 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion Embeddings $\unicode{x2014}$ Learning Stable and Homogeneous Abstractions from Heterogeneous Affective Datasets
Aug 15, 2023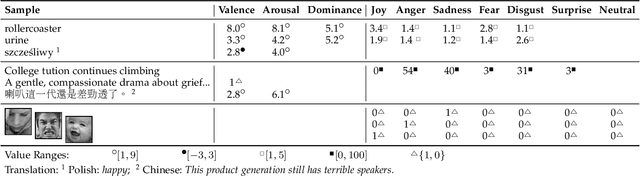
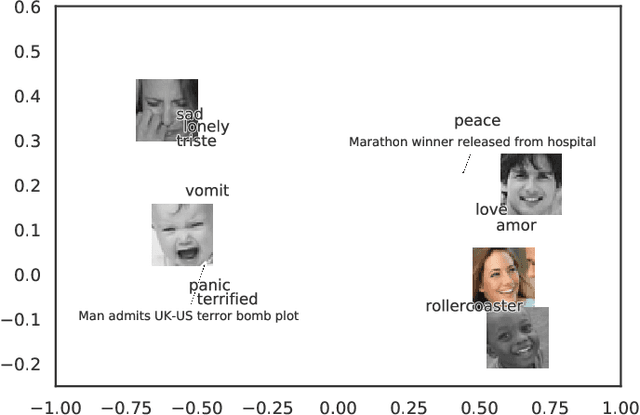
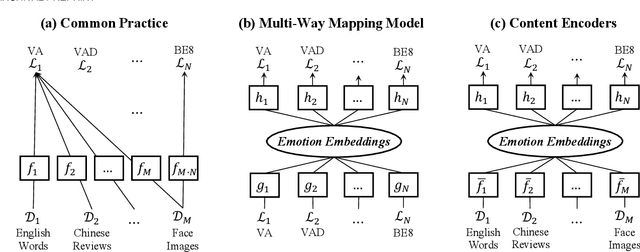
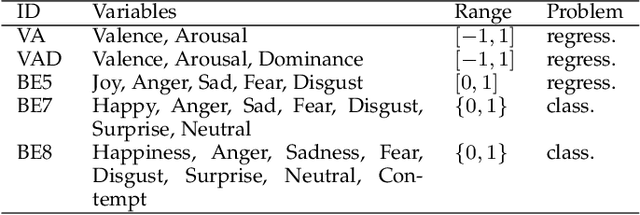
Human emotion is expressed in many communication modalities and media formats and so their computational study is equally diversified into natural language processing, audio signal analysis, computer vision, etc. Similarly, the large variety of representation formats used in previous research to describe emotions (polarity scales, basic emotion categories, dimensional approaches, appraisal theory, etc.) have led to an ever proliferating diversity of datasets, predictive models, and software tools for emotion analysis. Because of these two distinct types of heterogeneity, at the expressional and representational level, there is a dire need to unify previous work on increasingly diverging data and label types. This article presents such a unifying computational model. We propose a training procedure that learns a shared latent representation for emotions, so-called emotion embeddings, independent of different natural languages, communication modalities, media or representation label formats, and even disparate model architectures. Experiments on a wide range of heterogeneous affective datasets indicate that this approach yields the desired interoperability for the sake of reusability, interpretability and flexibility, without penalizing prediction quality. Code and data are archived under https://doi.org/10.5281/zenodo.7405327 .
