Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Rhetorical Structure Theory Discourse Parsing
Paper and Code
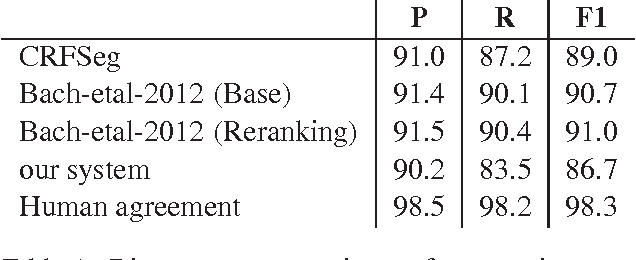
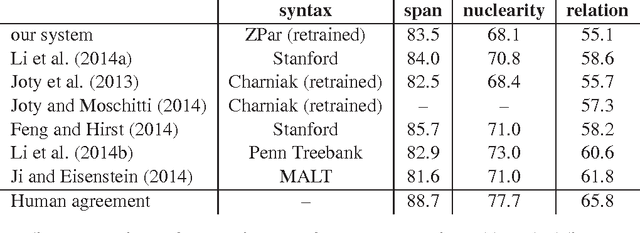

In recent years, There has been a variety of research on discourse parsing, particularly RST discourse parsing. Most of the recent work on RST parsing has focused on implementing new types of features or learning algorithms in order to improve accuracy, with relatively little focus on efficiency, robustness, or practical use. Also, most implementations are not widely available. Here, we describe an RST segmentation and parsing system that adapts models and feature sets from various previous work, as described below. Its accuracy is near state-of-the-art, and it was developed to be fast, robust, and practical. For example, it can process short documents such as news articles or essays in less than a second.
View paper on