 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot-Just-Scaling Laws: Towards a Better Understanding of the Downstream Impact of Language Model Design Decisions
Mar 05, 2025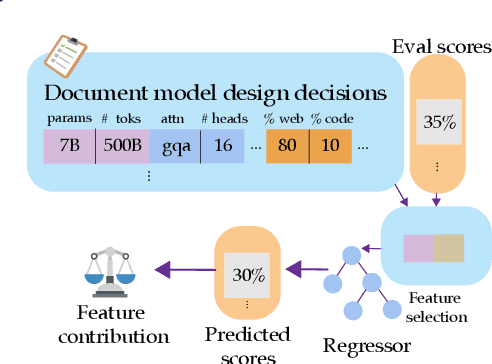
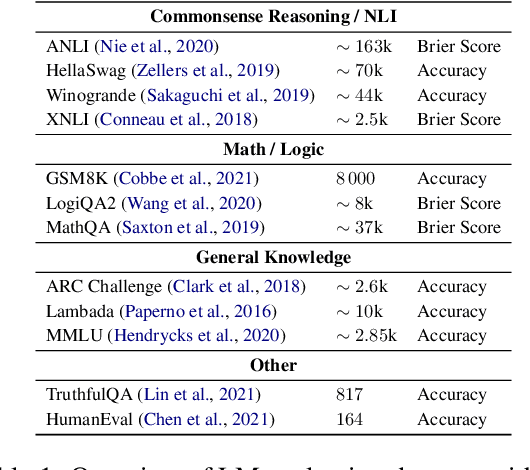
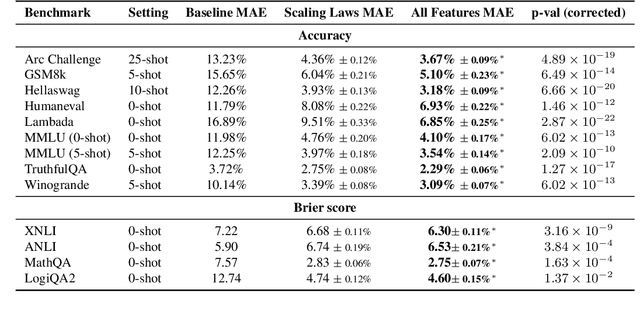
Improvements in language model capabilities are often attributed to increasing model size or training data, but in some cases smaller models trained on curated data or with different architectural decisions can outperform larger ones trained on more tokens. What accounts for this? To quantify the impact of these design choices, we meta-analyze 92 open-source pretrained models across a wide array of scales, including state-of-the-art open-weights models as well as less performant models and those with less conventional design decisions. We find that by incorporating features besides model size and number of training tokens, we can achieve a relative 3-28% increase in ability to predict downstream performance compared with using scale alone. Analysis of model design decisions reveal insights into data composition, such as the trade-off between language and code tasks at 15-25\% code, as well as the better performance of some architectural decisions such as choosing rotary over learned embeddings. Broadly, our framework lays a foundation for more systematic investigation of how model development choices shape final capabilities.