 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding What Code Language Models Learned
Jun 20, 2023



Pre-trained language models are effective in a variety of natural language tasks, but it has been argued their capabilities fall short of fully learning meaning or understanding language. To understand the extent to which language models can learn some form of meaning, we investigate their ability to capture semantics of code beyond superficial frequency and co-occurrence. In contrast to previous research on probing models for linguistic features, we study pre-trained models in a setting that allows for objective and straightforward evaluation of a model's ability to learn semantics. In this paper, we examine whether such models capture the semantics of code, which is precisely and formally defined. Through experiments involving the manipulation of code fragments, we show that code pre-trained models of code learn a robust representation of the computational semantics of code that goes beyond superficial features of form alone
Automatically Exposing Problems with Neural Dialog Models
Sep 14, 2021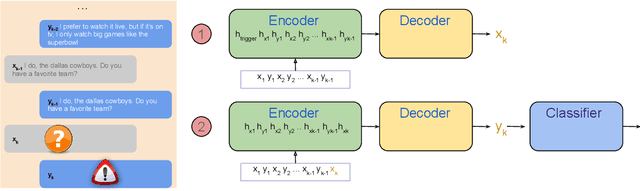


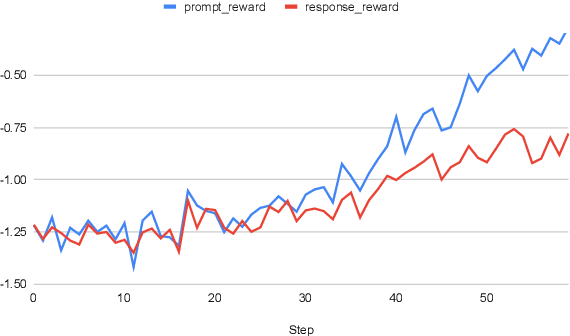
Neural dialog models are known to suffer from problems such as generating unsafe and inconsistent responses. Even though these problems are crucial and prevalent, they are mostly manually identified by model designers through interactions. Recently, some research instructs crowdworkers to goad the bots into triggering such problems. However, humans leverage superficial clues such as hate speech, while leaving systematic problems undercover. In this paper, we propose two methods including reinforcement learning to automatically trigger a dialog model into generating problematic responses. We show the effect of our methods in exposing safety and contradiction issues with state-of-the-art dialog models.
