 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based Section Identifiers Excel on Open Source but Stumble in Real World Applications
Apr 25, 2024

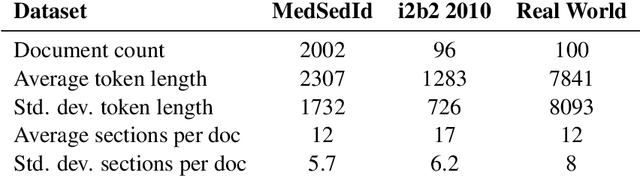
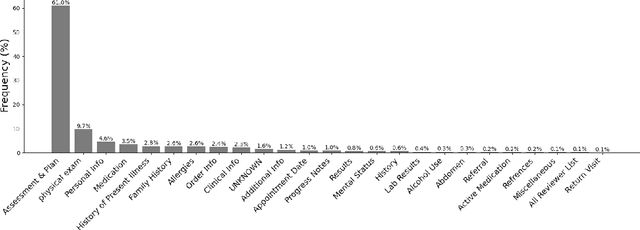
Electronic health records (EHR) even though a boon for healthcare practitioners, are growing convoluted and longer every day. Sifting around these lengthy EHRs is taxing and becomes a cumbersome part of physician-patient interaction. Several approaches have been proposed to help alleviate this prevalent issue either via summarization or sectioning, however, only a few approaches have truly been helpful in the past. With the rise of automated methods, machine learning (ML) has shown promise in solving the task of identifying relevant sections in EHR. However, most ML methods rely on labeled data which is difficult to get in healthcare. Large language models (LLMs) on the other hand, have performed impressive feats in natural language processing (NLP), that too in a zero-shot manner, i.e. without any labeled data. To that end, we propose using LLMs to identify relevant section headers. We find that GPT-4 can effectively solve the task on both zero and few-shot settings as well as segment dramatically better than state-of-the-art methods. Additionally, we also annotate a much harder real world dataset and find that GPT-4 struggles to perform well, alluding to further research and harder benchmarks.
Can GPT Improve the State of Prior Authorization via Guideline Based Automated Question Answering?
Feb 28, 2024


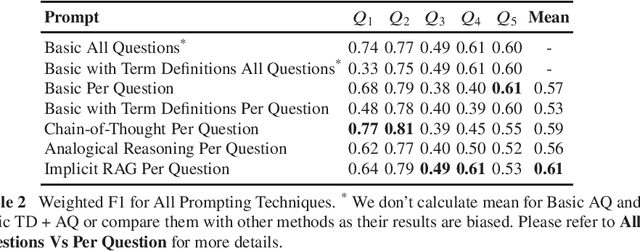
Health insurance companies have a defined process called prior authorization (PA) which is a health plan cost-control process that requires doctors and other healthcare professionals to get clearance in advance from a health plan before performing a particular procedure on a patient in order to be eligible for payment coverage. For health insurance companies, approving PA requests for patients in the medical domain is a time-consuming and challenging task. One of those key challenges is validating if a request matches up to certain criteria such as age, gender, etc. In this work, we evaluate whether GPT can validate numerous key factors, in turn helping health plans reach a decision drastically faster. We frame it as a question answering task, prompting GPT to answer a question from patient electronic health record. We experiment with different conventional prompting techniques as well as introduce our own novel prompting technique. Moreover, we report qualitative assessment by humans on the natural language generation outputs from our approach. Results show that our method achieves superior performance with the mean weighted F1 score of 0.61 as compared to its standard counterparts.
