Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDownsampling Strategies are Crucial for Word Embedding Reliability
Aug 21, 2018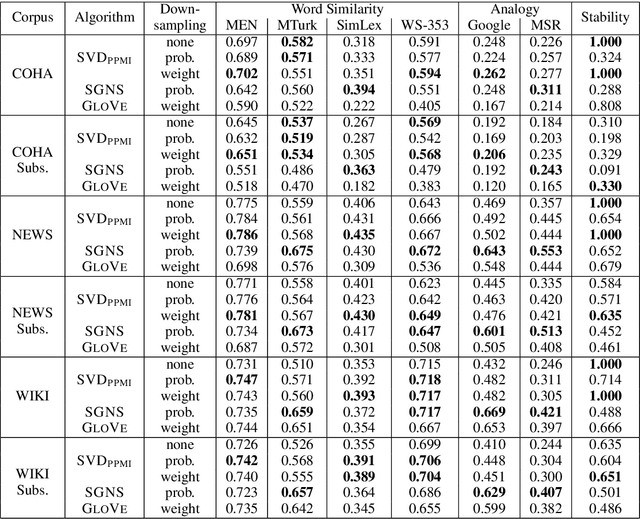
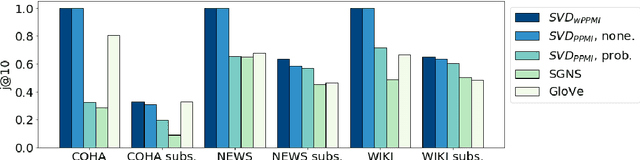
The reliability of word embeddings algorithms, i.e., their ability to provide consistent computational judgments of word similarity when trained repeatedly on the same data set, has recently raised concerns. We compared the effect of probabilistic and weighting as downsampling strategies. We found the latter to provide superior reliability while being competitive in accuracy when applied to singular value decomposition-based embeddings
Via