Language Embeddings for Typology and Cross-lingual Transfer Learning
Jun 03, 2021
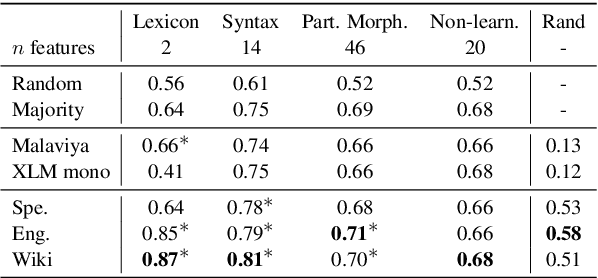
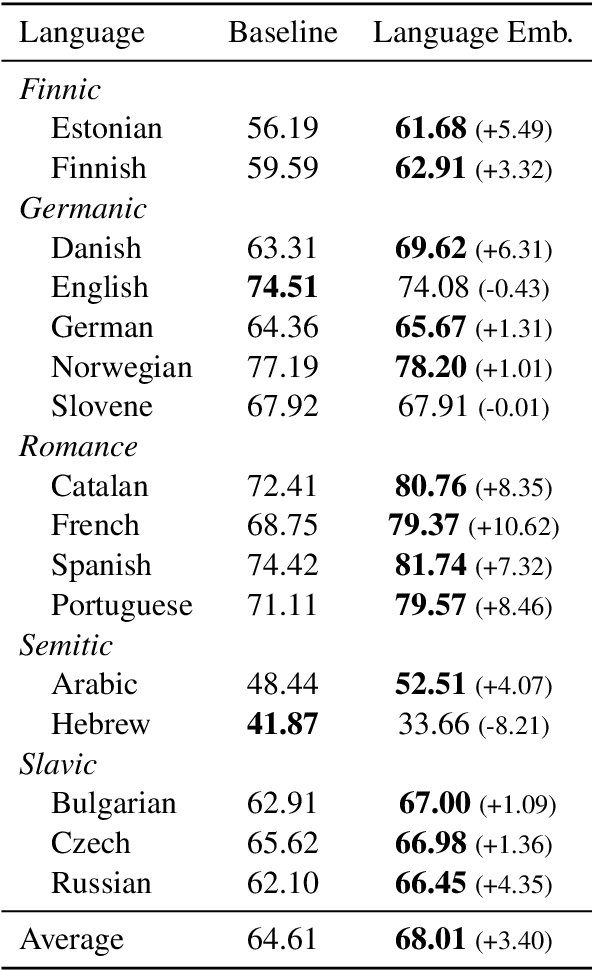
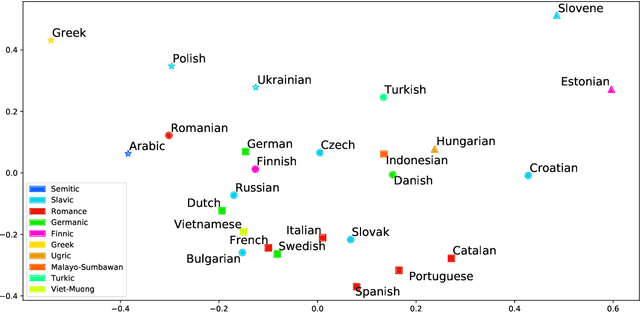
Cross-lingual language tasks typically require a substantial amount of annotated data or parallel translation data. We explore whether language representations that capture relationships among languages can be learned and subsequently leveraged in cross-lingual tasks without the use of parallel data. We generate dense embeddings for 29 languages using a denoising autoencoder, and evaluate the embeddings using the World Atlas of Language Structures (WALS) and two extrinsic tasks in a zero-shot setting: cross-lingual dependency parsing and cross-lingual natural language inference.
Attribute Alignment: Controlling Text Generation from Pre-trained Language Models
Mar 20, 2021
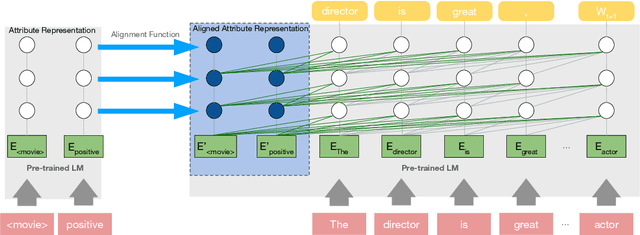

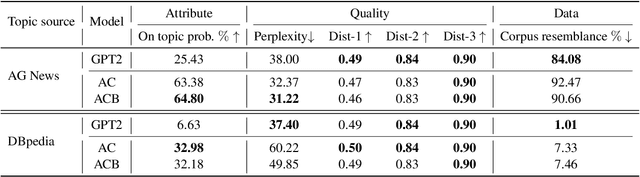
Large language models benefit from training with a large amount of unlabeled text, which gives them increasingly fluent and diverse generation capabilities. However, using these models for text generation that takes into account target attributes, such as sentiment polarity or specific topics, remains a challenge. We propose a simple and flexible method for controlling text generation by aligning disentangled attribute representations. In contrast to recent efforts on training a discriminator to perturb the token level distribution for an attribute, we use the same data to learn an alignment function to guide the pre-trained, non-controlled language model to generate texts with the target attribute without changing the original language model parameters. We evaluate our method on sentiment- and topic-controlled generation, and show large performance gains over previous methods while retaining fluency and diversity.
