 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Community Characteristics of Maternal Mortality Using Social Media
Apr 14, 2020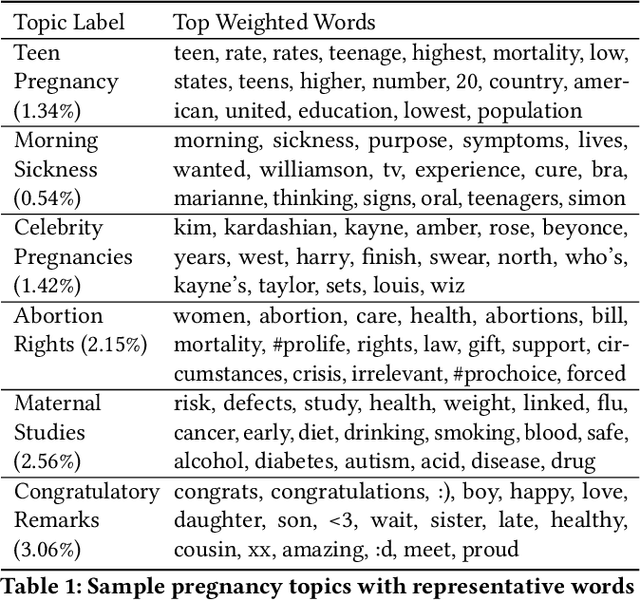
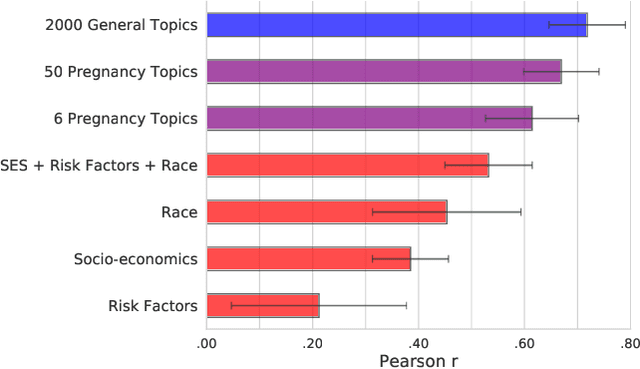
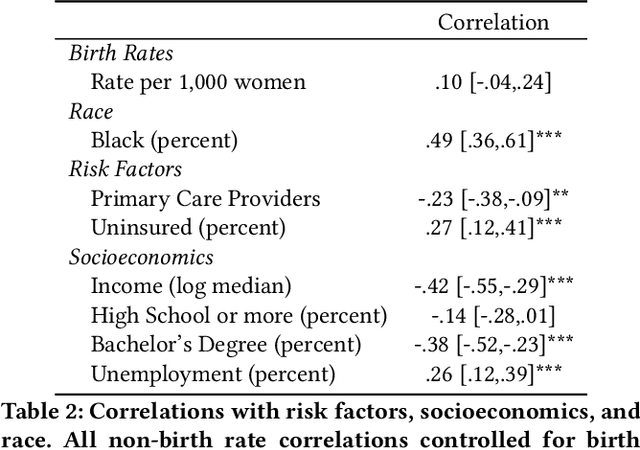
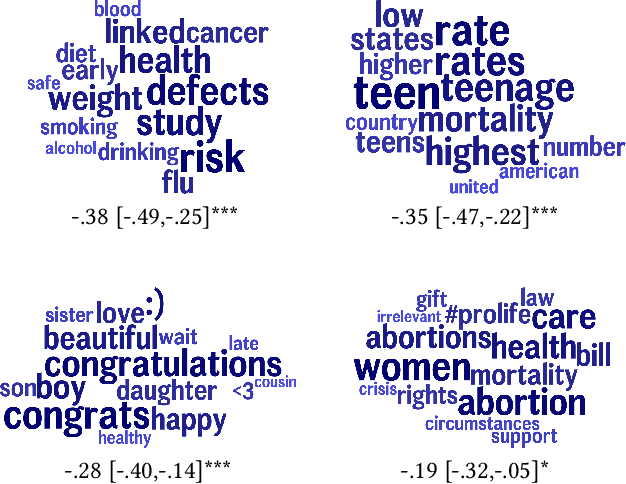
While most mortality rates have decreased in the US, maternal mortality has increased and is among the highest of any OECD nation. Extensive public health research is ongoing to better understand the characteristics of communities with relatively high or low rates. In this work, we explore the role that social media language can play in providing insights into such community characteristics. Analyzing pregnancy-related tweets generated in US counties, we reveal a diverse set of latent topics including Morning Sickness, Celebrity Pregnancies, and Abortion Rights. We find that rates of mentioning these topics on Twitter predicts maternal mortality rates with higher accuracy than standard socioeconomic and risk variables such as income, race, and access to health-care, holding even after reducing the analysis to six topics chosen for their interpretability and connections to known risk factors. We then investigate psychological dimensions of community language, finding the use of less trustful, more stressed, and more negative affective language is significantly associated with higher mortality rates, while trust and negative affect also explain a significant portion of racial disparities in maternal mortality. We discuss the potential for these insights to inform actionable health interventions at the community-level.
