 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding What Code Language Models Learned
Jun 20, 2023Pre-trained language models are effective in a variety of natural language tasks, but it has been argued their capabilities fall short of fully learning meaning or understanding language. To understand the extent to which language models can learn some form of meaning, we investigate their ability to capture semantics of code beyond superficial frequency and co-occurrence. In contrast to previous research on probing models for linguistic features, we study pre-trained models in a setting that allows for objective and straightforward evaluation of a model's ability to learn semantics. In this paper, we examine whether such models capture the semantics of code, which is precisely and formally defined. Through experiments involving the manipulation of code fragments, we show that code pre-trained models of code learn a robust representation of the computational semantics of code that goes beyond superficial features of form alone
Using Machine Learning and Natural Language Processing to Review and Classify the Medical Literature on Cancer Susceptibility Genes
Apr 24, 2019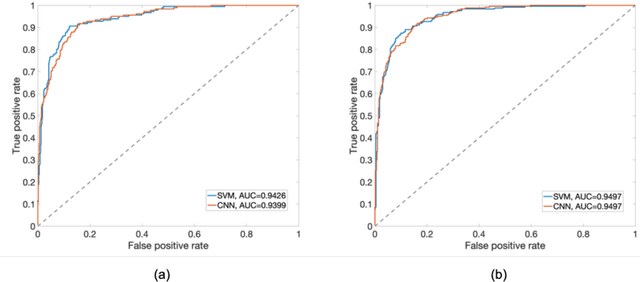
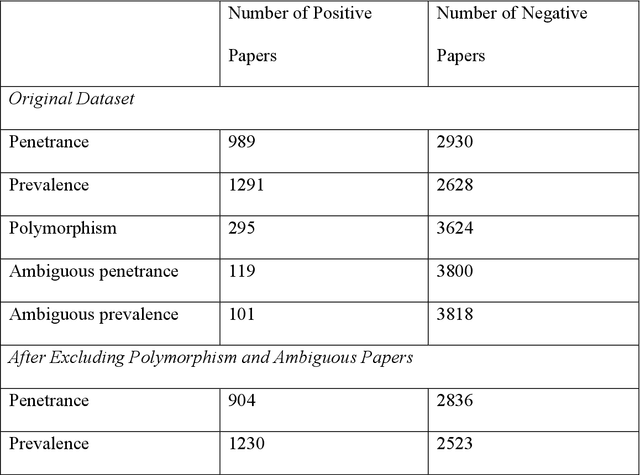
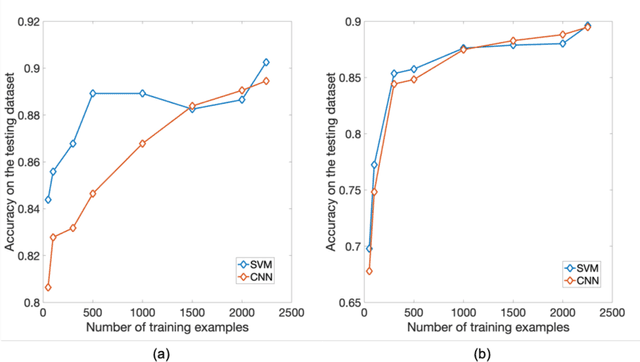
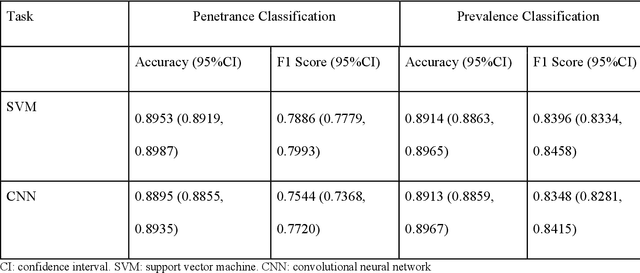
PURPOSE: The medical literature relevant to germline genetics is growing exponentially. Clinicians need tools monitoring and prioritizing the literature to understand the clinical implications of the pathogenic genetic variants. We developed and evaluated two machine learning models to classify abstracts as relevant to the penetrance (risk of cancer for germline mutation carriers) or prevalence of germline genetic mutations. METHODS: We conducted literature searches in PubMed and retrieved paper titles and abstracts to create an annotated dataset for training and evaluating the two machine learning classification models. Our first model is a support vector machine (SVM) which learns a linear decision rule based on the bag-of-ngrams representation of each title and abstract. Our second model is a convolutional neural network (CNN) which learns a complex nonlinear decision rule based on the raw title and abstract. We evaluated the performance of the two models on the classification of papers as relevant to penetrance or prevalence. RESULTS: For penetrance classification, we annotated 3740 paper titles and abstracts and used 60% for training the model, 20% for tuning the model, and 20% for evaluating the model. The SVM model achieves 89.53% accuracy (percentage of papers that were correctly classified) while the CNN model achieves 88.95 % accuracy. For prevalence classification, we annotated 3753 paper titles and abstracts. The SVM model achieves 89.14% accuracy while the CNN model achieves 89.13 % accuracy. CONCLUSION: Our models achieve high accuracy in classifying abstracts as relevant to penetrance or prevalence. By facilitating literature review, this tool could help clinicians and researchers keep abreast of the burgeoning knowledge of gene-cancer associations and keep the knowledge bases for clinical decision support tools up to date.