Emotion Classification in Low and Moderate Resource Languages
Feb 28, 2024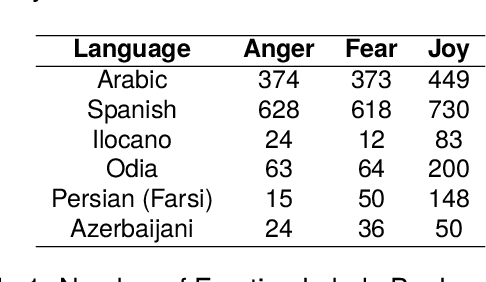

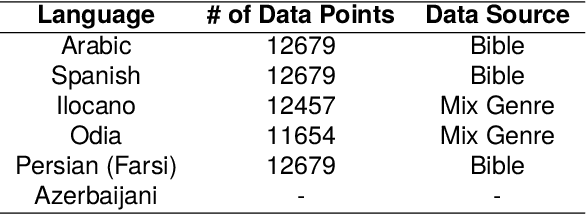

It is important to be able to analyze the emotional state of people around the globe. There are 7100+ active languages spoken around the world and building emotion classification for each language is labor intensive. Particularly for low-resource and endangered languages, building emotion classification can be quite challenging. We present a cross-lingual emotion classifier, where we train an emotion classifier with resource-rich languages (i.e. \textit{English} in our work) and transfer the learning to low and moderate resource languages. We compare and contrast two approaches of transfer learning from a high-resource language to a low or moderate-resource language. One approach projects the annotation from a high-resource language to low and moderate-resource language in parallel corpora and the other one uses direct transfer from high-resource language to the other languages. We show the efficacy of our approaches on 6 languages: Farsi, Arabic, Spanish, Ilocano, Odia, and Azerbaijani. Our results indicate that our approaches outperform random baselines and transfer emotions across languages successfully. For all languages, the direct cross-lingual transfer of emotion yields better results. We also create annotated emotion-labeled resources for four languages: Farsi, Azerbaijani, Ilocano and Odia.