Empathic Conversations: A Multi-level Dataset of Contextualized Conversations
May 25, 2022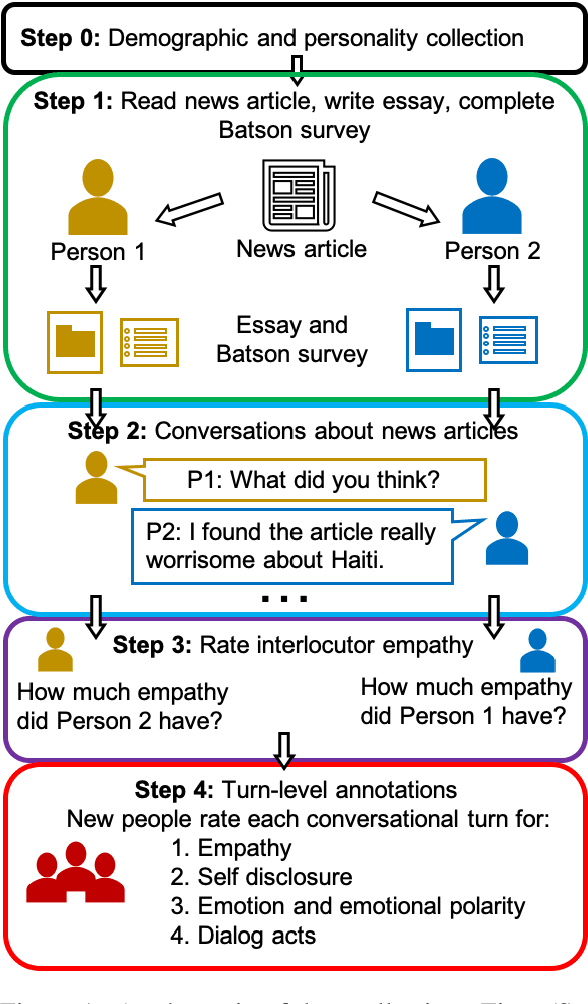
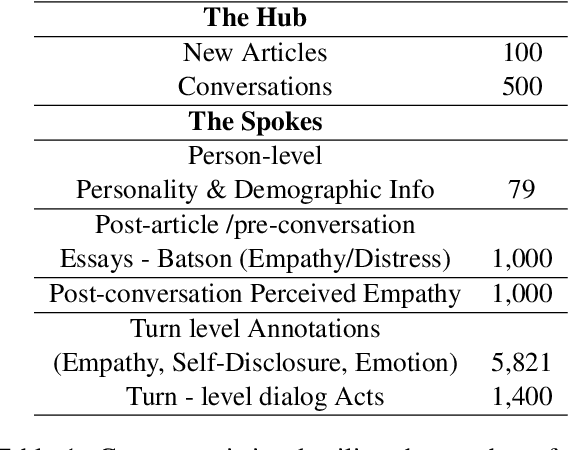
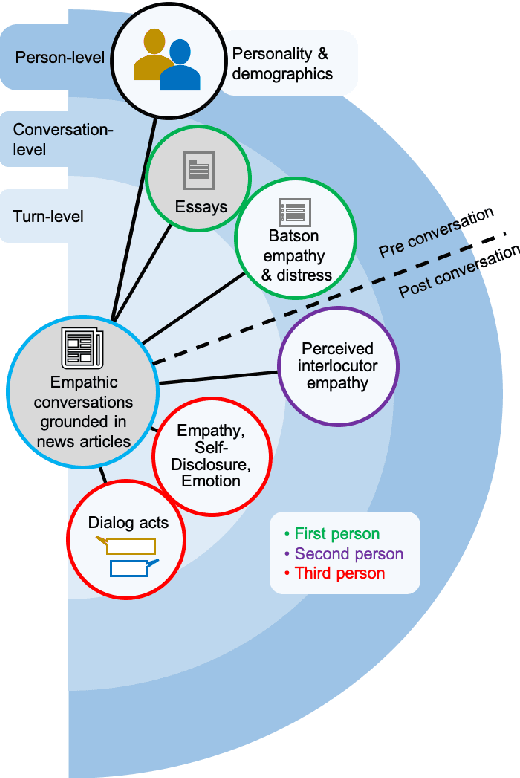
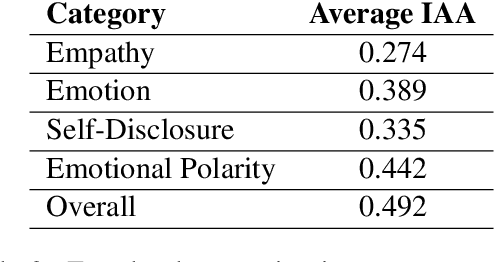
Empathy is a cognitive and emotional reaction to an observed situation of others. Empathy has recently attracted interest because it has numerous applications in psychology and AI, but it is unclear how different forms of empathy (e.g., self-report vs counterpart other-report, concern vs. distress) interact with other affective phenomena or demographics like gender and age. To better understand this, we created the {\it Empathic Conversations} dataset of annotated negative, empathy-eliciting dialogues in which pairs of participants converse about news articles. People differ in their perception of the empathy of others. These differences are associated with certain characteristics such as personality and demographics. Hence, we collected detailed characterization of the participants' traits, their self-reported empathetic response to news articles, their conversational partner other-report, and turn-by-turn third-party assessments of the level of self-disclosure, emotion, and empathy expressed. This dataset is the first to present empathy in multiple forms along with personal distress, emotion, personality characteristics, and person-level demographic information. We present baseline models for predicting some of these features from conversations.