Studying the Difference Between Natural and Programming Language Corpora
Jun 06, 2018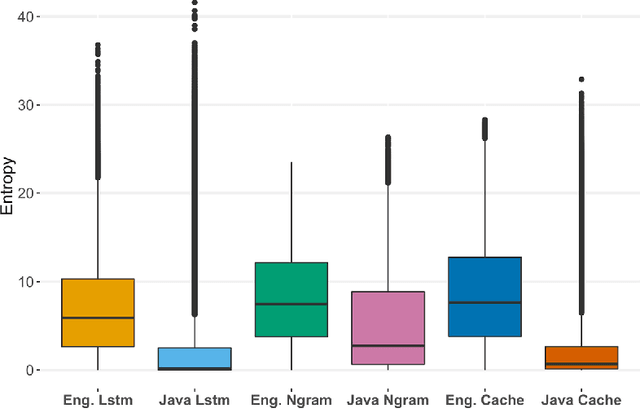
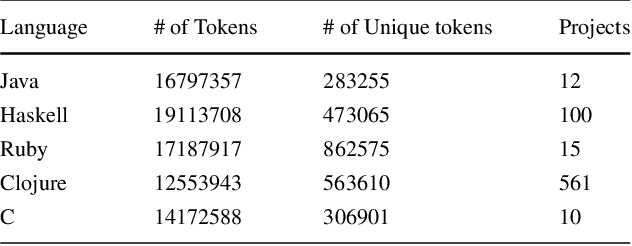
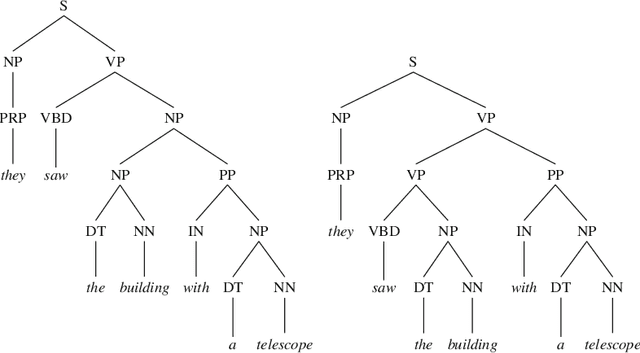
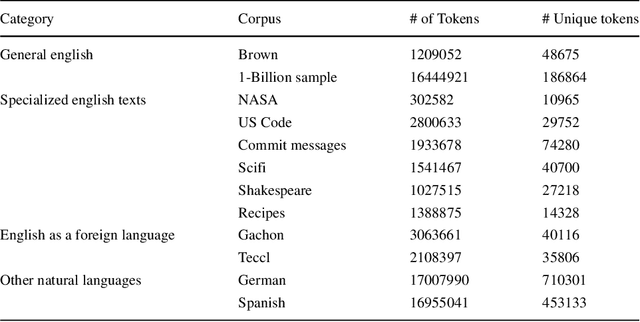
Code corpora, as observed in large software systems, are now known to be far more repetitive and predictable than natural language corpora. But why? Does the difference simply arise from the syntactic limitations of programming languages? Or does it arise from the differences in authoring decisions made by the writers of these natural and programming language texts? We conjecture that the differences are not entirely due to syntax, but also from the fact that reading and writing code is un-natural for humans, and requires substantial mental effort; so, people prefer to write code in ways that are familiar to both reader and writer. To support this argument, we present results from two sets of studies: 1) a first set aimed at attenuating the effects of syntax, and 2) a second, aimed at measuring repetitiveness of text written in other settings (e.g. second language, technical/specialized jargon), which are also effortful to write. We find find that this repetition in source code is not entirely the result of grammar constraints, and thus some repetition must result from human choice. While the evidence we find of similar repetitive behavior in technical and learner corpora does not conclusively show that such language is used by humans to mitigate difficulty, it is consistent with that theory.
Fast Rhetorical Structure Theory Discourse Parsing
May 10, 2015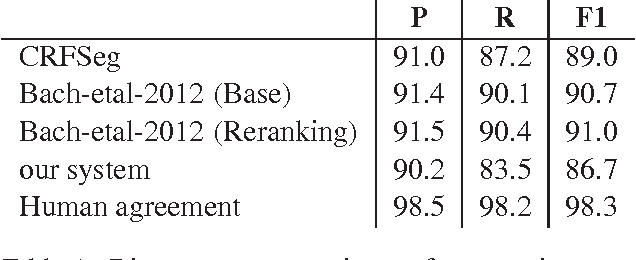
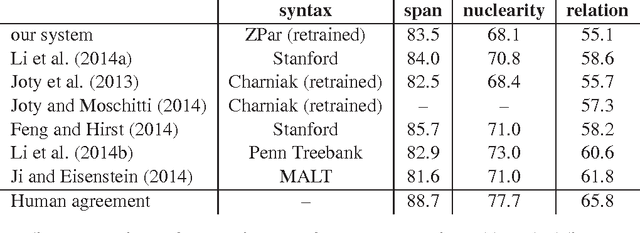

In recent years, There has been a variety of research on discourse parsing, particularly RST discourse parsing. Most of the recent work on RST parsing has focused on implementing new types of features or learning algorithms in order to improve accuracy, with relatively little focus on efficiency, robustness, or practical use. Also, most implementations are not widely available. Here, we describe an RST segmentation and parsing system that adapts models and feature sets from various previous work, as described below. Its accuracy is near state-of-the-art, and it was developed to be fast, robust, and practical. For example, it can process short documents such as news articles or essays in less than a second.