 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Aware Knowledge Probing: Evaluating Language Models' Relational Knowledge through Confidence Calibration
Jan 26, 2026Knowledge probing quantifies how much relational knowledge a language model (LM) has acquired during pre-training. Existing knowledge probes evaluate model capabilities through metrics like prediction accuracy and precision. Such evaluations fail to account for the model's reliability, reflected in the calibration of its confidence scores. In this paper, we propose a novel calibration probing framework for relational knowledge, covering three modalities of model confidence: (1) intrinsic confidence, (2) structural consistency and (3) semantic grounding. Our extensive analysis of ten causal and six masked language models reveals that most models, especially those pre-trained with the masking objective, are overconfident. The best-calibrated scores come from confidence estimates that account for inconsistencies due to statement rephrasing. Moreover, even the largest pre-trained models fail to encode the semantics of linguistic confidence expressions accurately.
Beyond Marginal Distributions: A Framework to Evaluate the Representativeness of Demographic-Aligned LLMs
Jan 22, 2026Large language models are increasingly used to represent human opinions, values, or beliefs, and their steerability towards these ideals is an active area of research. Existing work focuses predominantly on aligning marginal response distributions, treating each survey item independently. While essential, this may overlook deeper latent structures that characterise real populations and underpin cultural values theories. We propose a framework for evaluating the representativeness of aligned models through multivariate correlation patterns in addition to marginal distributions. We show the value of our evaluation scheme by comparing two model steering techniques (persona prompting and demographic fine-tuning) and evaluating them against human responses from the World Values Survey. While the demographically fine-tuned model better approximates marginal response distributions than persona prompting, both techniques fail to fully capture the gold standard correlation patterns. We conclude that representativeness is a distinct aspect of value alignment and an evaluation focused on marginals can mask structural failures, leading to overly optimistic conclusions about model capabilities.
What Matters When Building Universal Multilingual Named Entity Recognition Models?
Jan 09, 2026Recent progress in universal multilingual named entity recognition (NER) has been driven by advances in multilingual transformer models and task-specific architectures, loss functions, and training datasets. Despite substantial prior work, we find that many critical design decisions for such models are made without systematic justification, with architectural components, training objectives, and data sources evaluated only in combination rather than in isolation. We argue that these decisions impede progress in the field by making it difficult to identify which choices improve model performance. In this work, we conduct extensive experiments around architectures, transformer backbones, training objectives, and data composition across a wide range of languages. Based on these insights, we introduce Otter, a universal multilingual NER model supporting over 100 languages. Otter achieves consistent improvements over strong multilingual NER baselines, outperforming GLiNER-x-base by 5.3pp in F1 and achieves competitive performance compared to large generative models such as Qwen3-32B, while being substantially more efficient. We release model checkpoints, training and evaluation code to facilitate reproducibility and future research.
FiNERweb: Datasets and Artifacts for Scalable Multilingual Named Entity Recognition
Dec 15, 2025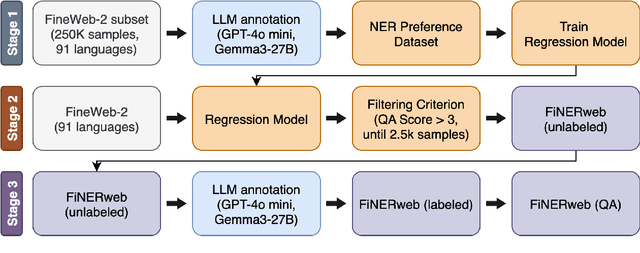
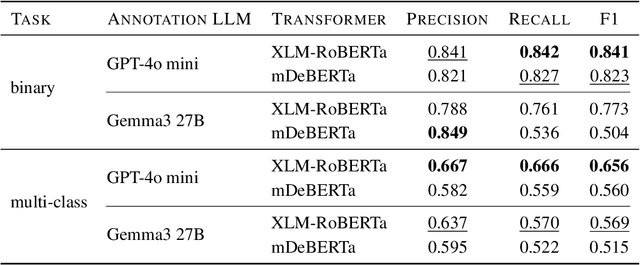