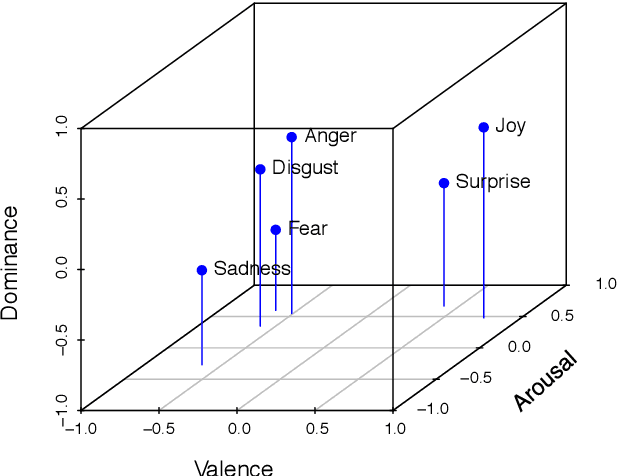
EmoBank: Studying the Impact of Annotation Perspective and Representation Format on Dimensional Emotion Analysis
May 04, 2022
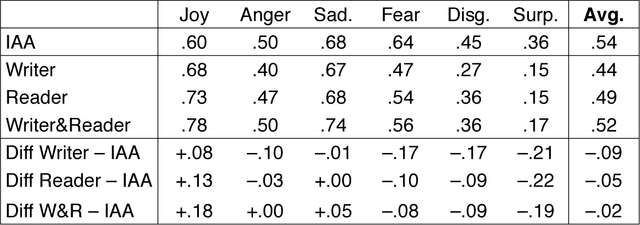
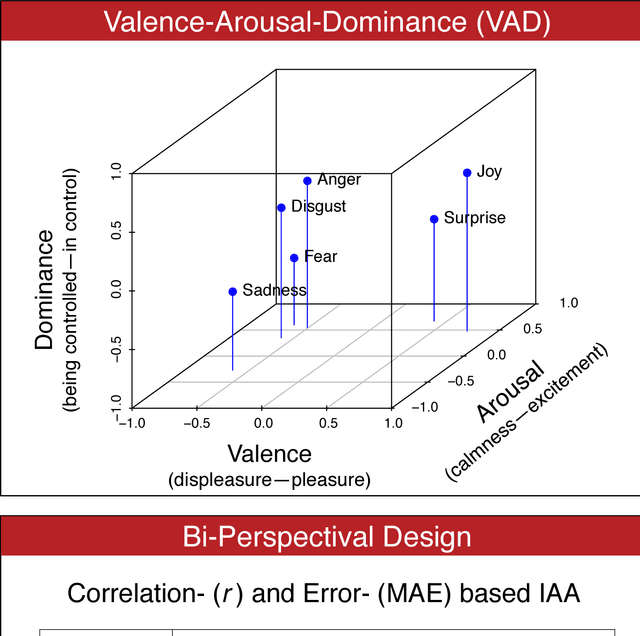
We describe EmoBank, a corpus of 10k English sentences balancing multiple genres, which we annotated with dimensional emotion metadata in the Valence-Arousal-Dominance (VAD) representation format. EmoBank excels with a bi-perspectival and bi-representational design. On the one hand, we distinguish between writer's and reader's emotions, on the other hand, a subset of the corpus complements dimensional VAD annotations with categorical ones based on Basic Emotions. We find evidence for the supremacy of the reader's perspective in terms of IAA and rating intensity, and achieve close-to-human performance when mapping between dimensional and categorical formats.
