 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnippet-based Conversational Recommender System
Nov 09, 2024



Conversational Recommender Systems (CRS) engage users in interactive dialogues to gather preferences and provide personalized recommendations. Traditionally, CRS rely on pre-defined attributes or expensive, domain-specific annotated datasets to guide conversations, which limits flexibility and adaptability across domains. In this work, we introduce SnipRec, a novel CRS that enhances dialogues and recommendations by extracting diverse expressions and preferences from user-generated content (UGC) like customer reviews. Using large language models, SnipRec maps user responses and UGC to concise snippets, which are used to generate clarification questions and retrieve relevant items. Our approach eliminates the need for domain-specific training, making it adaptable to new domains and effective without prior knowledge of user preferences. Extensive experiments on the Yelp dataset demonstrate the effectiveness of snippet-based representations against document and sentence-based representations. Additionally, SnipRec is able to improve Hits@10 by 0.25 over the course of five conversational turns, underscoring the efficiency of SnipRec in capturing user preferences through multi-turn conversations.
LinK3D: Linear Keypoints Representation for 3D LiDAR Point Cloud
Jun 13, 2022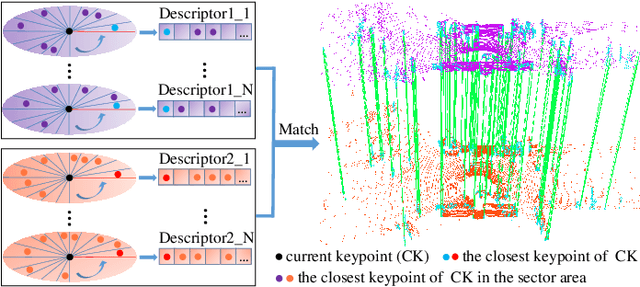

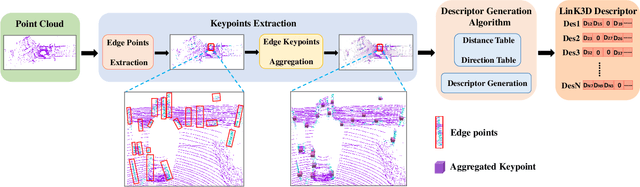
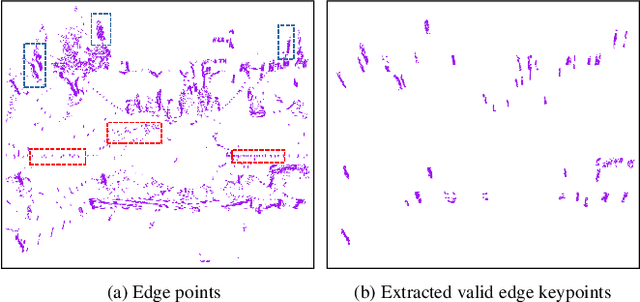
Feature extraction and matching are the basic parts of many computer vision tasks, such as 2D or 3D object detection, recognition, and registration. As we all know, 2D feature extraction and matching have already been achieved great success. Unfortunately, in the field of 3D, the current methods fail to support the extensive application of 3D LiDAR sensors in vision tasks, due to the poor descriptiveness and inefficiency. To address this limitation, we propose a novel 3D feature representation method: Linear Keypoints representation for 3D LiDAR point cloud, called LinK3D. The novelty of LinK3D lies in that it fully considers the characteristics (such as sparsity, complexity of scenarios) of LiDAR point cloud, and represents current keypoint with its robust neighbor keypoints, which provide strong constraint on the description of current keypoint. The proposed LinK3D has been evaluated on two public datasets (i.e., KITTI, Steven VLP16), and the experimental results show that our method greatly outperforms the state-of-the-arts in matching performance. More importantly, LinK3D shows excellent real-time performance (based on the frequence 10 Hz of LiDAR). LinK3D only takes an average of 32 milliseconds to extract features from the point cloud collected by a 64-ray laser beam, and takes merely about 8 milliseconds to match two LiDAR scans when executed in a notebook with an Intel Core i7 @2.2 GHz processor. Moreover, our method can be widely extended to a variety of 3D vision applications. In this paper, we has applied our LinK3D to 3D registration, LiDAR odometry and place recognition tasks, and achieved competitive results compared with the state-of-the-art methods.