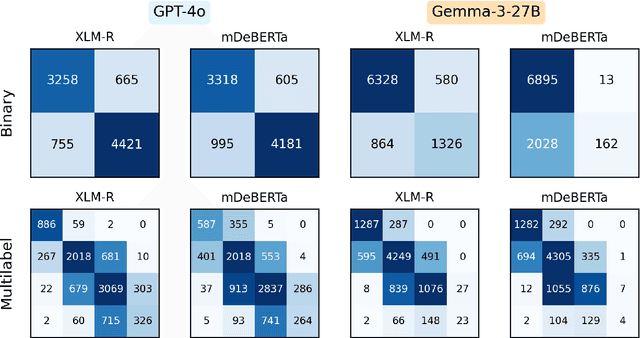
Recent multilingual named entity recognition (NER) work has shown that large language models (LLMs) can provide effective synthetic supervision, yet such datasets have mostly appeared as by-products of broader experiments rather than as systematic, reusable resources. We introduce FiNERweb, a dataset-creation pipeline that scales the teacher-student paradigm to 91 languages and 25 scripts. Building on FineWeb-Edu, our approach trains regression models to identify NER-relevant passages and annotates them with multilingual LLMs, resulting in about 225k passages with 235k distinct entity labels. Our experiments show that the regression model achieves more than 84 F1, and that models trained on FiNERweb obtain comparable or improved performance in zero shot transfer settings on English, Thai, and Swahili, despite being trained on 19x less data than strong baselines. In addition, we assess annotation quality using LLM-as-a-judge and observe consistently high scores for both faithfulness (3.99 out of 5) and completeness (4.05 out of 5), indicating reliable and informative annotations. Further, we release the dataset with both English labels and translated label sets in the respective target languages because we observe that the performance of current state-of-the-art models drops by 0.02 to 0.09 F1 when evaluated using target language labels instead of English ones. We release FiNERweb together with all accompanying artifacts to the research community in order to facilitate more effective student-teacher training for multilingual named entity recognition.
Pre-Training Curriculum for Multi-Token Prediction in Language Models
May 28, 2025Multi-token prediction (MTP) is a recently proposed pre-training objective for language models. Rather than predicting only the next token (NTP), MTP predicts the next $k$ tokens at each prediction step, using multiple prediction heads. MTP has shown promise in improving downstream performance, inference speed, and training efficiency, particularly for large models. However, prior work has shown that smaller language models (SLMs) struggle with the MTP objective. To address this, we propose a curriculum learning strategy for MTP training, exploring two variants: a forward curriculum, which gradually increases the complexity of the pre-training objective from NTP to MTP, and a reverse curriculum, which does the opposite. Our experiments show that the forward curriculum enables SLMs to better leverage the MTP objective during pre-training, improving downstream NTP performance and generative output quality, while retaining the benefits of self-speculative decoding. The reverse curriculum achieves stronger NTP performance and output quality, but fails to provide any self-speculative decoding benefits.
Evaluating Design Decisions for Dual Encoder-based Entity Disambiguation
May 16, 2025Entity disambiguation (ED) is the task of linking mentions in text to corresponding entries in a knowledge base. Dual Encoders address this by embedding mentions and label candidates in a shared embedding space and applying a similarity metric to predict the correct label. In this work, we focus on evaluating key design decisions for Dual Encoder-based ED, such as its loss function, similarity metric, label verbalization format, and negative sampling strategy. We present the resulting model VerbalizED, a document-level Dual Encoder model that includes contextual label verbalizations and efficient hard negative sampling. Additionally, we explore an iterative prediction variant that aims to improve the disambiguation of challenging data points. Comprehensive experiments on AIDA-Yago validate the effectiveness of our approach, offering insights into impactful design choices that result in a new State-of-the-Art system on the ZELDA benchmark.
Empirical Evaluation of Knowledge Distillation from Transformers to Subquadratic Language Models
Apr 19, 2025



