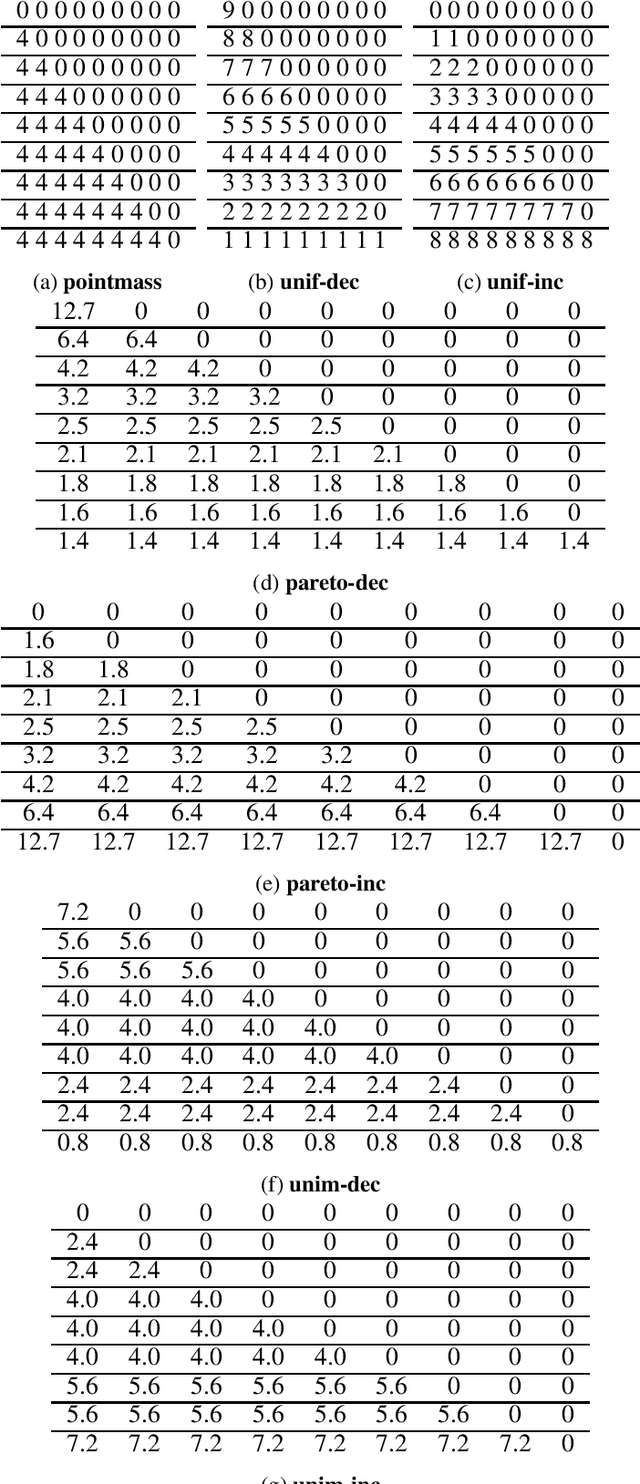
Rotating savings and credit associations (roscas) are informal financial organizations common in settings where communities have reduced access to formal financial institutions. In a rosca, a fixed group of participants regularly contribute sums of money to a pot. This pot is then allocated periodically using lottery, aftermarket, or auction mechanisms. Roscas are empirically well-studied in economics. They are, however, challenging to study theoretically due to their dynamic nature. Typical economic analyses of roscas stop at coarse ordinal welfare comparisons to other credit allocation mechanisms, leaving much of roscas' ubiquity unexplained. In this work, we take an algorithmic perspective on the study of roscas. Building on techniques from the price of anarchy literature, we present worst-case welfare approximation guarantees. We further experimentally compare the welfare of outcomes as key features of the environment vary. These cardinal welfare analyses further rationalize the prevalence of roscas. We conclude by discussing several other promising avenues.