Towards a Unified Framework for Emotion Analysis
Dec 01, 2020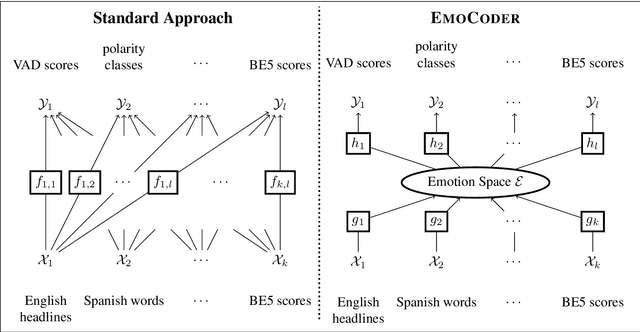
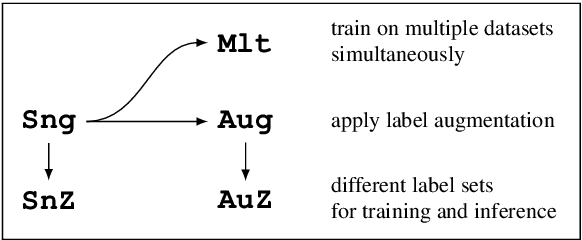
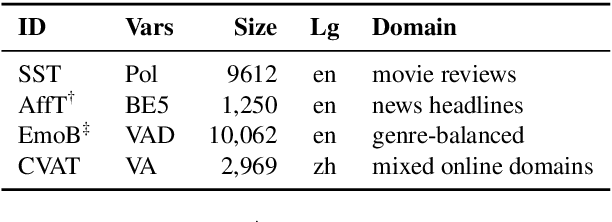
We present EmoCoder, a modular encoder-decoder architecture that generalizes emotion analysis over different tasks (sentence-level, word-level, label-to-label mapping), domains (natural languages and their registers), and label formats (e.g., polarity classes, basic emotions, and affective dimensions). Experiments on 14 datasets indicate that EmoCoder learns an interpretable language-independent representation of emotions, allows seamless absorption of state-of-the-art models, and maintains strong prediction quality, even when tested on unseen combinations of domains and label formats.
Learning and Evaluating Emotion Lexicons for 91 Languages
May 12, 2020
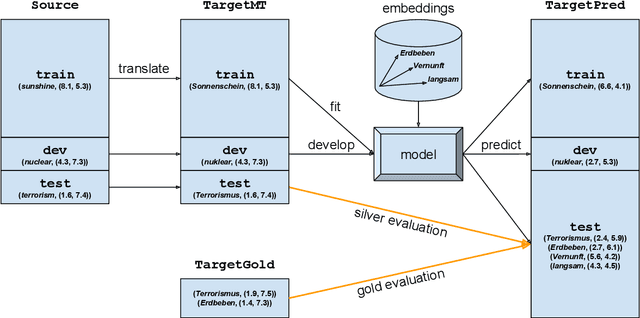


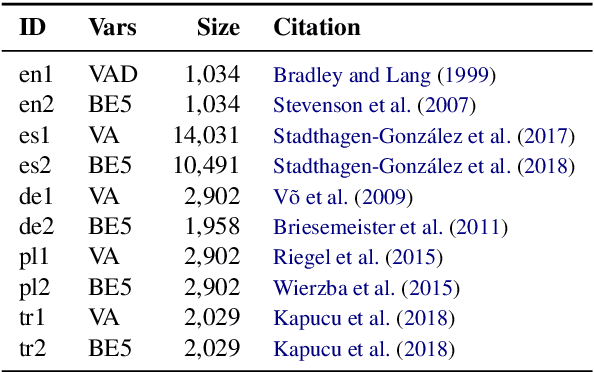
Emotion lexicons describe the affective meaning of words and thus constitute a centerpiece for advanced sentiment and emotion analysis. Yet, manually curated lexicons are only available for a handful of languages, leaving most languages of the world without such a precious resource for downstream applications. Even worse, their coverage is often limited both in terms of the lexical units they contain and the emotional variables they feature. In order to break this bottleneck, we here introduce a methodology for creating almost arbitrarily