Empathic Conversations: A Multi-level Dataset of Contextualized Conversations
May 25, 2022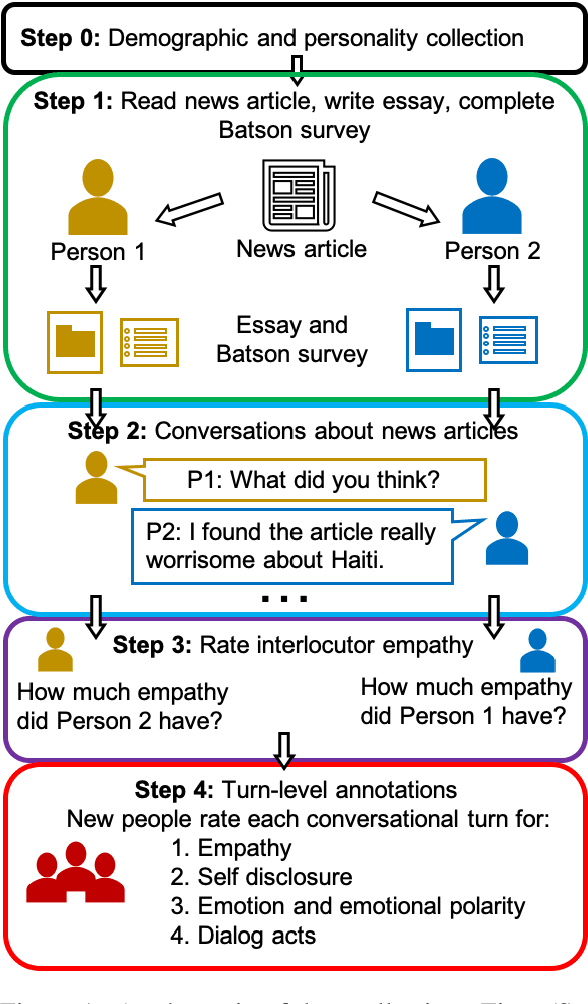
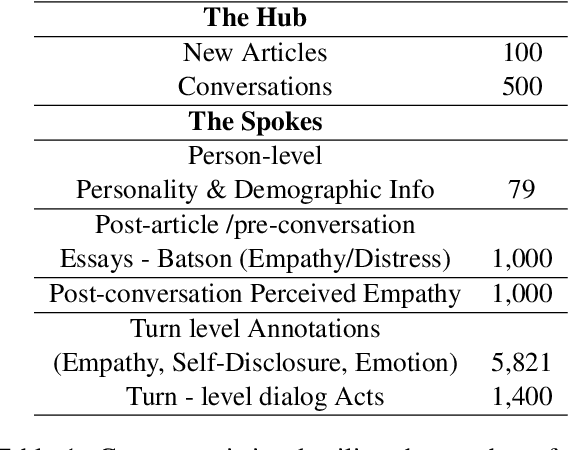
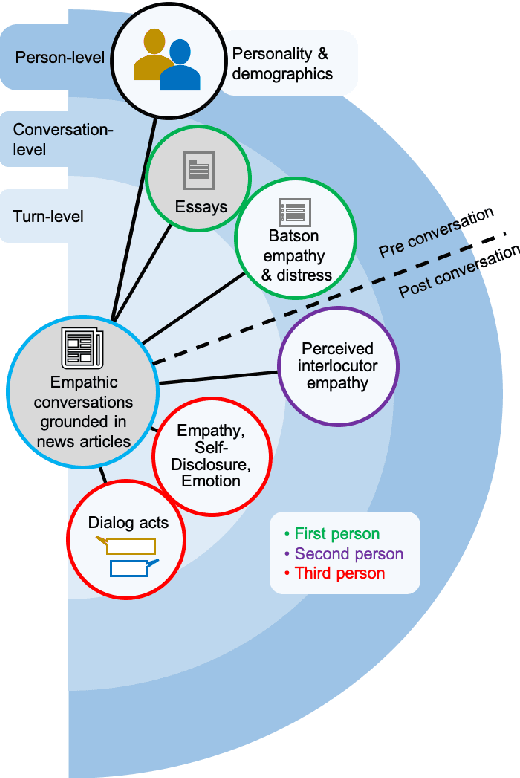
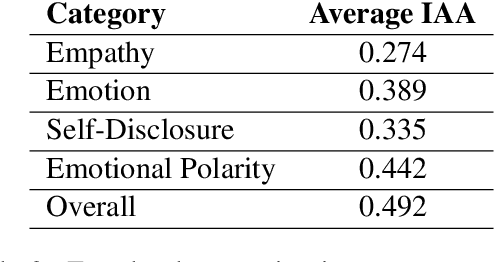
Empathy is a cognitive and emotional reaction to an observed situation of others. Empathy has recently attracted interest because it has numerous applications in psychology and AI, but it is unclear how different forms of empathy (e.g., self-report vs counterpart other-report, concern vs. distress) interact with other affective phenomena or demographics like gender and age. To better understand this, we created the {\it Empathic Conversations} dataset of annotated negative, empathy-eliciting dialogues in which pairs of participants converse about news articles. People differ in their perception of the empathy of others. These differences are associated with certain characteristics such as personality and demographics. Hence, we collected detailed characterization of the participants' traits, their self-reported empathetic response to news articles, their conversational partner other-report, and turn-by-turn third-party assessments of the level of self-disclosure, emotion, and empathy expressed. This dataset is the first to present empathy in multiple forms along with personal distress, emotion, personality characteristics, and person-level demographic information. We present baseline models for predicting some of these features from conversations.
