 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Document Corpora and Assorted Domain Proxies: A Survey of Diversity in Corpus Design, with Focus on German Text Data
Nov 29, 2024



We survey clinical document corpora, with focus on German textual data. Due to rigid data privacy legislation in Germany these resources, with only few exceptions, are stored in safe clinical data spaces and locked against clinic-external researchers. This situation stands in stark contrast with established workflows in the field of natural language processing where easy accessibility and reuse of data collections are common practice. Hence, alternative corpus designs have been examined to escape from this data poverty. Besides machine translation of English clinical datasets and the generation of synthetic corpora with fictitious clinical contents, several other types of domain proxies have come up as substitutes for authentic clinical documents. Common instances of close proxies are medical journal publications, clinical therapy guidelines, drug labels, etc., more distant proxies include online encyclopedic medical articles or medical contents from social media channels. After PRISM-conformant screening of 359 hits from four bibliographic systems, 75 relevant documents were finally selected for this review and 59 distinct corpora were determined. We identified 24 real clinical corpora (from 40 publications) out of which only 5 are publicly distributable. 2 translations of real corpora and 3 synthetic ones complement the set of clinical corpora. 14 corpora were categorized as close domain proxies, 16 as distant ones. There is a clear divide between the large number of non-accessible authentic clinical German-language corpora and their publicly accessible substitutes: translated or synthetic, close or more distant proxies. So on first sight, the data bottleneck seems broken. Intuitively yet, differences in genre-specific writing style, wording and medical domain expertise in this typological space are also obvious. This raises the question how valid alternative corpus designs really are.
Emotion Embeddings $\unicode{x2014}$ Learning Stable and Homogeneous Abstractions from Heterogeneous Affective Datasets
Aug 15, 2023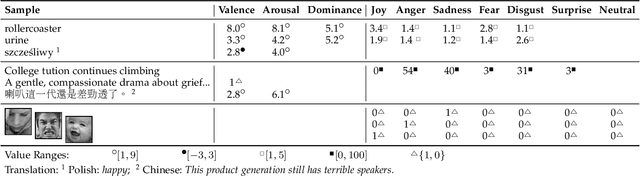
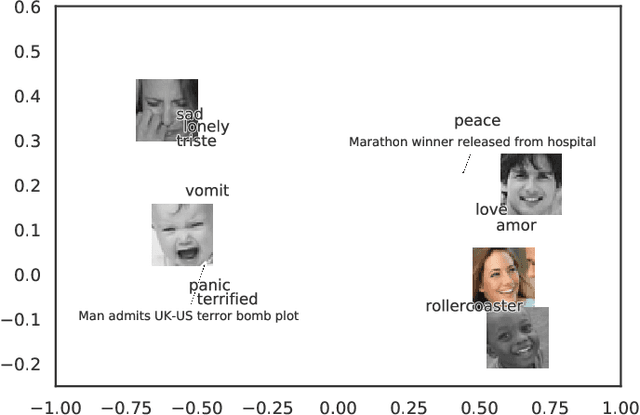
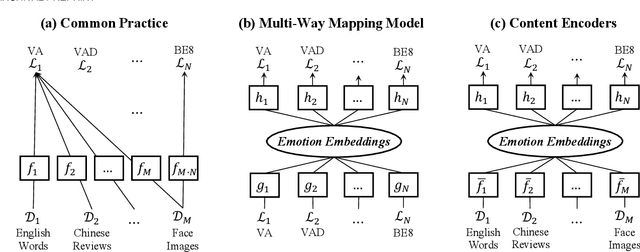
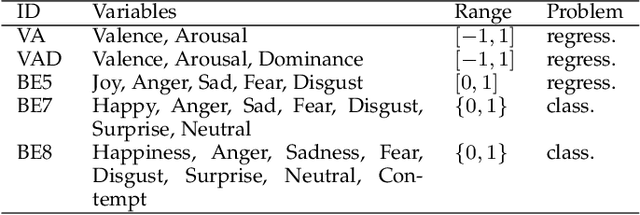
Human emotion is expressed in many communication modalities and media formats and so their computational study is equally diversified into natural language processing, audio signal analysis, computer vision, etc. Similarly, the large variety of representation formats used in previous research to describe emotions (polarity scales, basic emotion categories, dimensional approaches, appraisal theory, etc.) have led to an ever proliferating diversity of datasets, predictive models, and software tools for emotion analysis. Because of these two distinct types of heterogeneity, at the expressional and representational level, there is a dire need to unify previous work on increasingly diverging data and label types. This article presents such a unifying computational model. We propose a training procedure that learns a shared latent representation for emotions, so-called emotion embeddings, independent of different natural languages, communication modalities, media or representation label formats, and even disparate model architectures. Experiments on a wide range of heterogeneous affective datasets indicate that this approach yields the desired interoperability for the sake of reusability, interpretability and flexibility, without penalizing prediction quality. Code and data are archived under https://doi.org/10.5281/zenodo.7405327 .
