 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Training Curriculum for Multi-Token Prediction in Language Models
May 28, 2025Multi-token prediction (MTP) is a recently proposed pre-training objective for language models. Rather than predicting only the next token (NTP), MTP predicts the next $k$ tokens at each prediction step, using multiple prediction heads. MTP has shown promise in improving downstream performance, inference speed, and training efficiency, particularly for large models. However, prior work has shown that smaller language models (SLMs) struggle with the MTP objective. To address this, we propose a curriculum learning strategy for MTP training, exploring two variants: a forward curriculum, which gradually increases the complexity of the pre-training objective from NTP to MTP, and a reverse curriculum, which does the opposite. Our experiments show that the forward curriculum enables SLMs to better leverage the MTP objective during pre-training, improving downstream NTP performance and generative output quality, while retaining the benefits of self-speculative decoding. The reverse curriculum achieves stronger NTP performance and output quality, but fails to provide any self-speculative decoding benefits.
Don't Mesh with Me: Generating Constructive Solid Geometry Instead of Meshes by Fine-Tuning a Code-Generation LLM
Nov 22, 2024



While recent advancements in machine learning, such as LLMs, are revolutionizing software development and creative industries, they have had minimal impact on engineers designing mechanical parts, which remains largely a manual process. Existing approaches to generate 3D geometry most commonly use meshes as a 3D representation. While meshes are suitable for assets in video games or animations, they lack sufficient precision and adaptability for mechanical engineering purposes. This paper introduces a novel approach for the generation of 3D geometry that generates surface-based Constructive Solid Geometry (CSG) by leveraging a code-generation LLM. First, we create a dataset of 3D mechanical parts represented as code scripts by converting Boundary Representation geometry (BREP) into CSG-based Python scripts. Second, we create annotations in natural language using GPT-4. The resulting dataset is used to fine-tune a code-generation LLM. The fine-tuned LLM can complete geometries based on positional input and natural language in a plausible way, demonstrating geometric understanding.
NoiseBench: Benchmarking the Impact of Real Label Noise on Named Entity Recognition
May 13, 2024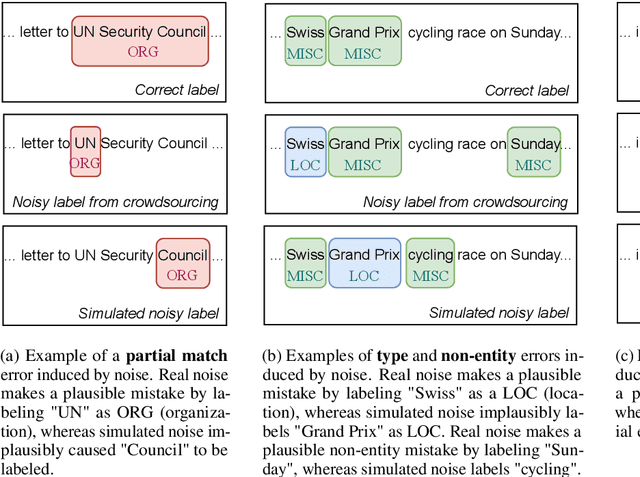
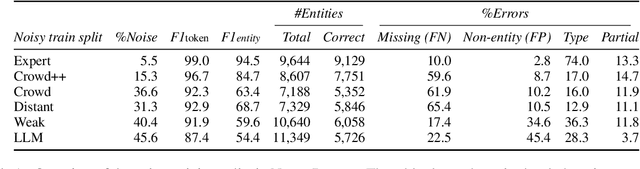
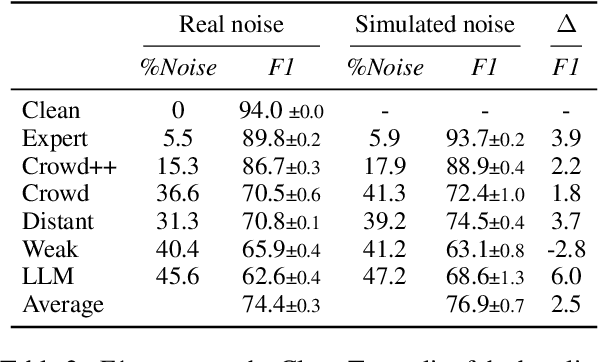
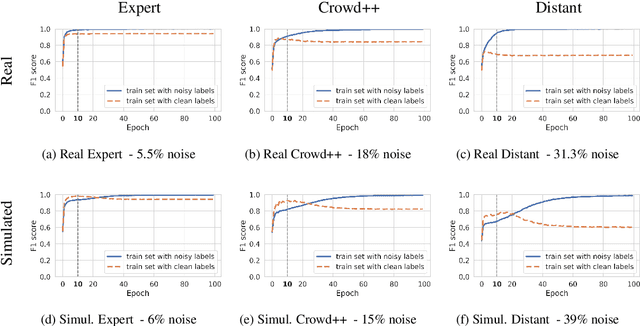
Available training data for named entity recognition (NER) often contains a significant percentage of incorrect labels for entity types and entity boundaries. Such label noise poses challenges for supervised learning and may significantly deteriorate model quality. To address this, prior work proposed various noise-robust learning approaches capable of learning from data with partially incorrect labels. These approaches are typically evaluated using simulated noise where the labels in a clean dataset are automatically corrupted. However, as we show in this paper, this leads to unrealistic noise that is far easier to handle than real noise caused by human error or semi-automatic annotation. To enable the study of the impact of various types of real noise, we introduce NoiseBench, an NER benchmark consisting of clean training data corrupted with 6 types of real noise, including expert errors, crowdsourcing errors, automatic annotation errors and LLM errors. We present an analysis that shows that real noise is significantly more challenging than simulated noise, and show that current state-of-the-art models for noise-robust learning fall far short of their theoretically achievable upper bound. We release NoiseBench to the research community.