Knowledge distillation is a widely used technique for compressing large language models (LLMs) by training a smaller student model to mimic a larger teacher model. Typically, both the teacher and student are Transformer-based architectures, leveraging softmax attention for sequence modeling. However, the quadratic complexity of self-attention at inference time remains a significant bottleneck, motivating the exploration of subquadratic alternatives such as structured state-space models (SSMs), linear attention, and recurrent architectures. In this work, we systematically evaluate the transferability of knowledge distillation from a Transformer teacher to nine subquadratic student architectures. Our study aims to determine which subquadratic model best aligns with the teacher's learned representations and how different architectural constraints influence the distillation process. We also investigate the impact of intelligent initialization strategies, including matrix mixing and query-key-value (QKV) copying, on the adaptation process. Our empirical results on multiple NLP benchmarks provide insights into the trade-offs between efficiency and performance, highlighting key factors for successful knowledge transfer to subquadratic architectures.
MastermindEval: A Simple But Scalable Reasoning Benchmark
Mar 11, 2025



Recent advancements in large language models (LLMs) have led to remarkable performance across a wide range of language understanding and mathematical tasks. As a result, increasing attention has been given to assessing the true reasoning capabilities of LLMs, driving research into commonsense, numerical, logical, and qualitative reasoning. However, with the rapid progress of reasoning-focused models such as OpenAI's o1 and DeepSeek's R1, there has been a growing demand for reasoning benchmarks that can keep pace with ongoing model developments. In this paper, we introduce MastermindEval, a simple, scalable, and interpretable deductive reasoning benchmark inspired by the board game Mastermind. Our benchmark supports two evaluation paradigms: (1) agentic evaluation, in which the model autonomously plays the game, and (2) deductive reasoning evaluation, in which the model is given a pre-played game state with only one possible valid code to infer. In our experimental results we (1) find that even easy Mastermind instances are difficult for current models and (2) demonstrate that the benchmark is scalable to possibly more advanced models in the future Furthermore, we investigate possible reasons why models cannot deduce the final solution and find that current models are limited in deducing the concealed code as the number of statement to combine information from is increasing.
BabyHGRN: Exploring RNNs for Sample-Efficient Training of Language Models
Dec 20, 2024



This paper explores the potential of recurrent neural networks (RNNs) and other subquadratic architectures as competitive alternatives to transformer-based models in low-resource language modeling scenarios. We utilize HGRN2 (Qin et al., 2024), a recently proposed RNN-based architecture, and comparatively evaluate its effectiveness against transformer-based baselines and other subquadratic architectures (LSTM, xLSTM, Mamba). Our experimental results show that BABYHGRN, our HGRN2 language model, outperforms transformer-based models in both the 10M and 100M word tracks of the challenge, as measured by their performance on the BLiMP, EWoK, GLUE and BEAR benchmarks. Further, we show the positive impact of knowledge distillation. Our findings challenge the prevailing focus on transformer architectures and indicate the viability of RNN-based models, particularly in resource-constrained environments.
Familiarity: Better Evaluation of Zero-Shot Named Entity Recognition by Quantifying Label Shifts in Synthetic Training Data
Dec 13, 2024



Zero-shot named entity recognition (NER) is the task of detecting named entities of specific types (such as 'Person' or 'Medicine') without any training examples. Current research increasingly relies on large synthetic datasets, automatically generated to cover tens of thousands of distinct entity types, to train zero-shot NER models. However, in this paper, we find that these synthetic datasets often contain entity types that are semantically highly similar to (or even the same as) those in standard evaluation benchmarks. Because of this overlap, we argue that reported F1 scores for zero-shot NER overestimate the true capabilities of these approaches. Further, we argue that current evaluation setups provide an incomplete picture of zero-shot abilities since they do not quantify the label shift (i.e., the similarity of labels) between training and evaluation datasets. To address these issues, we propose Familiarity, a novel metric that captures both the semantic similarity between entity types in training and evaluation, as well as their frequency in the training data, to provide an estimate of label shift. It allows researchers to contextualize reported zero-shot NER scores when using custom synthetic training datasets. Further, it enables researchers to generate evaluation setups of various transfer difficulties for fine-grained analysis of zero-shot NER.