EmoBank: Studying the Impact of Annotation Perspective and Representation Format on Dimensional Emotion Analysis
May 04, 2022
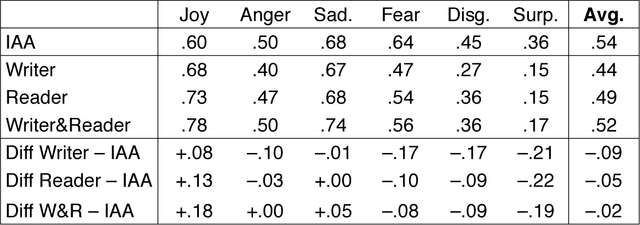
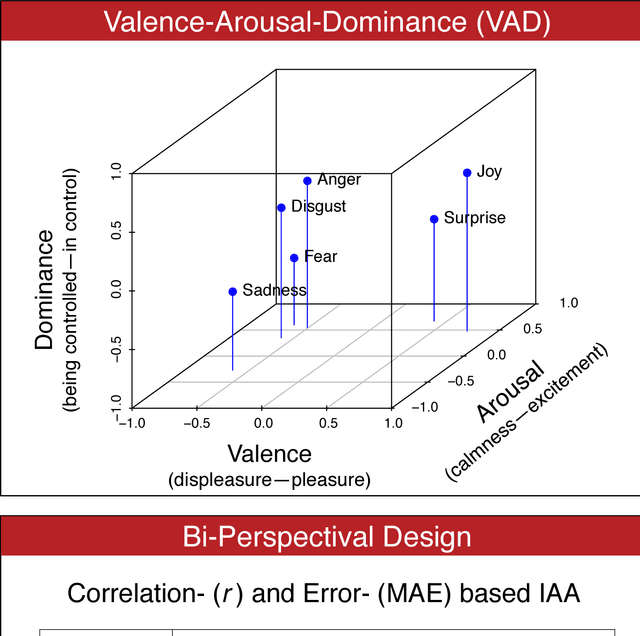
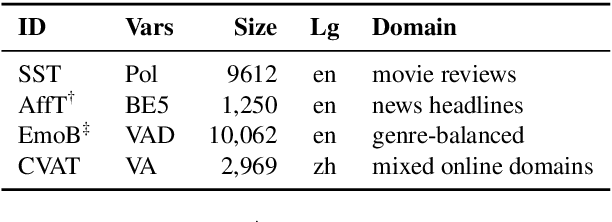
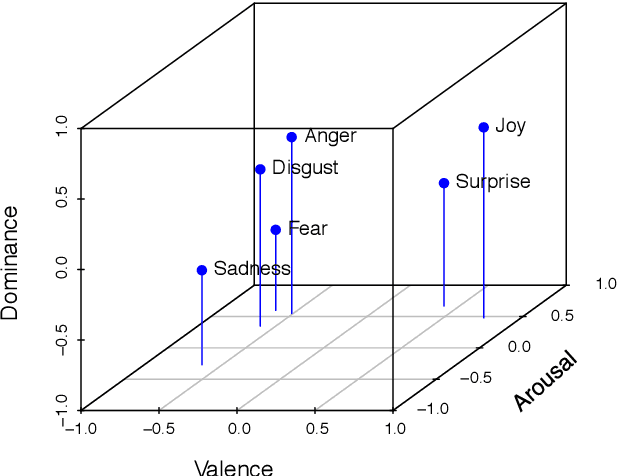
We describe EmoBank, a corpus of 10k English sentences balancing multiple genres, which we annotated with dimensional emotion metadata in the Valence-Arousal-Dominance (VAD) representation format. EmoBank excels with a bi-perspectival and bi-representational design. On the one hand, we distinguish between writer's and reader's emotions, on the other hand, a subset of the corpus complements dimensional VAD annotations with categorical ones based on Basic Emotions. We find evidence for the supremacy of the reader's perspective in terms of IAA and rating intensity, and achieve close-to-human performance when mapping between dimensional and categorical formats.
