 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivergences between Language Models and Human Brains
Paper and Code
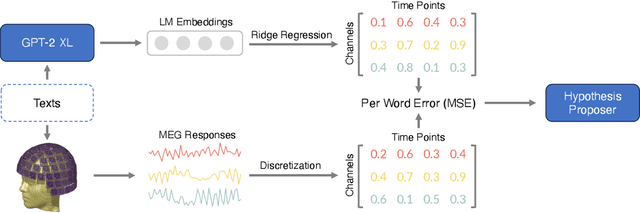


Do machines and humans process language in similar ways? A recent line of research has hinted in the affirmative, demonstrating that human brain signals can be effectively predicted using the internal representations of language models (LMs). This is thought to reflect shared computational principles between LMs and human language processing. However, there are also clear differences in how LMs and humans acquire and use language, even if the final task they are performing is the same. Despite this, there is little work exploring systematic differences between human and machine language processing using brain data. To address this question, we examine the differences between LM representations and the human brain's responses to language, specifically by examining a dataset of Magnetoencephalography (MEG) responses to a written narrative. In doing so we identify three phenomena that, in prior work, LMs have been found to not capture well: emotional understanding, figurative language processing, and physical commonsense. By fine-tuning LMs on datasets related to these phenomena, we observe that fine-tuned LMs show improved alignment with human brain responses across these tasks. Our study implies that the observed divergences between LMs and human brains may stem from LMs' inadequate representation of these specific types of knowledge.