 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidualized Factor Adaptation for Community Social Media Prediction Tasks
Aug 28, 2018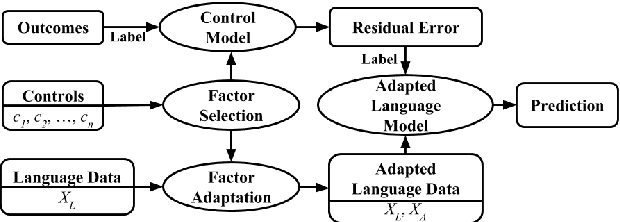
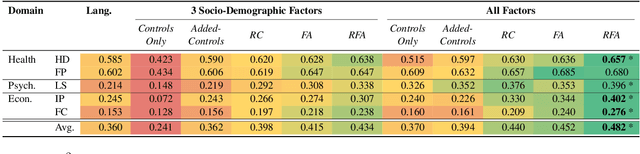
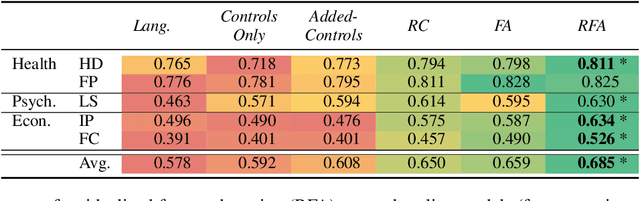
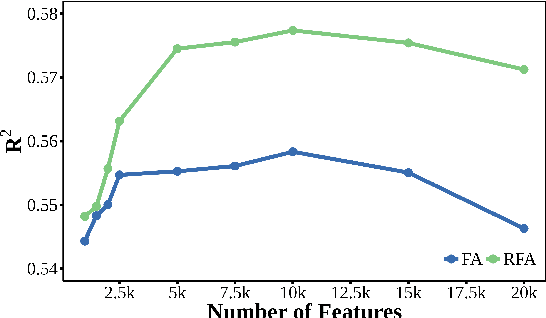
Predictive models over social media language have shown promise in capturing community outcomes, but approaches thus far largely neglect the socio-demographic context (e.g. age, education rates, race) of the community from which the language originates. For example, it may be inaccurate to assume people in Mobile, Alabama, where the population is relatively older, will use words the same way as those from San Francisco, where the median age is younger with a higher rate of college education. In this paper, we present residualized factor adaptation, a novel approach to community prediction tasks which both (a) effectively integrates community attributes, as well as (b) adapts linguistic features to community attributes (factors). We use eleven demographic and socioeconomic attributes, and evaluate our approach over five different community-level predictive tasks, spanning health (heart disease mortality, percent fair/poor health), psychology (life satisfaction), and economics (percent housing price increase, foreclosure rate). Our evaluation shows that residualized factor adaptation significantly improves 4 out of 5 community-level outcome predictions over prior state-of-the-art for incorporating socio-demographic contexts.
Predicting Human Trustfulness from Facebook Language
Aug 16, 2018
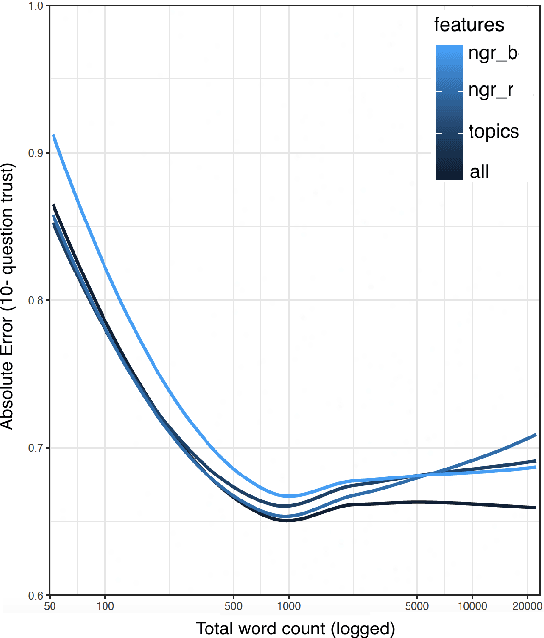
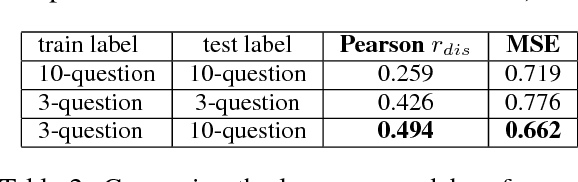
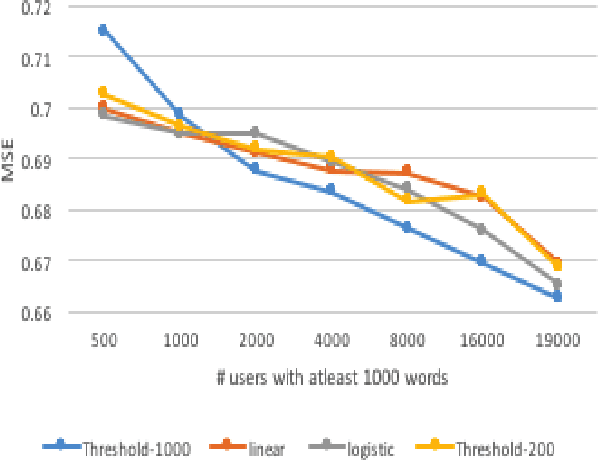
Trustfulness -- one's general tendency to have confidence in unknown people or situations -- predicts many important real-world outcomes such as mental health and likelihood to cooperate with others such as clinicians. While data-driven measures of interpersonal trust have previously been introduced, here, we develop the first language-based assessment of the personality trait of trustfulness by fitting one's language to an accepted questionnaire-based trust score. Further, using trustfulness as a type of case study, we explore the role of questionnaire size as well as word count in developing language-based predictive models of users' psychological traits. We find that leveraging a longer questionnaire can yield greater test set accuracy, while, for training, we find it beneficial to include users who took smaller questionnaires which offers more observations for training. Similarly, after noting a decrease in individual prediction error as word count increased, we found a word count-weighted training scheme was helpful when there were very few users in the first place.