Learning Word Ratings for Empathy and Distress from Document-Level User Responses
Dec 02, 2019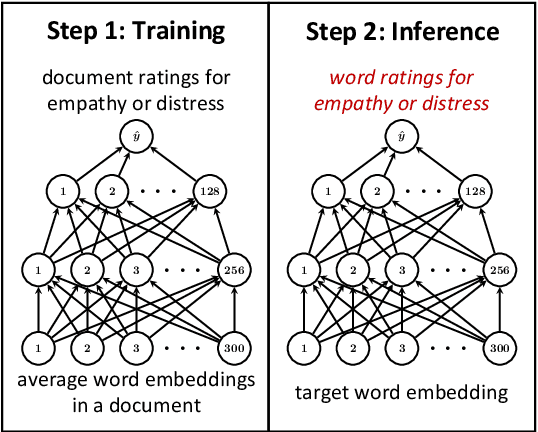
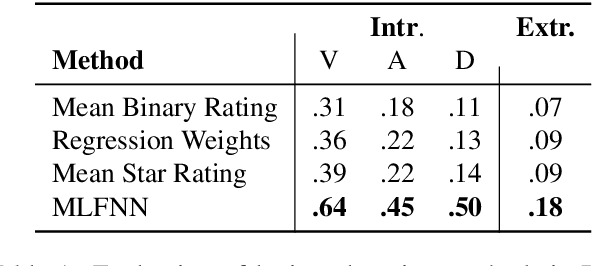
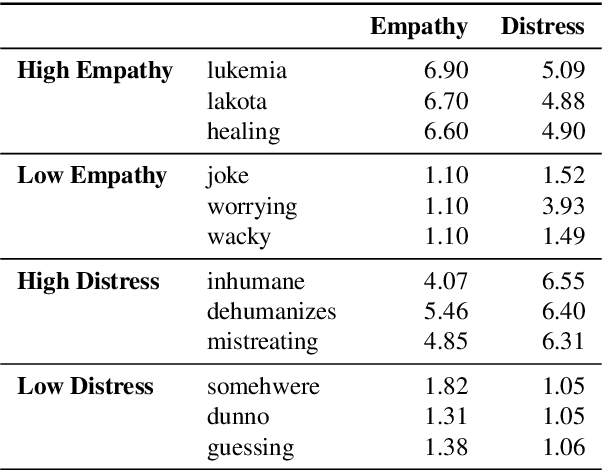
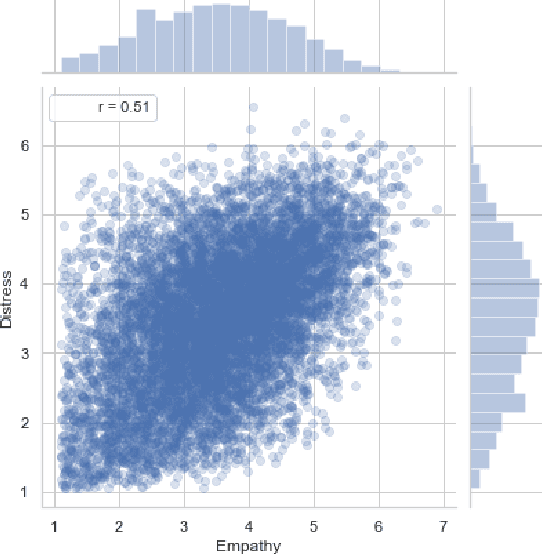
Despite the excellent performance of black box approaches to modeling sentiment and emotion, lexica (sets of informative words and associated weights) that characterize different emotions are indispensable to the NLP community because they allow for interpretable and robust predictions. Emotion analysis of text is increasing in popularity in NLP; however, manually creating lexica for psychological constructs such as empathy has proven difficult. This paper automatically creates empathy word ratings from document-level ratings. The underlying problem of learning word ratings from higher-level supervision has to date only been addressed in an ad hoc fashion and is missing deep learning methods. We systematically compare a number of approaches to learning word ratings from higher-level supervision against a Mixed-Level Feed Forward Network (MLFFN), which we find performs best, and use the MLFFN to create the first-ever empathy lexicon. We then use Signed Spectral Clustering to gain insights into the resulting words.