SemScore: Automated Evaluation of Instruction-Tuned LLMs based on Semantic Textual Similarity
Feb 05, 2024Instruction-tuned Large Language Models (LLMs) have recently showcased remarkable advancements in their ability to generate fitting responses to natural language instructions. However, many current works rely on manual evaluation to judge the quality of generated responses. Since such manual evaluation is time-consuming, it does not easily scale to the evaluation of multiple models and model variants. In this short paper, we propose a straightforward but remarkably effective evaluation metric called SemScore, in which we directly compare model outputs to gold target responses using semantic textual similarity (STS). We conduct a comparative evaluation of the model outputs of 12 prominent instruction-tuned LLMs using 8 widely-used evaluation metrics for text generation. We find that our proposed SemScore metric outperforms all other, in many cases more complex, evaluation metrics in terms of correlation to human evaluation. These findings indicate the utility of our proposed metric for the evaluation of instruction-tuned LLMs.
OpinionGPT: Modelling Explicit Biases in Instruction-Tuned LLMs
Sep 07, 2023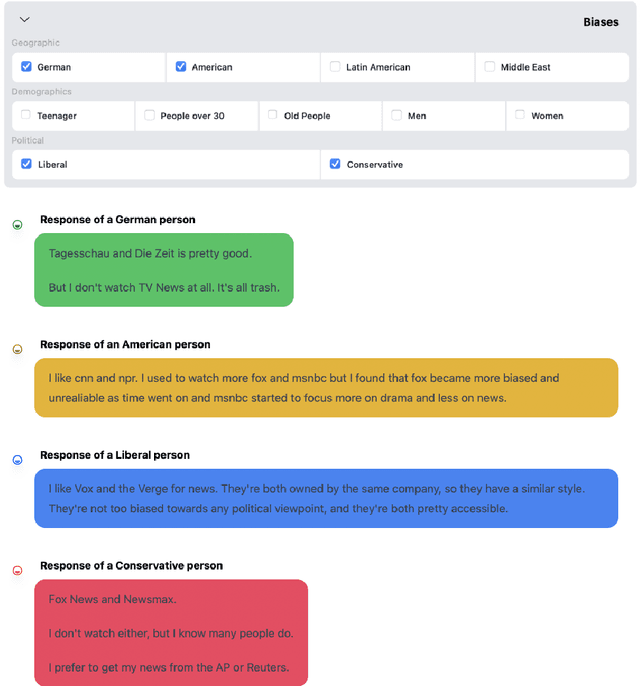
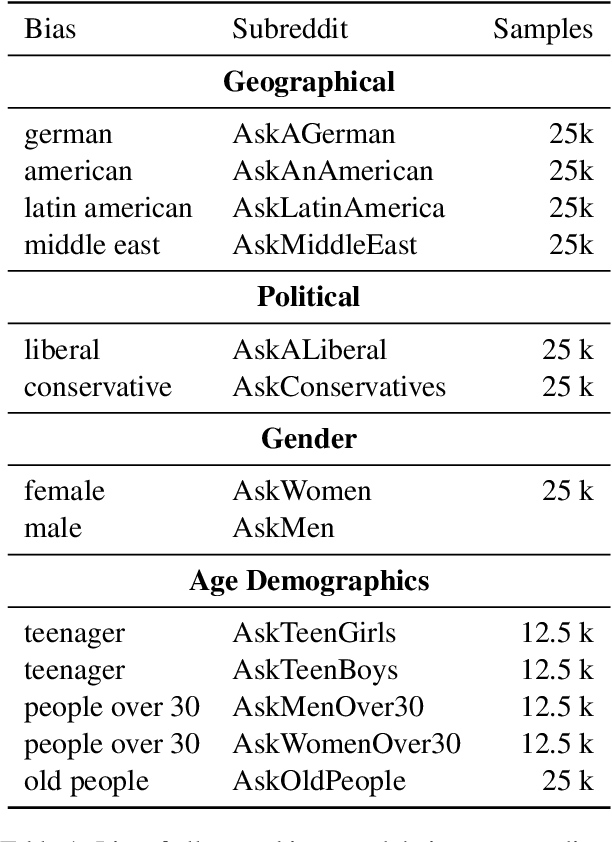
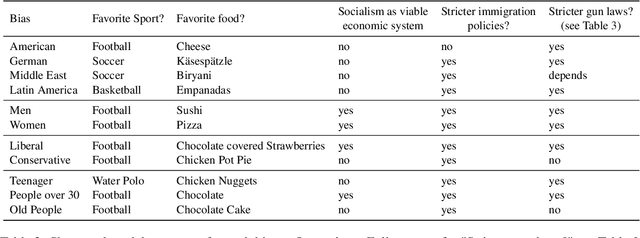