GWU NLP Lab at SemEval-2019 Task 3: EmoContext: Effective Contextual Information in Models for Emotion Detection in Sentence-level in a Multigenre Corpus
May 23, 2019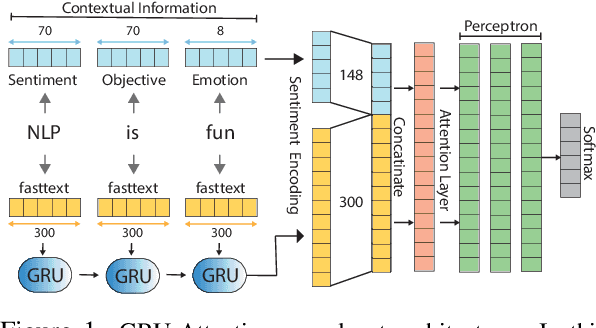


In this paper we present an emotion classifier model submitted to the SemEval-2019 Task 3: EmoContext. The task objective is to classify emotion (i.e. happy, sad, angry) in a 3-turn conversational data set. We formulate the task as a classification problem and introduce a Gated Recurrent Neural Network (GRU) model with attention layer, which is bootstrapped with contextual information and trained with a multigenre corpus. We utilize different word embeddings to empirically select the most suited one to represent our features. We train the model with a multigenre emotion corpus to leverage using all available training sets to bootstrap the results. We achieved overall %56.05 f1-score and placed 144.
The ARIEL-CMU Systems for LoReHLT18
Feb 24, 2019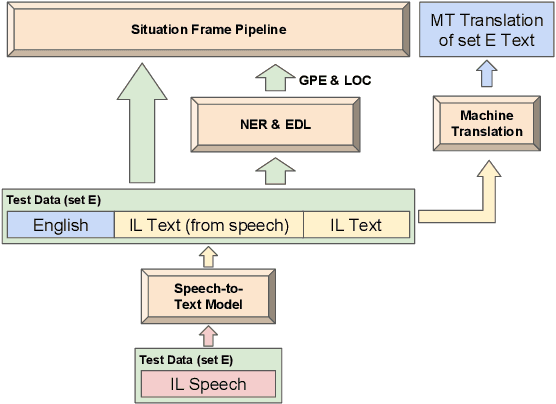
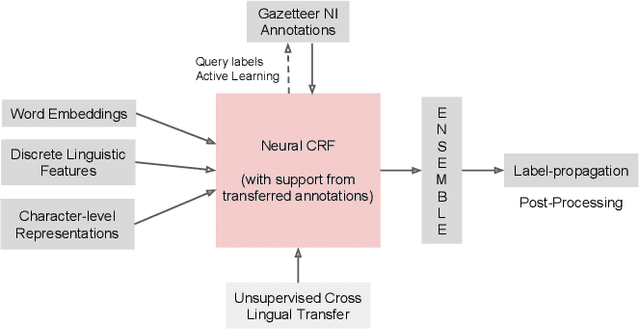
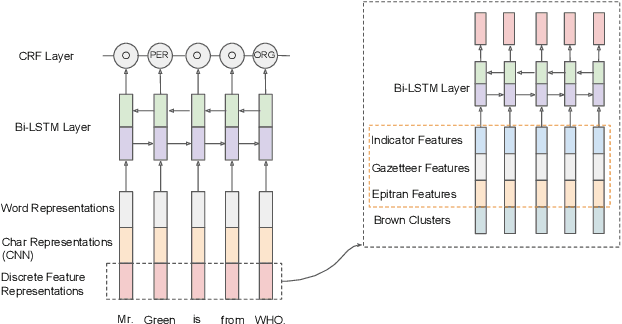
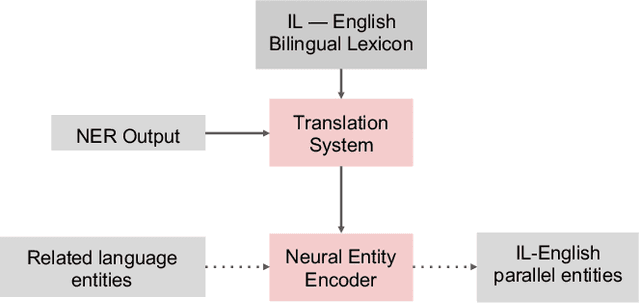
This paper describes the ARIEL-CMU submissions to the Low Resource Human Language Technologies (LoReHLT) 2018 evaluations for the tasks Machine Translation (MT), Entity Discovery and Linking (EDL), and detection of Situation Frames in Text and Speech (SF Text and Speech).