Towards a Unified Framework for Emotion Analysis
Dec 01, 2020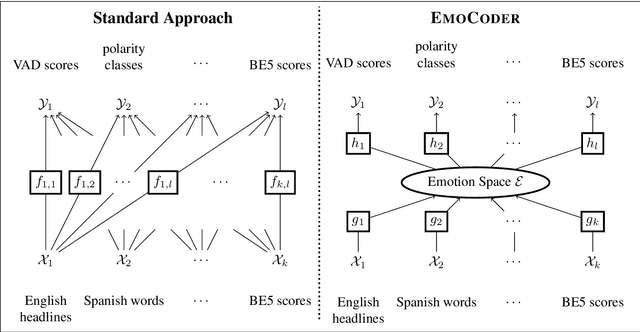
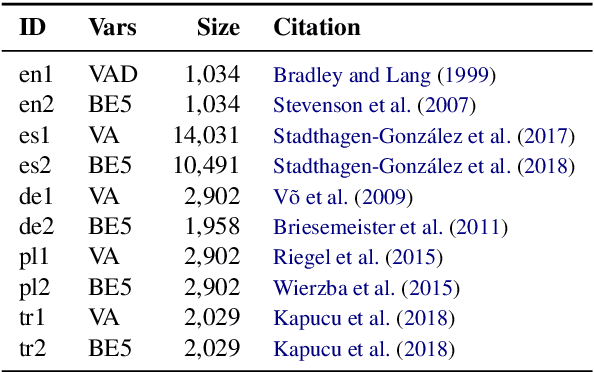
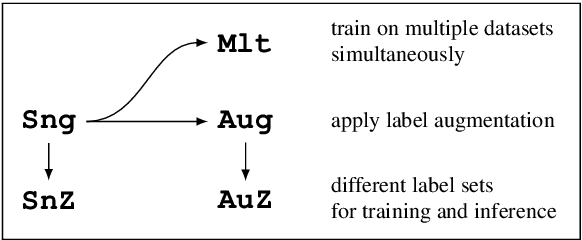
We present EmoCoder, a modular encoder-decoder architecture that generalizes emotion analysis over different tasks (sentence-level, word-level, label-to-label mapping), domains (natural languages and their registers), and label formats (e.g., polarity classes, basic emotions, and affective dimensions). Experiments on 14 datasets indicate that EmoCoder learns an interpretable language-independent representation of emotions, allows seamless absorption of state-of-the-art models, and maintains strong prediction quality, even when tested on unseen combinations of domains and label formats.