large emotion lexicons for any target language. Our approach requires nothing but a source language emotion lexicon, a bilingual word translation model, and a target language embedding model. Fulfilling these requirements for 91 languages, we are able to generate representationally rich high-coverage lexicons comprising eight emotional variables with more than 100k lexical entries each. We evaluated the automatically generated lexicons against human judgment from 26 datasets, spanning 12 typologically diverse languages, and found that our approach produces results in line with state-of-the-art monolingual approaches to lexicon creation and even surpasses human reliability for some languages and variables. Code and data are available at https://github.com/JULIELab/MEmoLon archived under DOI https://doi.org/10.5281/zenodo.3779901.
Learning Word Ratings for Empathy and Distress from Document-Level User Responses
Dec 02, 2019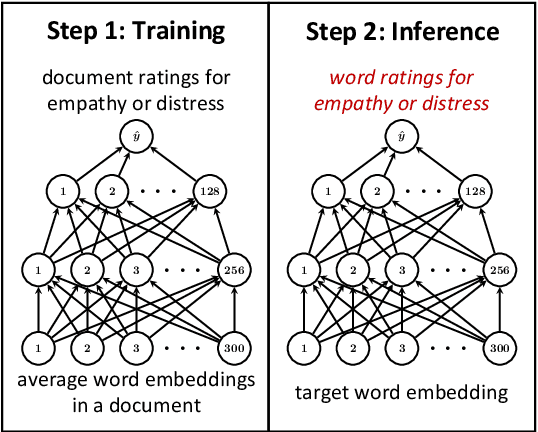
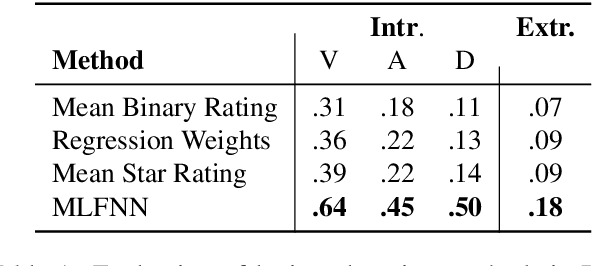
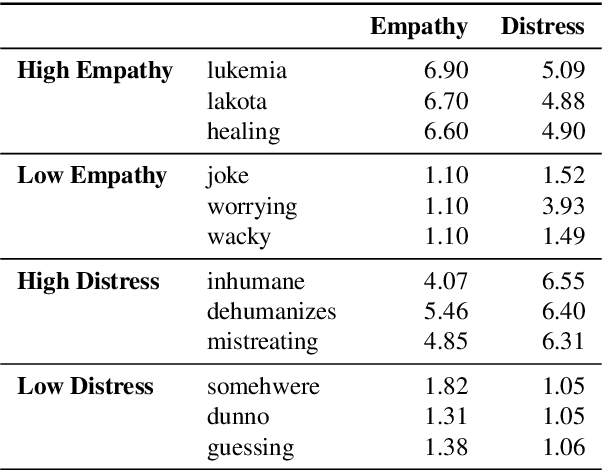
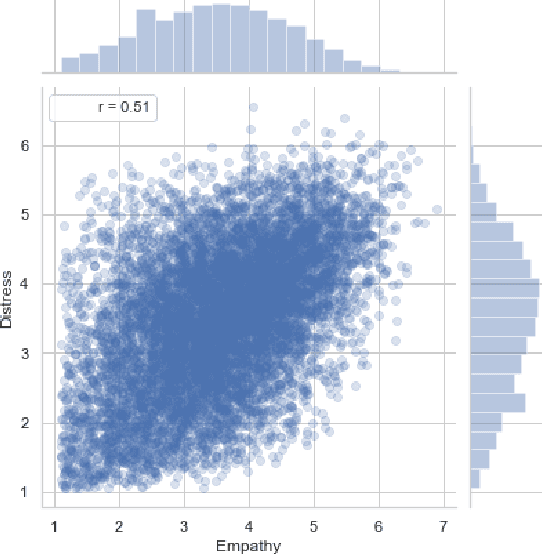
Despite the excellent performance of black box approaches to modeling sentiment and emotion, lexica (sets of informative words and associated weights) that characterize different emotions are indispensable to the NLP community because they allow for interpretable and robust predictions. Emotion analysis of text is increasing in popularity in NLP; however, manually creating