 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIB: A Mechanistic Interpretability Benchmark
Apr 17, 2025



How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or specific causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and locate model features for a causal variable relevant to the task. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., standard dimensions of hidden vectors. These findings illustrate that MIB enables meaningful comparisons of methods, and increases our confidence that there has been real progress in the field.
Are formal and functional linguistic mechanisms dissociated?
Mar 14, 2025Although large language models (LLMs) are increasingly capable, these capabilities are unevenly distributed: they excel at formal linguistic tasks, such as producing fluent, grammatical text, but struggle more with functional linguistic tasks like reasoning and consistent fact retrieval. Inspired by neuroscience, recent work suggests that to succeed on both formal and functional linguistic tasks, LLMs should use different mechanisms for each; such localization could either be built-in or emerge spontaneously through training. In this paper, we ask: do current models, with fast-improving functional linguistic abilities, exhibit distinct localization of formal and functional linguistic mechanisms? We answer this by finding and comparing the "circuits", or minimal computational subgraphs, responsible for various formal and functional tasks. Comparing 5 LLMs across 10 distinct tasks, we find that while there is indeed little overlap between circuits for formal and functional tasks, there is also little overlap between formal linguistic tasks, as exists in the human brain. Thus, a single formal linguistic network, unified and distinct from functional task circuits, remains elusive. However, in terms of cross-task faithfulness - the ability of one circuit to solve another's task - we observe a separation between formal and functional mechanisms, suggesting that shared mechanisms between formal tasks may exist.
Incremental Sentence Processing Mechanisms in Autoregressive Transformer Language Models
Dec 06, 2024Autoregressive transformer language models (LMs) possess strong syntactic abilities, often successfully handling phenomena from agreement to NPI licensing. However, the features they use to incrementally process language inputs are not well understood. In this paper, we fill this gap by studying the mechanisms underlying garden path sentence processing in LMs. We ask: (1) Do LMs use syntactic features or shallow heuristics to perform incremental sentence processing? (2) Do LMs represent only one potential interpretation, or multiple? and (3) Do LMs reanalyze or repair their initial incorrect representations? To address these questions, we use sparse autoencoders to identify interpretable features that determine which continuation - and thus