Understanding and Measuring Psychological Stress using Social Media
Nov 19, 2018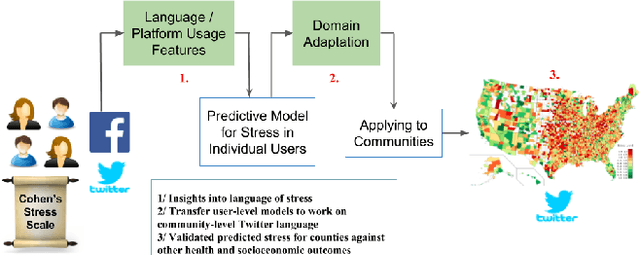


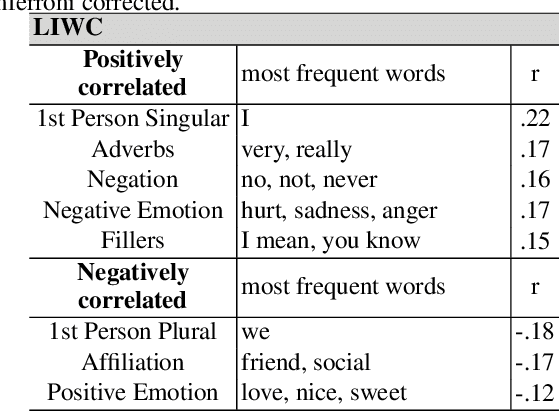
A body of literature has demonstrated that users' mental health conditions, such as depression and anxiety, can be predicted from their social media language. There is still a gap in the scientific understanding of how psychological stress is expressed on social media. Stress is one of the primary underlying causes and correlates of chronic physical illnesses and mental health conditions. In this paper, we explore the language of psychological stress with a dataset of 601 social media users, who answered the Perceived Stress Scale questionnaire and also consented to share their Facebook and Twitter data. Firstly, we find that stressed users post about exhaustion, losing control, increased self-focus and physical pain as compared to posts about breakfast, family-time, and travel by users who are not stressed. Secondly, we find that Facebook language is more predictive of stress than Twitter language. Thirdly, we demonstrate how the language based models thus developed can be adapted and be scaled to measure county-level trends. Since county-level language is easily available on Twitter using the Streaming API, we explore multiple domain adaptation algorithms to adapt user-level Facebook models to Twitter language. We find that domain-adapted and scaled social media-based measurements of stress outperform sociodemographic variables (age, gender, race, education, and income), against ground-truth survey-based stress measurements, both at the user- and the county-level in the U.S. Twitter language that scores higher in stress is also predictive of poorer health, less access to facilities and lower socioeconomic status in counties. We conclude with a discussion of the implications of using social media as a new tool for monitoring stress levels of both individuals and counties.
Modeling Empathy and Distress in Reaction to News Stories
Aug 30, 2018
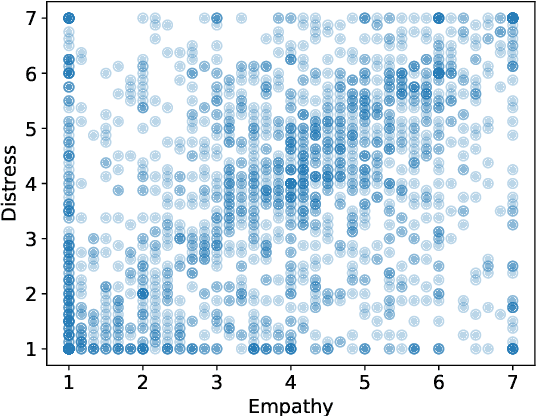

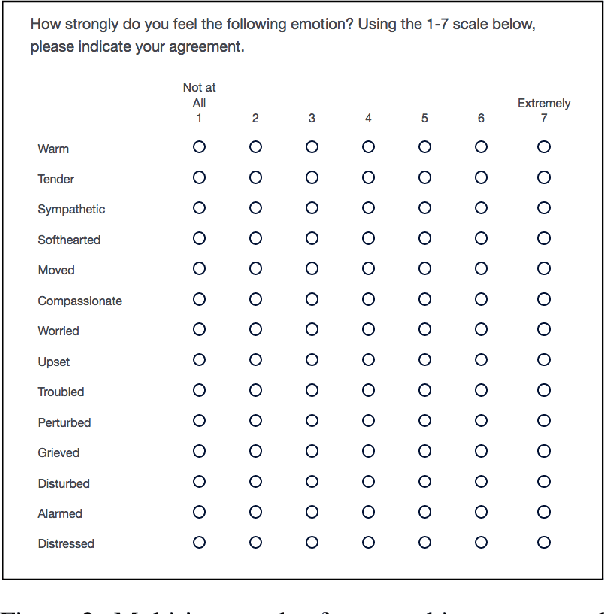
Computational detection and understanding of empathy is an important factor in advancing human-computer interaction. Yet to date, text-based empathy prediction has the following major limitations: It underestimates the psychological complexity of the phenomenon, adheres to a weak notion of ground truth where empathic states are ascribed by third parties, and lacks a shared corpus. In contrast, this contribution presents the first publicly available gold standard for empathy prediction. It is constructed using a novel annotation methodology which reliably captures empathy assessments by the writer of a statement using multi-item scales. This is also the first computational work distinguishing between multiple forms of empathy, empathic concern, and personal distress, as recognized throughout psychology. Finally, we present experimental results for three different predictive models, of which a CNN performs the best.