lexica for psychological constructs such as empathy has proven difficult. This paper automatically creates empathy word ratings from document-level ratings. The underlying problem of learning word ratings from higher-level supervision has to date only been addressed in an ad hoc fashion and is missing deep learning methods. We systematically compare a number of approaches to learning word ratings from higher-level supervision against a Mixed-Level Feed Forward Network (MLFFN), which we find performs best, and use the MLFFN to create the first-ever empathy lexicon. We then use Signed Spectral Clustering to gain insights into the resulting words.
A Time Series Analysis of Emotional Loading in Central Bank Statements
Nov 26, 2019
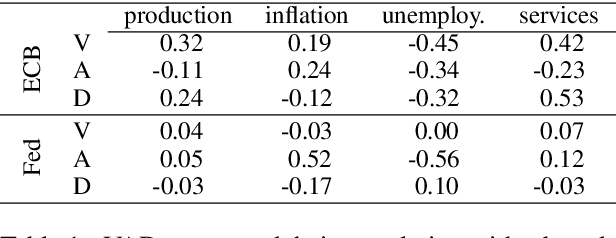
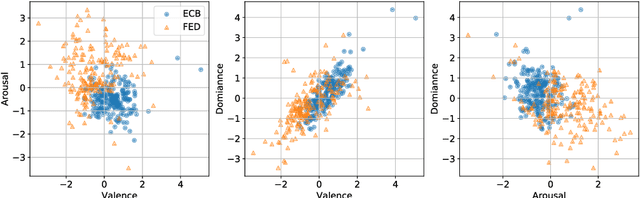
We examine the affective content of central bank press statements using emotion analysis. Our focus is on two major international players, the European Central Bank (ECB) and the US Federal Reserve Bank (Fed), covering a time span from 1998 through 2019. We reveal characteristic patterns in the emotional dimensions of valence, arousal, and dominance and find---despite the commonly established attitude that emotional wording in central bank communication should be avoided---a correlation between the state of the economy and particularly the dominance dimension in the press releases under scrutiny and, overall, an impact of the president in office.