which reading - of a garden path sentence the LM prefers. We find that while many important features relate to syntactic structure, some reflect syntactically irrelevant heuristics. Moreover, while most active features correspond to one reading of the sentence, some features correspond to the other, suggesting that LMs assign weight to both possibilities simultaneously. Finally, LMs do not re-use features from garden path sentence processing to answer follow-up questions.
LLM Circuit Analyses Are Consistent Across Training and Scale
Jul 15, 2024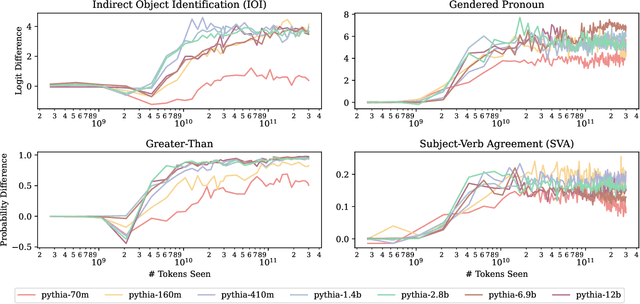
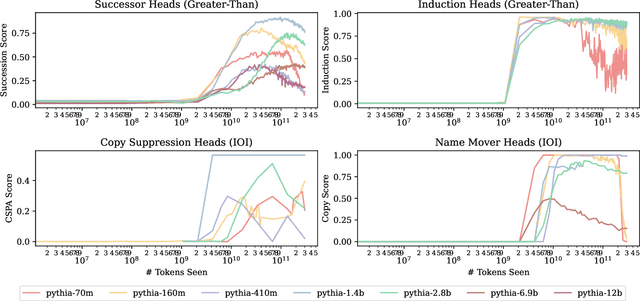
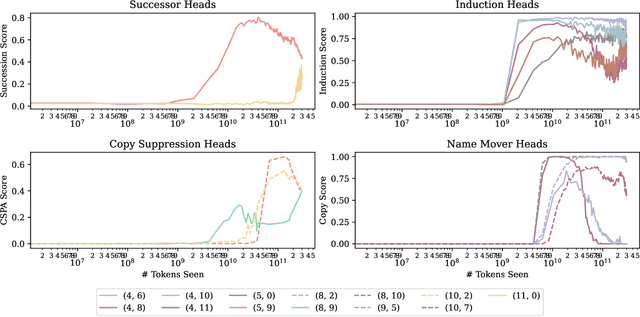
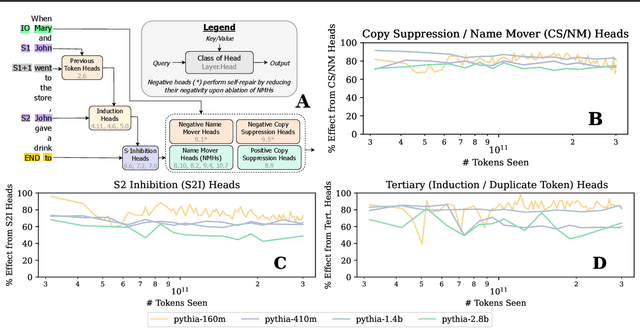
Most currently deployed large language models (LLMs) undergo continuous training or additional finetuning. By contrast, most research into LLMs' internal mechanisms focuses on models at one snapshot in time (the end of pre-training), raising the question of whether their results generalize to real-world settings. Existing studies of mechanisms over time focus on encoder-only or toy models, which differ significantly from most deployed models. In this study, we track how model mechanisms, operationalized as circuits, emerge and evolve across 300 billion tokens of training in decoder-only LLMs, in models ranging from 70 million to 2.8 billion parameters. We find that task abilities and the functional components that support them emerge consistently at similar token counts across scale. Moreover, although such components may be implemented by different attention heads over time, the overarching algorithm that they implement remains. Surprisingly, both these algorithms and the types of components involved therein can replicate across model scale. These results suggest that circuit analyses conducted on small models at the end of pre-training can provide insights that still apply after additional pre-training and over model scale.
LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
Jun 26, 2024
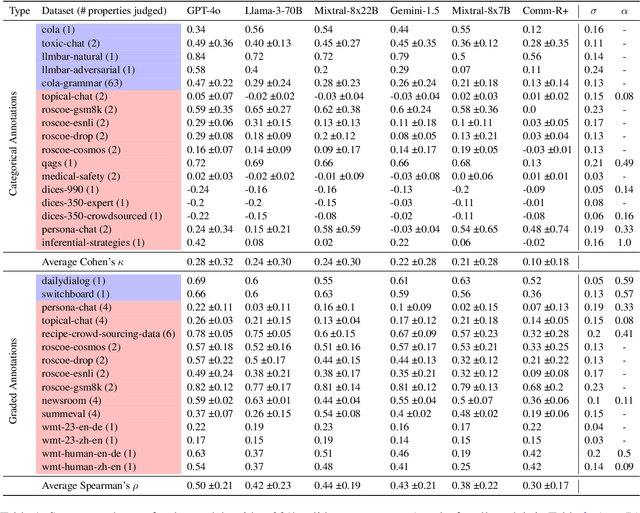
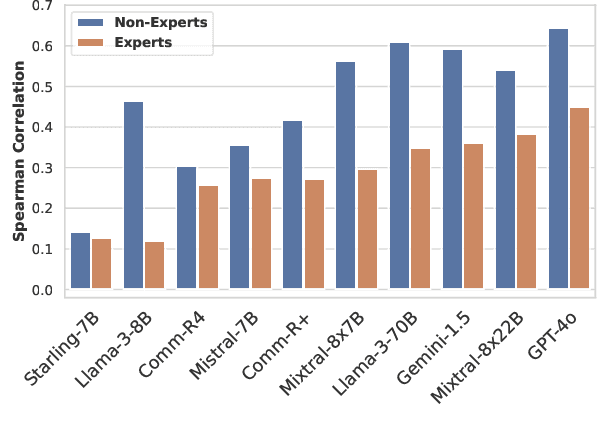
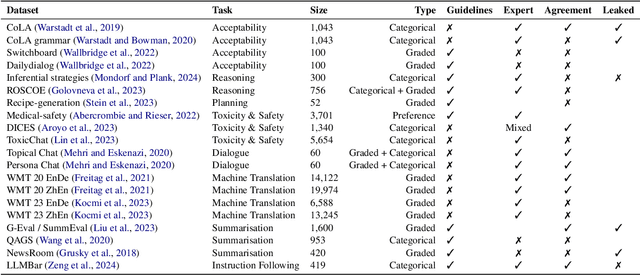
There is an increasing trend towards evaluating NLP models with LLM-generated judgments instead of human judgments. In the absence of a comparison against human data, this raises concerns about the validity of these evaluations; in case they are conducted with proprietary models, this also raises concerns over reproducibility. We provide JUDGE-BENCH, a collection of 20 NLP datasets with human annotations, and comprehensively evaluate 11 current LLMs, covering both open-weight and proprietary models, for their ability to replicate the annotations. Our evaluations show that each LLM exhibits a large variance across datasets in its correlation to human judgments. We conclude that LLMs are not yet ready to systematically replace human judges in NLP.
