 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGGPONC: A Corpus of German Medical Text with Rich Metadata Based on Clinical Practice Guidelines
Paper and Code
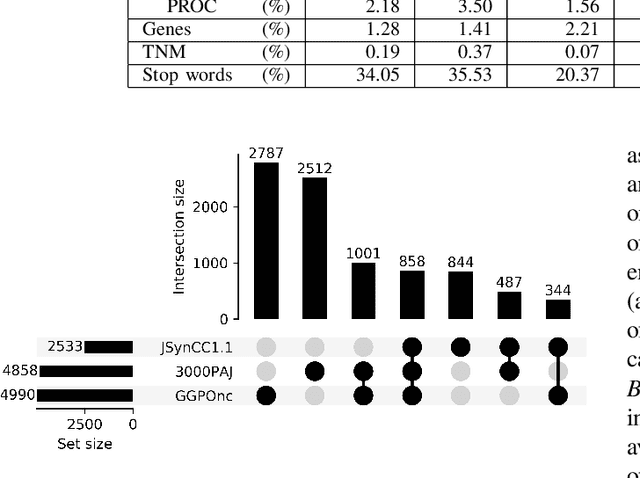
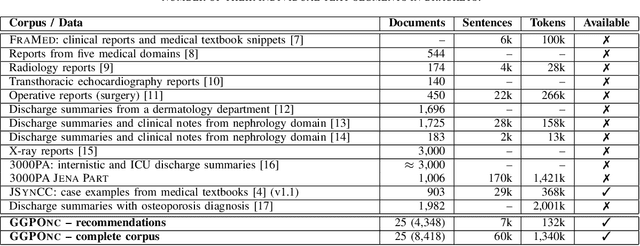
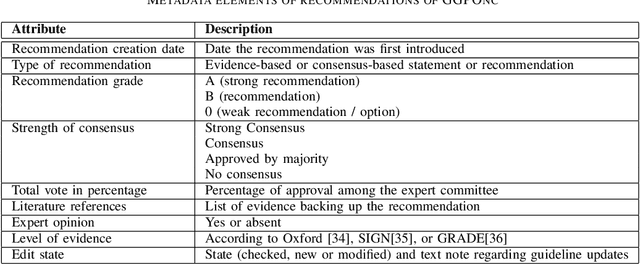
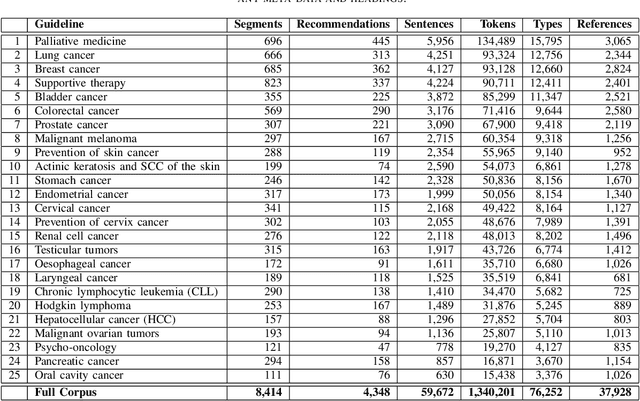
The lack of publicly available text corpora is a major obstacle for progress in clinical natural language processing, for non-English speaking countries in particular. In this work, we present GGPONC (German Guideline Program in Oncology NLP Corpus), a freely distributable German language corpus based on clinical practice guidelines in the field of oncology. The corpus is one of the largest corpora of German medical text to date. It does not contain any patient-related data and can therefore be used without data protection restrictions. Moreover, it is the first corpus for the German language covering diverse conditions in a large medical subfield. In addition to the textual sources, we provide a large variety of metadata, such as literature references and evidence levels. By applying and evaluating existing medical information extraction pipelines for German text, we are able to draw comparisons for the use of medical language to other medical text corpora.