* Published at ECONLP 2019
Learning Neural Emotion Analysis from 100 Observations: The Surprising Effectiveness of Pre-Trained Word Representations
Oct 25, 2018
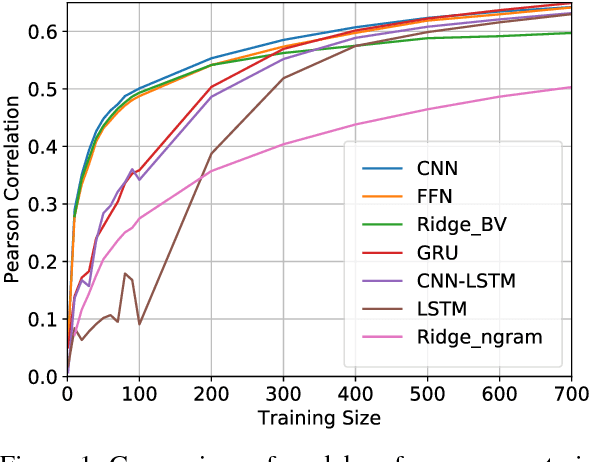

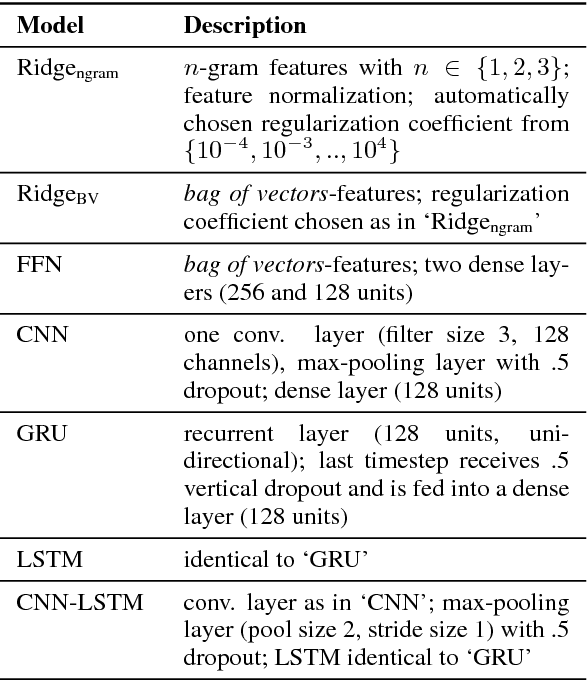
Deep Learning has drastically reshaped virtually all areas of NLP. Yet on the downside, it is commonly thought to be dependent on vast amounts of training data. As such, these techniques appear ill-suited for areas where annotated data is limited, like emotion analysis, with its many nuanced and hard-to-acquire annotation formats, or other low-data scenarios encountered in under-resourced languages. In contrast to this popular notion, we provide empirical evidence from three typologically diverse languages that today's favorite neural architectures can be trained on a few hundred observations only. Our results suggest that high-quality, pre-trained word embeddings are crucial for achieving high performance despite such strong data limitations.
Modeling Empathy and Distress in Reaction to News Stories
Aug 30, 2018
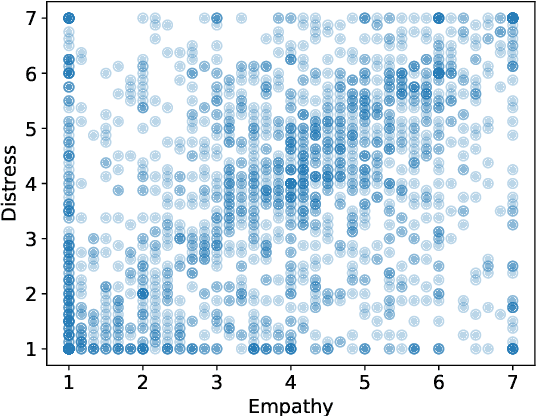

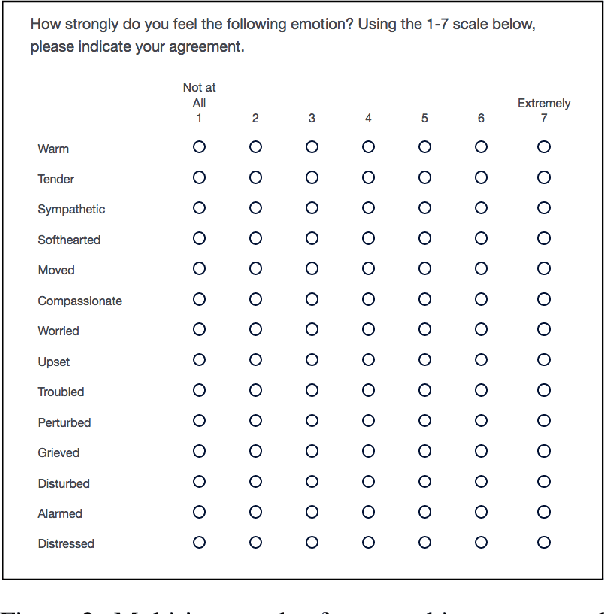
Computational detection and understanding of empathy is an important factor in advancing human-computer interaction. Yet to date, text-based empathy prediction has the following major limitations: It underestimates the psychological complexity of the phenomenon, adheres to a weak notion of ground truth where empathic states are ascribed by third parties, and lacks a shared corpus. In contrast, this contribution presents the first publicly available gold standard for empathy prediction. It is constructed using a novel annotation methodology which reliably captures empathy assessments by the writer of a statement using multi-item scales. This is also the first computational work distinguishing between multiple forms of empathy, empathic concern, and personal distress, as recognized throughout psychology. Finally, we present experimental results for three different predictive models, of which a CNN performs the best.
