 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Design Decisions for Dual Encoder-based Entity Disambiguation
May 16, 2025Entity disambiguation (ED) is the task of linking mentions in text to corresponding entries in a knowledge base. Dual Encoders address this by embedding mentions and label candidates in a shared embedding space and applying a similarity metric to predict the correct label. In this work, we focus on evaluating key design decisions for Dual Encoder-based ED, such as its loss function, similarity metric, label verbalization format, and negative sampling strategy. We present the resulting model VerbalizED, a document-level Dual Encoder model that includes contextual label verbalizations and efficient hard negative sampling. Additionally, we explore an iterative prediction variant that aims to improve the disambiguation of challenging data points. Comprehensive experiments on AIDA-Yago validate the effectiveness of our approach, offering insights into impactful design choices that result in a new State-of-the-Art system on the ZELDA benchmark.
CleanCoNLL: A Nearly Noise-Free Named Entity Recognition Dataset
Oct 24, 2023The CoNLL-03 corpus is arguably the most well-known and utilized benchmark dataset for named entity recognition (NER). However, prior works found significant numbers of annotation errors, incompleteness, and inconsistencies in the data. This poses challenges to objectively comparing NER approaches and analyzing their errors, as current state-of-the-art models achieve F1-scores that are comparable to or even exceed the estimated noise level in CoNLL-03. To address this issue, we present a comprehensive relabeling effort assisted by automatic consistency checking that corrects 7.0% of all labels in the English CoNLL-03. Our effort adds a layer of entity linking annotation both for better explainability of NER labels and as additional safeguard of annotation quality. Our experimental evaluation finds not only that state-of-the-art approaches reach significantly higher F1-scores (97.1%) on our data, but crucially that the share of correct predictions falsely counted as errors due to annotation noise drops from 47% to 6%. This indicates that our resource is well suited to analyze the remaining errors made by state-of-the-art models, and that the theoretical upper bound even on high resource, coarse-grained NER is not yet reached. To facilitate such analysis, we make CleanCoNLL publicly available to the research community.
Learning and Evaluating Emotion Lexicons for 91 Languages
May 12, 2020
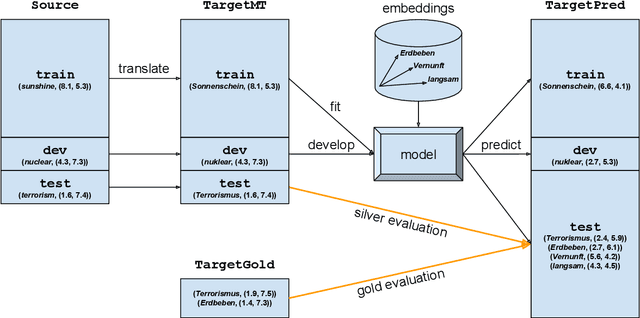


Emotion lexicons describe the affective meaning of words and thus constitute a centerpiece for advanced sentiment and emotion analysis. Yet, manually curated lexicons are only available for a handful of languages, leaving most languages of the world without such a precious resource for downstream applications. Even worse, their coverage is often limited both in terms of the lexical units they contain and the emotional variables they feature. In order to break this bottleneck, we here introduce a methodology for creating almost arbitrarily large emotion lexicons for any target language. Our approach requires nothing but a source language emotion lexicon, a bilingual word translation model, and a target language embedding model. Fulfilling these requirements for 91 languages, we are able to generate representationally rich high-coverage lexicons comprising eight emotional variables with more than 100k lexical entries each. We evaluated the automatically generated lexicons against human judgment from 26 datasets, spanning 12 typologically diverse languages, and found that our approach produces results in line with state-of-the-art monolingual approaches to lexicon creation and even surpasses human reliability for some languages and variables. Code and data are available at https://github.com/JULIELab/MEmoLon archived under DOI https://doi.org/10.5281/zenodo.3779901.