Quantifying Community Characteristics of Maternal Mortality Using Social Media
Apr 14, 2020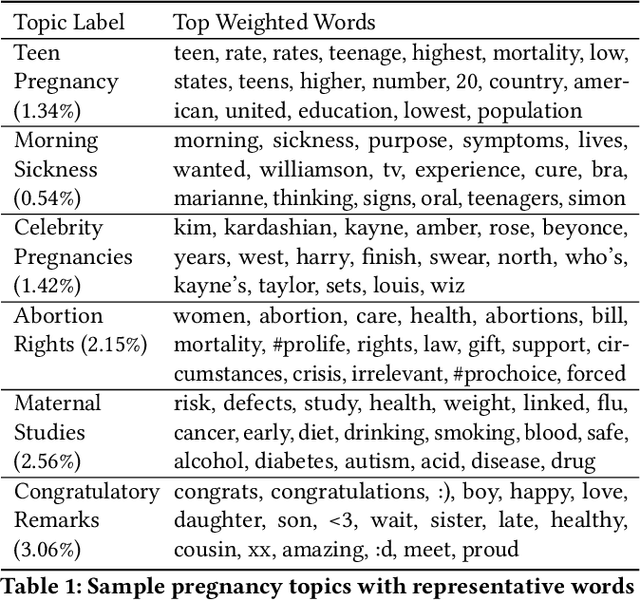
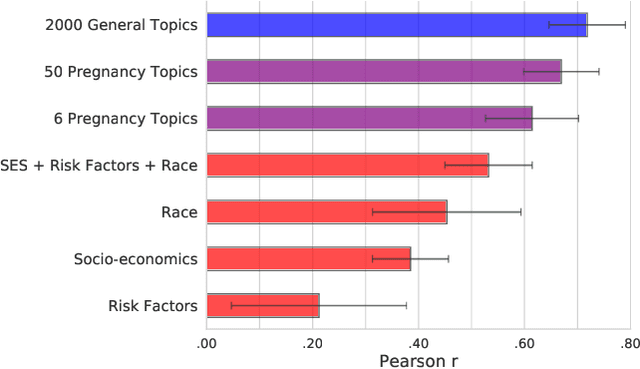
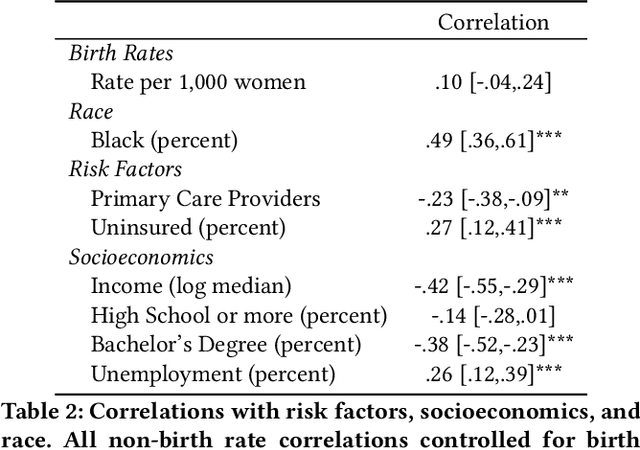
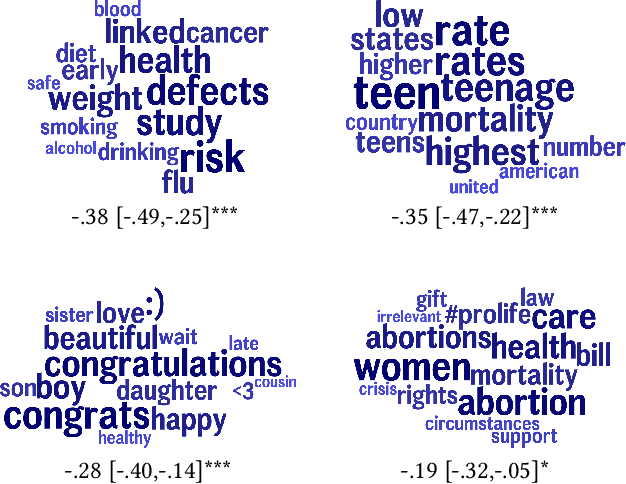
While most mortality rates have decreased in the US, maternal mortality has increased and is among the highest of any OECD nation. Extensive public health research is ongoing to better understand the characteristics of communities with relatively high or low rates. In this work, we explore the role that social media language can play in providing insights into such community characteristics. Analyzing pregnancy-related tweets generated in US counties, we reveal a diverse set of latent topics including Morning Sickness, Celebrity Pregnancies, and Abortion Rights. We find that rates of mentioning these topics on Twitter predicts maternal mortality rates with higher accuracy than standard socioeconomic and risk variables such as income, race, and access to health-care, holding even after reducing the analysis to six topics chosen for their interpretability and connections to known risk factors. We then investigate psychological dimensions of community language, finding the use of less trustful, more stressed, and more negative affective language is significantly associated with higher mortality rates, while trust and negative affect also explain a significant portion of racial disparities in maternal mortality. We discuss the potential for these insights to inform actionable health interventions at the community-level.