 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding When Tree of Thoughts Succeeds: Larger Models Excel in Generation, Not Discrimination
Paper and Code
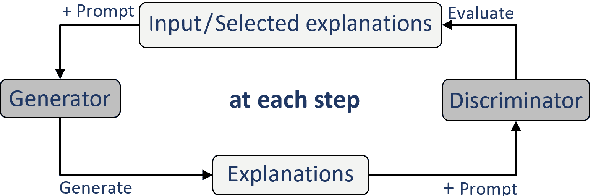
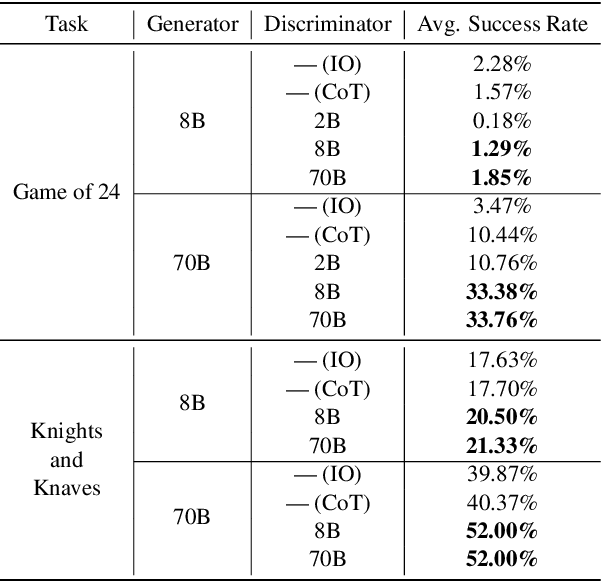

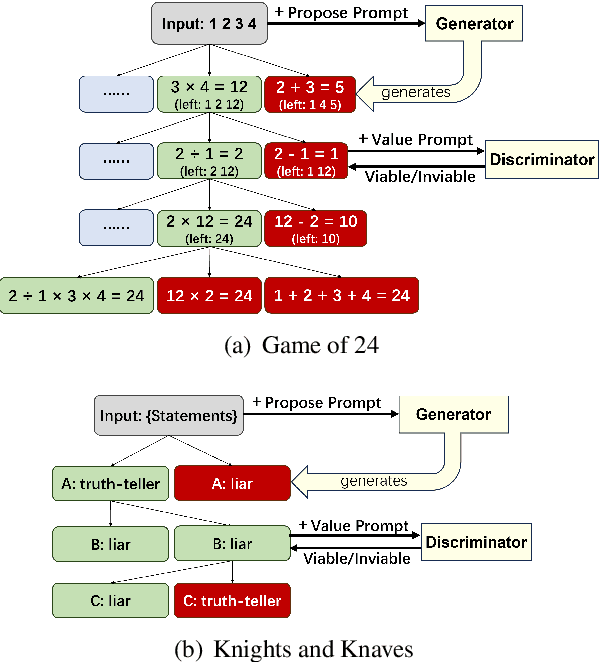
Tree of Thoughts (ToT) is a reasoning strategy for Large Language Models (LLMs) that employs a generator to suggest reasoning steps and a discriminator to decide which steps to implement. ToT demonstrates strong performance on reasoning tasks, often surpassing simple methods such as Input-Output (IO) prompting and Chain-of-Thought (CoT) reasoning. However, ToT does not consistently outperform such simpler methods across all models, leaving large knowledge gaps on the conditions under which ToT is most beneficial. In this paper, we analyze the roles of the generator and discriminator separately to better understand the conditions when ToT is beneficial. We find that the generator plays a more critical role than the discriminator in driving the success of ToT. Scaling the generator leads to notable improvements in ToT performance, even when using a smaller model as the discriminator, whereas scaling the discriminator with a fixed generator yields only marginal gains. Our results show that models across different scales exhibit comparable discrimination capabilities, yet differ significantly in their generative performance for ToT.