* CLPsych2018
Cascading Randomized Weighted Majority: A New Online Ensemble Learning Algorithm
Feb 02, 2015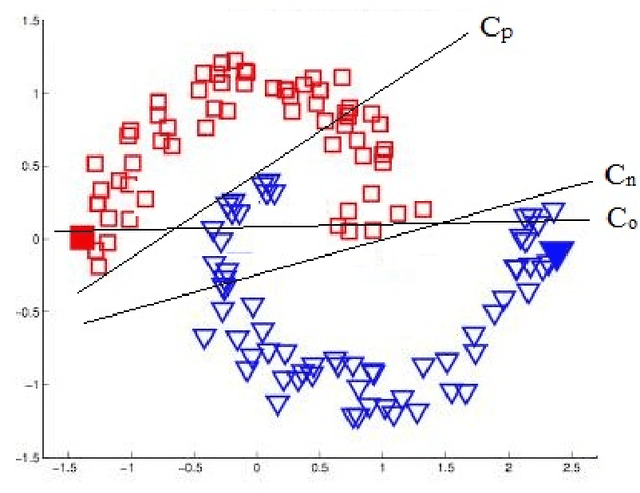
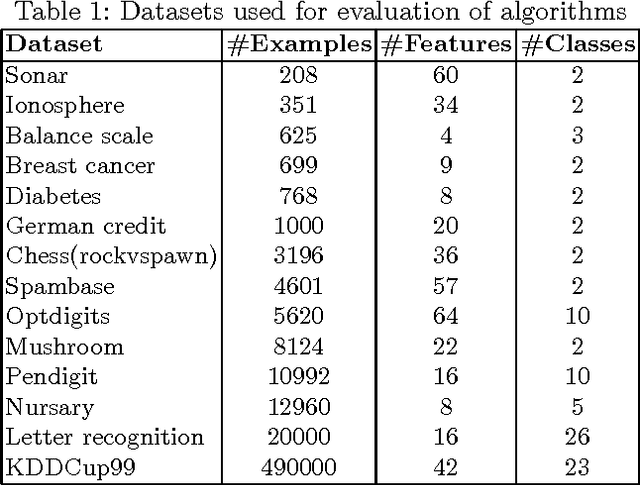
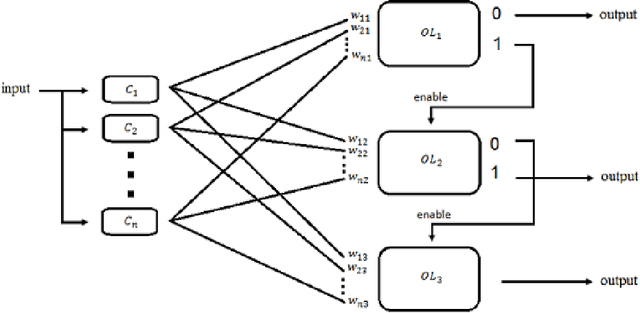
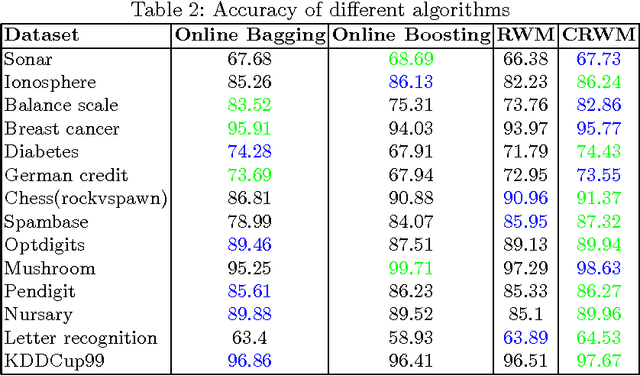
With the increasing volume of data in the world, the best approach for learning from this data is to exploit an online learning algorithm. Online ensemble methods are online algorithms which take advantage of an ensemble of classifiers to predict labels of data. Prediction with expert advice is a well-studied problem in the online ensemble learning literature. The Weighted Majority algorithm and the randomized weighted majority (RWM) are the most well-known solutions to this problem, aiming to converge to the best expert. Since among some expert, the best one does not necessarily have the minimum error in all regions of data space, defining specific regions and converging to the best expert in each of these regions will lead to a better result. In this paper, we aim to resolve this defect of RWM algorithms by proposing a novel online ensemble algorithm to the problem of prediction with expert advice. We propose a cascading version of RWM to achieve not only better experimental results but also a better error bound for sufficiently large datasets.