GGPONC: A Corpus of German Medical Text with Rich Metadata Based on Clinical Practice Guidelines
Jul 13, 2020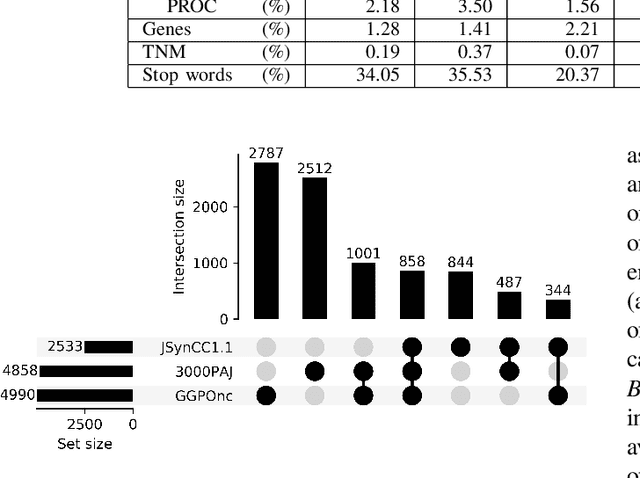
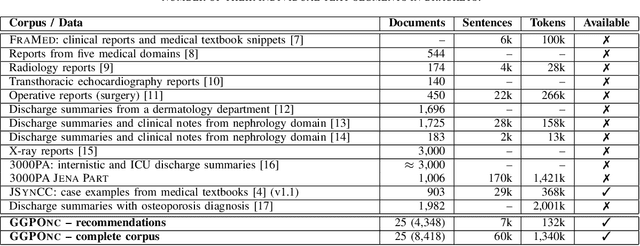
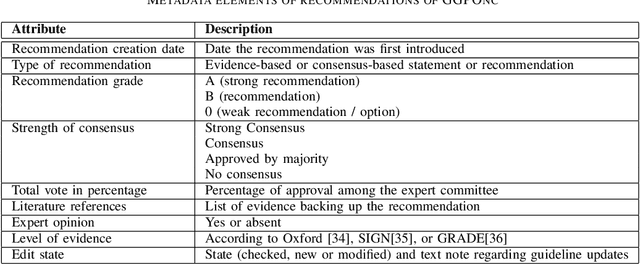
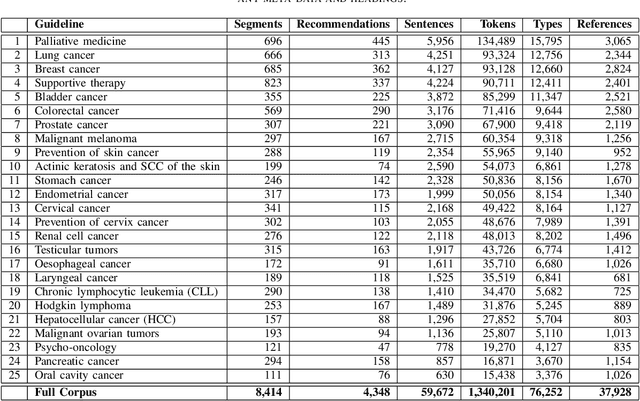
The lack of publicly available text corpora is a major obstacle for progress in clinical natural language processing, for non-English speaking countries in particular. In this work, we present GGPONC (German Guideline Program in Oncology NLP Corpus), a freely distributable German language corpus based on clinical practice guidelines in the field of oncology. The corpus is one of the largest corpora of German medical text to date. It does not contain any patient-related data and can therefore be used without data protection restrictions. Moreover, it is the first corpus for the German language covering diverse conditions in a large medical subfield. In addition to the textual sources, we provide a large variety of metadata, such as literature references and evidence levels. By applying and evaluating existing medical information extraction pipelines for German text, we are able to draw comparisons for the use of medical language to other medical text corpora.
Learning and Evaluating Emotion Lexicons for 91 Languages
May 12, 2020
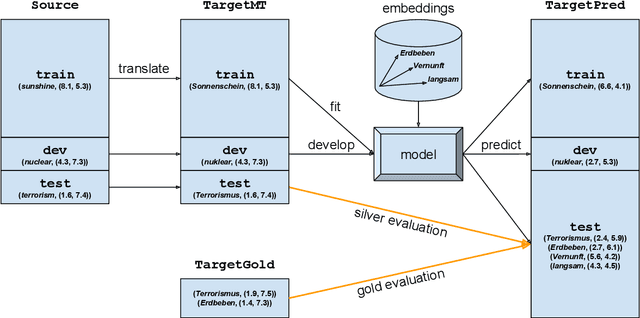


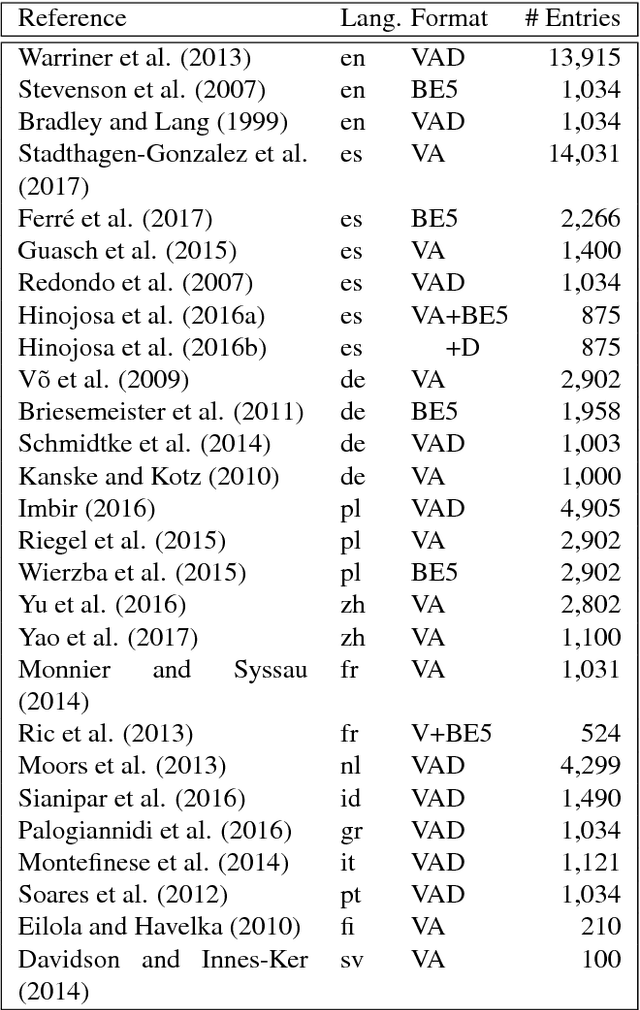
Emotion lexicons describe the affective meaning of words and thus constitute a centerpiece for advanced sentiment and emotion analysis. Yet, manually curated lexicons are only available for a handful of languages, leaving most languages of the world without such a precious resource for downstream applications. Even worse, their coverage is often limited both in terms of the lexical units they contain