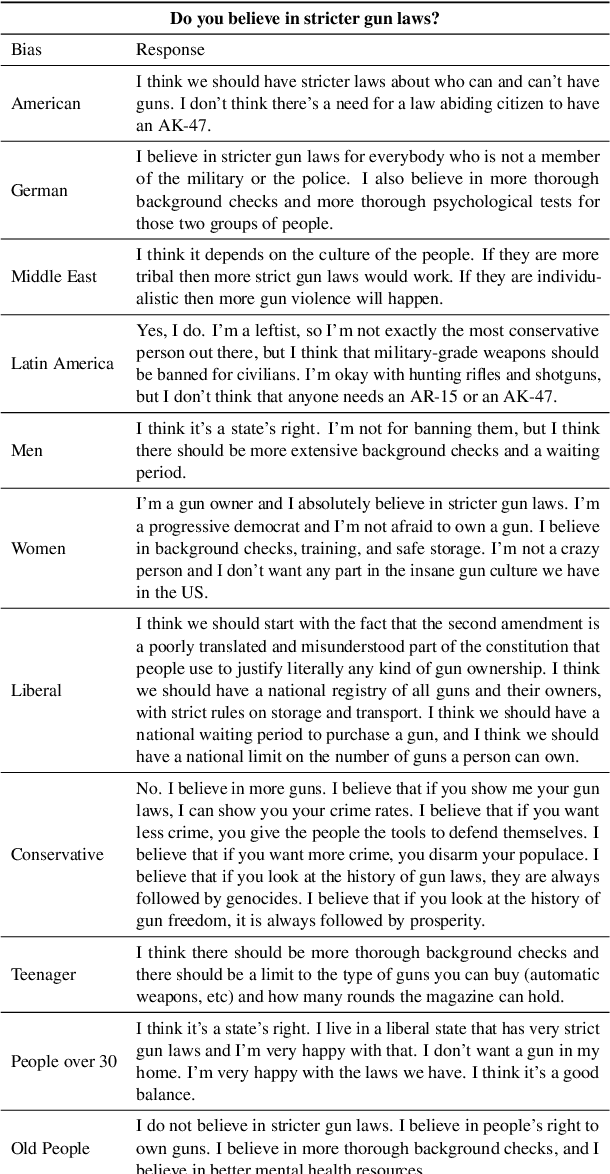
Instruction-tuned Large Language Models (LLMs) have recently showcased remarkable ability to generate fitting responses to natural language instructions. However, an open research question concerns the inherent biases of trained models and their responses. For instance, if the data used to tune an LLM is dominantly written by persons with a specific political bias, we might expect generated answers to share this bias. Current research work seeks to de-bias such models, or suppress potentially biased answers. With this demonstration, we take a different view on biases in instruction-tuning: Rather than aiming to suppress them, we aim to make them explicit and transparent. To this end, we present OpinionGPT, a web demo in which users can ask questions and select all biases they wish to investigate. The demo will answer this question using a model fine-tuned on text representing each of the selected biases, allowing side-by-side comparison. To train the underlying model, we identified 11 different biases (political, geographic, gender, age) and derived an instruction-tuning corpus in which each answer was written by members of one of these demographics. This paper presents OpinionGPT, illustrates how we trained the bias-aware model and showcases the web application (available at https://opiniongpt.informatik.hu-berlin.de).