JeSemE: A Website for Exploring Diachronic Changes in Word Meaning and Emotion
Jul 11, 2018
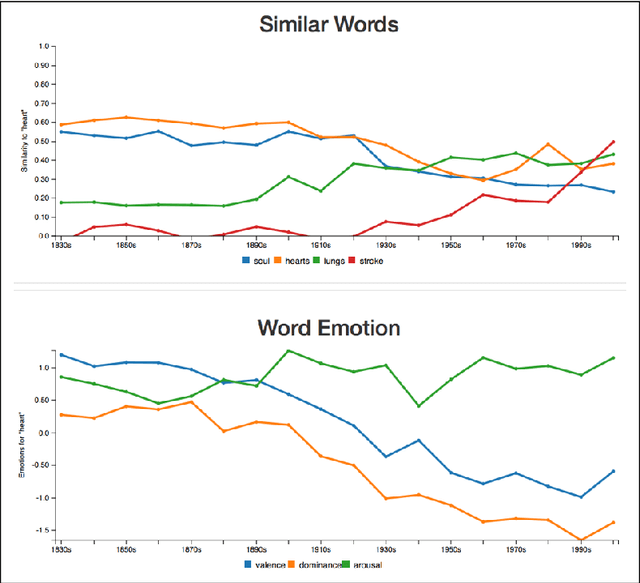

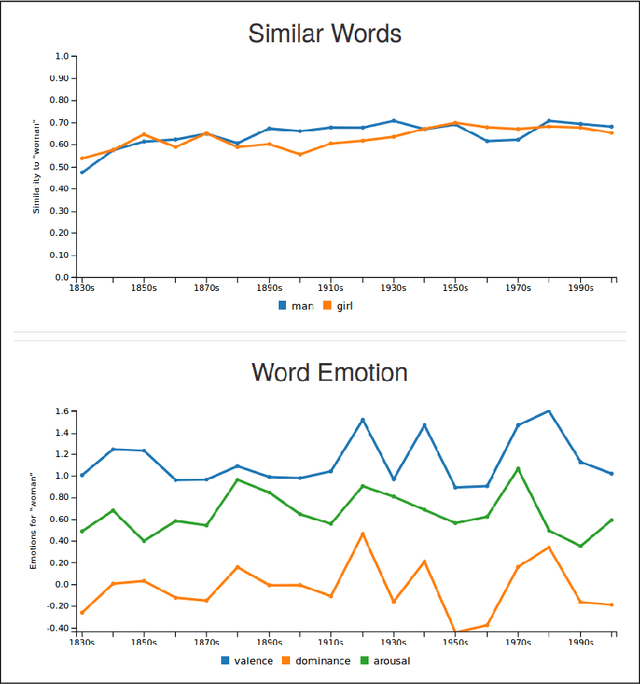
We here introduce a substantially extended version of JeSemE, a website for visually exploring computationally derived time-variant information on word meaning and lexical emotion assembled from five large diachronic text corpora. JeSemE is intended as an interactive tool for scholars in the (digital) humanities who are mostly limited to consulting manually compiled dictionaries for such information, if available at all. JeSemE uniquely combines state-of-the-art distributional semantics with a nuanced model of human emotions, two information streams we deem beneficial for a data-driven interpretation of texts in the humanities.