and the emotional variables they feature. In order to break this bottleneck, we here introduce a methodology for creating almost arbitrarily large emotion lexicons for any target language. Our approach requires nothing but a source language emotion lexicon, a bilingual word translation model, and a target language embedding model. Fulfilling these requirements for 91 languages, we are able to generate representationally rich high-coverage lexicons comprising eight emotional variables with more than 100k lexical entries each. We evaluated the automatically generated lexicons against human judgment from 26 datasets, spanning 12 typologically diverse languages, and found that our approach produces results in line with state-of-the-art monolingual approaches to lexicon creation and even surpasses human reliability for some languages and variables. Code and data are available at https://github.com/JULIELab/MEmoLon archived under DOI https://doi.org/10.5281/zenodo.3779901.
A Time Series Analysis of Emotional Loading in Central Bank Statements
Nov 26, 2019
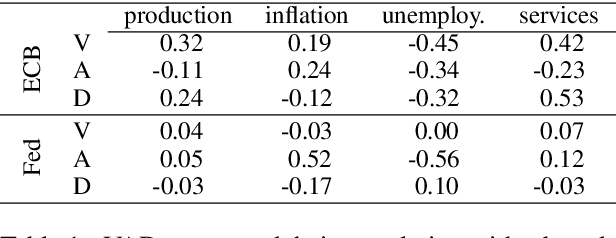
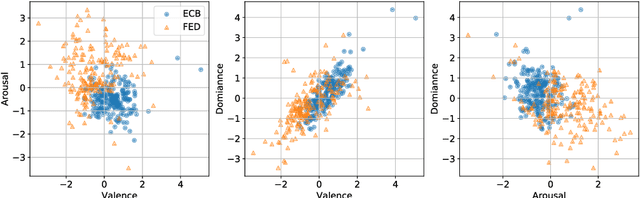
We examine the affective content of central bank press statements using emotion analysis. Our focus is on two major international players, the European Central Bank (ECB) and the US Federal Reserve Bank (Fed), covering a time span from 1998 through 2019. We reveal characteristic patterns in the emotional dimensions of valence, arousal, and dominance and find---despite the commonly established attitude that emotional wording in central bank communication should be avoided---a correlation between the state of the economy and particularly the dominance dimension in the press releases under scrutiny and, overall, an impact of the president in office.