Predicting Human Trustfulness from Facebook Language
Aug 16, 2018
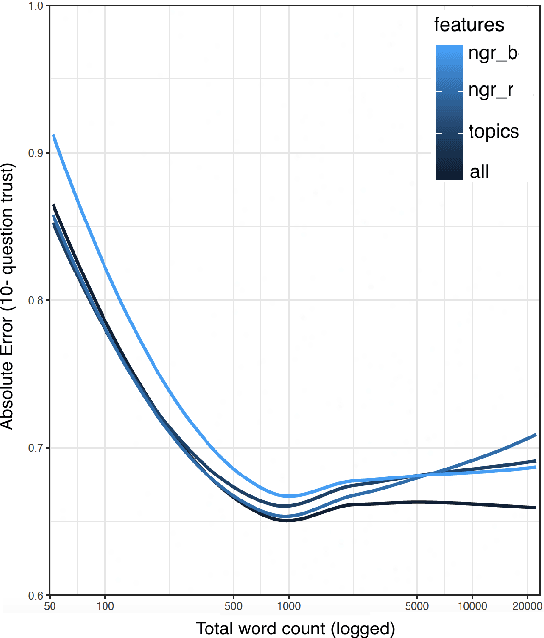
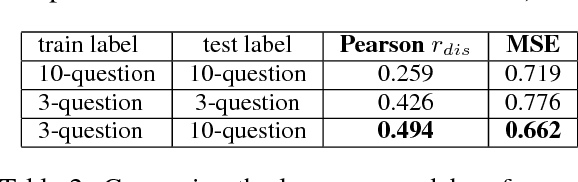
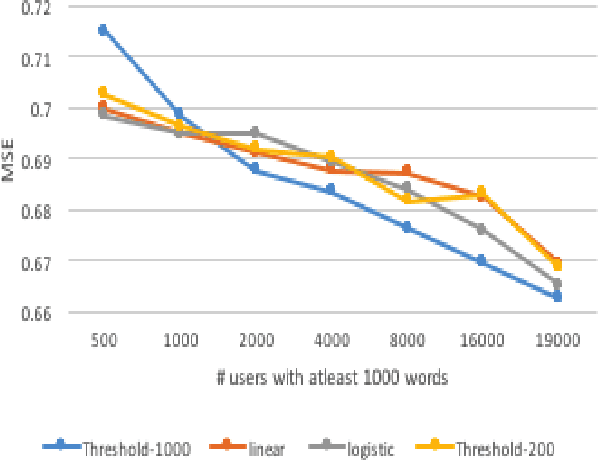
Trustfulness -- one's general tendency to have confidence in unknown people or situations -- predicts many important real-world outcomes such as mental health and likelihood to cooperate with others such as clinicians. While data-driven measures of interpersonal trust have previously been introduced, here, we develop the first language-based assessment of the personality trait of trustfulness by fitting one's language to an accepted questionnaire-based trust score. Further, using trustfulness as a type of case study, we explore the role of questionnaire size as well as word count in developing language-based predictive models of users' psychological traits. We find that leveraging a longer questionnaire can yield greater test set accuracy, while, for training, we find it beneficial to include users who took smaller questionnaires which offers more observations for training. Similarly, after noting a decrease in individual prediction error as word count increased, we found a word count-weighted training scheme was helpful when there were very few users in the first place.
* CLPsych2018