Have Faith in Faithfulness: Going Beyond Circuit Overlap When Finding Model Mechanisms
Mar 26, 2024Many recent language model (LM) interpretability studies have adopted the circuits framework, which aims to find the minimal computational subgraph, or circuit, that explains LM behavior on a given task. Most studies determine which edges belong in a LM's circuit by performing causal interventions on each edge independently, but this scales poorly with model size. Edge attribution patching (EAP), gradient-based approximation to interventions, has emerged as a scalable but imperfect solution to this problem. In this paper, we introduce a new method - EAP with integrated gradients (EAP-IG) - that aims to better maintain a core property of circuits: faithfulness. A circuit is faithful if all model edges outside the circuit can be ablated without changing the model's performance on the task; faithfulness is what justifies studying circuits, rather than the full model. Our experiments demonstrate that circuits found using EAP are less faithful than those found using EAP-IG, even though both have high node overlap with circuits found previously using causal interventions. We conclude more generally that when using circuits to compare the mechanisms models use to solve tasks, faithfulness, not overlap, is what should be measured.
Do Pre-Trained Language Models Detect and Understand Semantic Underspecification? Ask the DUST!
Feb 19, 2024



In everyday language use, speakers frequently utter and interpret sentences that are semantically underspecified, namely, whose content is insufficient to fully convey their message or interpret them univocally. For example, to interpret the underspecified sentence "Don't spend too much", which leaves implicit what (not) to spend, additional linguistic context or outside knowledge is needed. In this work, we propose a novel Dataset of semantically Underspecified Sentences grouped by Type (DUST) and use it to study whether pre-trained language models (LMs) correctly identify and interpret underspecified sentences. We find that newer LMs are reasonably able to identify underspecified sentences when explicitly prompted. However, interpreting them correctly is much harder for any LMs. Our experiments show that when interpreting underspecified sentences, LMs exhibit little uncertainty, contrary to what theoretical accounts of underspecification would predict. Overall, our study reveals limitations in current models' processing of sentence semantics and highlights the importance of using naturalistic data and communicative scenarios when evaluating LMs' language capabilities.
When Language Models Fall in Love: Animacy Processing in Transformer Language Models
Oct 23, 2023Animacy - whether an entity is alive and sentient - is fundamental to cognitive processing, impacting areas such as memory, vision, and language. However, animacy is not always expressed directly in language: in English it often manifests indirectly, in the form of selectional constraints on verbs and adjectives. This poses a potential issue for transformer language models (LMs): they often train only on text, and thus lack access to extralinguistic information from which humans learn about animacy. We ask: how does this impact LMs' animacy processing - do they still behave as humans do? We answer this question using open-source LMs. Like previous studies, we find that LMs behave much like humans when presented with entities whose animacy is typical. However, we also show that even when presented with stories about atypically animate entities, such as a peanut in love, LMs adapt: they treat these entities as animate, though they do not adapt as well as humans. Even when the context indicating atypical animacy is very short, LMs pick up on subtle clues and change their behavior. We conclude that despite the limited signal through which LMs can learn about animacy, they are indeed sensitive to the relevant lexical semantic nuances available in English.
Identifying and Adapting Transformer-Components Responsible for Gender Bias in an English Language Model
Oct 19, 2023



Language models (LMs) exhibit and amplify many types of undesirable biases learned from the training data, including gender bias. However, we lack tools for effectively and efficiently changing this behavior without hurting general language modeling performance. In this paper, we study three methods for identifying causal relations between LM components and particular output: causal mediation analysis, automated circuit discovery and our novel, efficient method called DiffMask+ based on differential masking. We apply the methods to GPT-2 small and the problem of gender bias, and use the discovered sets of components to perform parameter-efficient fine-tuning for bias mitigation. Our results show significant overlap in the identified components (despite huge differences in the computational requirements of the methods) as well as success in mitigating gender bias, with less damage to general language modeling compared to full model fine-tuning. However, our work also underscores the difficulty of defining and measuring bias, and the sensitivity of causal discovery procedures to dataset choice. We hope our work can contribute to more attention for dataset development, and lead to more effective mitigation strategies for other types of bias.
ChapGTP, ILLC's Attempt at Raising a BabyLM: Improving Data Efficiency by Automatic Task Formation
Oct 17, 2023


We present the submission of the ILLC at the University of Amsterdam to the BabyLM challenge (Warstadt et al., 2023), in the strict-small track. Our final model, ChapGTP, is a masked language model that was trained for 200 epochs, aided by a novel data augmentation technique called Automatic Task Formation. We discuss in detail the performance of this model on the three evaluation suites: BLiMP, (Super)GLUE, and MSGS. Furthermore, we present a wide range of methods that were ultimately not included in the model, but may serve as inspiration for training LMs in low-resource settings.