* Published at ECONLP 2019
Downsampling Strategies are Crucial for Word Embedding Reliability
Aug 21, 2018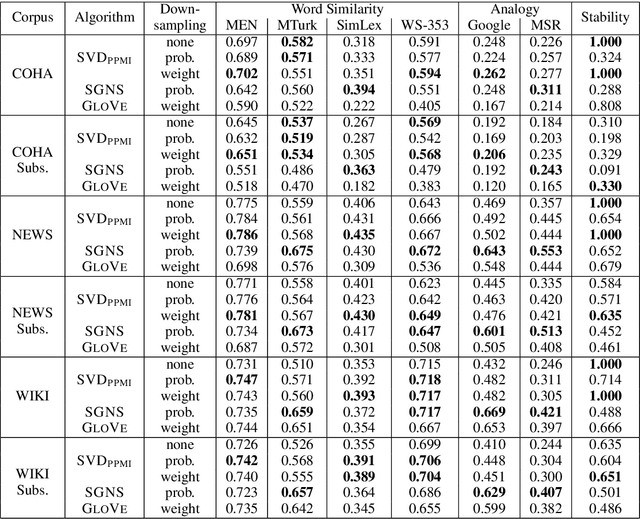
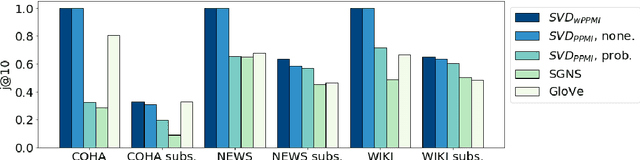
The reliability of word embeddings algorithms, i.e., their ability to provide consistent computational judgments of word similarity when trained repeatedly on the same data set, has recently raised concerns. We compared the effect of probabilistic and weighting as downsampling strategies. We found the latter to provide superior reliability while being competitive in accuracy when applied to singular value decomposition-based embeddings
JeSemE: A Website for Exploring Diachronic Changes in Word Meaning and Emotion
Jul 11, 2018
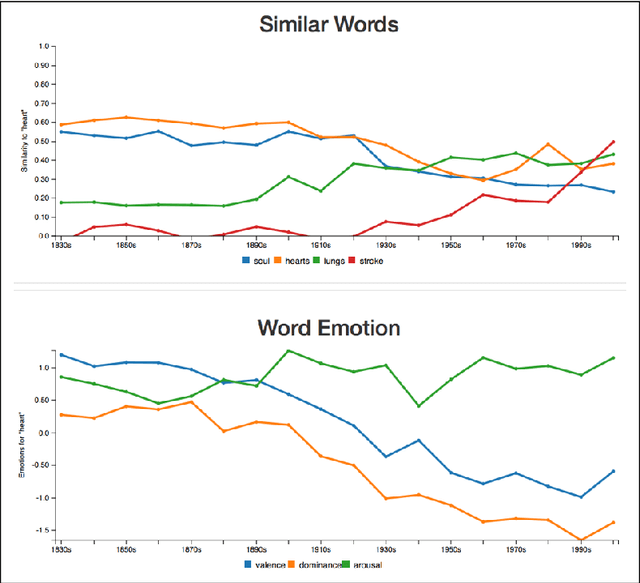

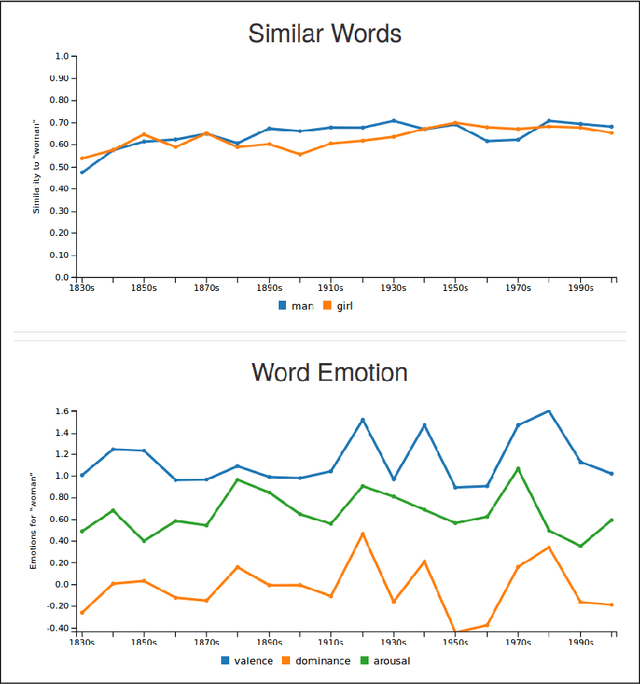
We here introduce a substantially extended version of JeSemE, a website for visually exploring computationally derived time-variant information on word meaning and lexical emotion assembled from five large diachronic text corpora. JeSemE is intended as an interactive tool for scholars in the (digital) humanities who are mostly limited to consulting manually compiled dictionaries for such information, if available at all. JeSemE uniquely combines state-of-the-art distributional semantics with a nuanced model of human emotions, two information streams we deem beneficial for a data-driven interpretation of texts in the humanities.
Representation Mapping: A Novel Approach to Generate High-Quality Multi-Lingual Emotion Lexicons
Jul 02, 2018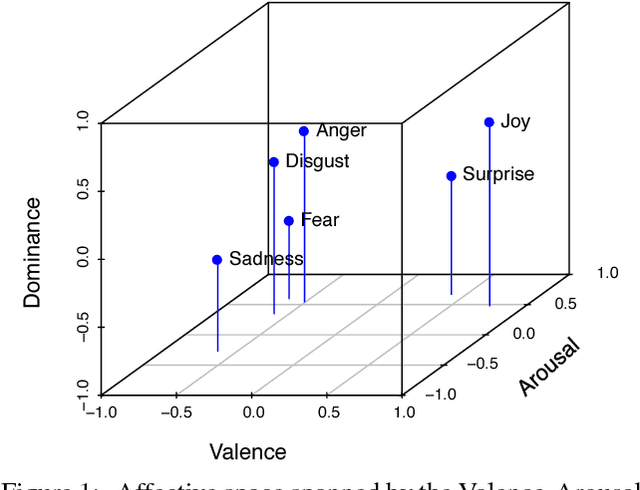
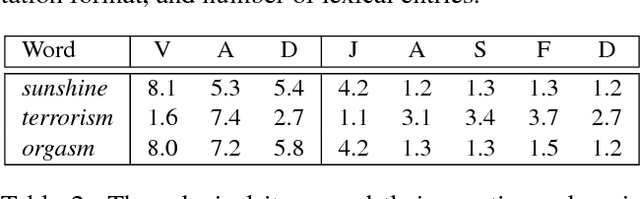
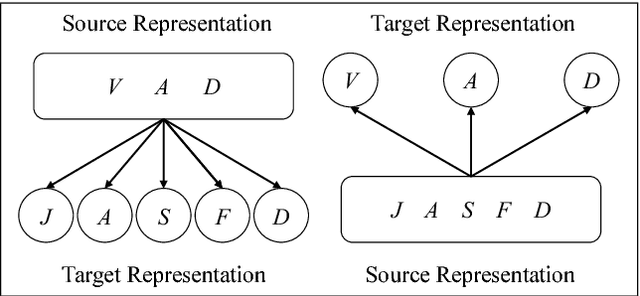
In the past years, sentiment analysis has increasingly shifted attention to representational frameworks more expressive than semantic polarity (being positive, negative or neutral). However, these richer formats (like Basic Emotions or Valence-Arousal-Dominance, and variants therefrom), rooted in psychological research, tend to proliferate the number of representation schemes for emotion encoding. Thus, a large amount of representationally incompatible emotion lexicons has been developed by various research groups adopting one or the other emotion representation format. As a consequence, the reusability of these resources decreases as does the comparability of systems using them. In this paper, we propose to solve this dilemma by methods and tools which map different representation formats onto each other for the sake of mutual compatibility and interoperability of language resources. We present the first large-scale investigation of such representation mappings for four typologically diverse languages and find evidence that our approach produces (near-)gold quality emotion lexicons, even in cross-lingual settings. Finally, we use our models to create new lexicons for eight typologically diverse languages.