 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Can Resolve Reference Compositionally, But It's Not Their Native Strength: The Case of the Personal Relation Task
May 29, 2026Do neural models, such as Large Language Models, genuinely acquire compositional abilities for interpretation of natural language? When we talk about semantic interpretation, we can distinguish two complementary aspects: establishing what an expression refers to in the world (which we call the Extensional task) and representing its sense in a structured way (which we call the Intensional task). We evaluate LLMs and humans on both tasks in the setting of the Personal Relation Task (Paperno 2022) in which, given a universe of people and their relationships with each other, one is asked to interpret a noun phrase such as "Amber's parent's friend". Here, for the Intensional task, the answer is the formula "friend(parent(amber))", and for the Extensional task, the person. We find that humans and LLMs show opposite strengths: humans perform better on Extensional than Intensional tasks, and LLMs vice versa. Our methodology brings greater nuance to the understanding of compositional abilities in modern machine learning models. Our results support the notion that the lack of referential grounding in LLM training is a crucial missing component in mimicking human-like language understanding.
What's the plan? Metrics for implicit planning in LLMs and their application to rhyme generation and question answering
Jan 28, 2026Prior work suggests that language models, while trained on next token prediction, show implicit planning behavior: they may select the next token in preparation to a predicted future token, such as a likely rhyming word, as supported by a prior qualitative study of Claude 3.5 Haiku using a cross-layer transcoder. We propose much simpler techniques for assessing implicit planning in language models. With case studies on rhyme poetry generation and question answering, we demonstrate that our methodology easily scales to many models. Across models, we find that the generated rhyme (e.g. "-ight") or answer to a question ("whale") can be manipulated by steering at the end of the preceding line with a vector, affecting the generation of intermediate tokens leading up to the rhyme or answer word. We show that implicit planning is a universal mechanism, present in smaller models than previously thought, starting from 1B parameters. Our methodology offers a widely applicable direct way to study implicit planning abilities of LLMs. More broadly, understanding planning abilities of language models can inform decisions in AI safety and control.
Burn After Reading: Do Multimodal Large Language Models Truly Capture Order of Events in Image Sequences?
Jun 12, 2025This paper introduces the TempVS benchmark, which focuses on temporal grounding and reasoning capabilities of Multimodal Large Language Models (MLLMs) in image sequences. TempVS consists of three main tests (i.e., event relation inference, sentence ordering and image ordering), each accompanied with a basic grounding test. TempVS requires MLLMs to rely on both visual and linguistic modalities to understand the temporal order of events. We evaluate 38 state-of-the-art MLLMs, demonstrating that models struggle to solve TempVS, with a substantial performance gap compared to human capabilities. We also provide fine-grained insights that suggest promising directions for future research. Our TempVS benchmark data and code are available at https://github.com/yjsong22/TempVS.
Context-aware Visual Storytelling with Visual Prefix Tuning and Contrastive Learning
Aug 12, 2024



Visual storytelling systems generate multi-sentence stories from image sequences. In this task, capturing contextual information and bridging visual variation bring additional challenges. We propose a simple yet effective framework that leverages the generalization capabilities of pretrained foundation models, only training a lightweight vision-language mapping network to connect modalities, while incorporating context to enhance coherence. We introduce a multimodal contrastive objective that also improves visual relevance and story informativeness. Extensive experimental results, across both automatic metrics and human evaluations, demonstrate that the stories generated by our framework are diverse, coherent, informative, and interesting.
Grounded and Well-rounded: A Methodological Approach to the Study of Cross-modal and Cross-lingual Grounding
Oct 18, 2023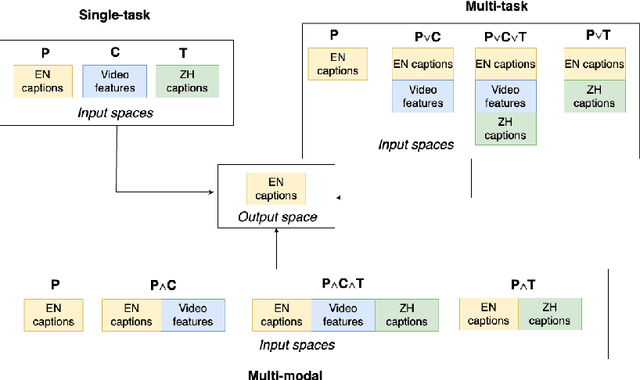
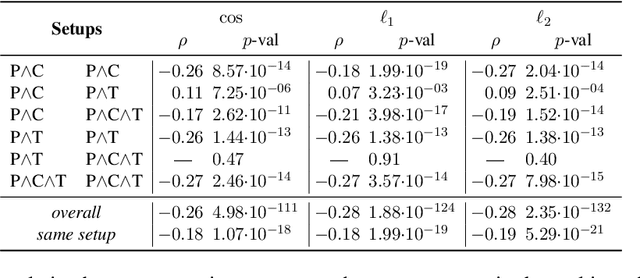
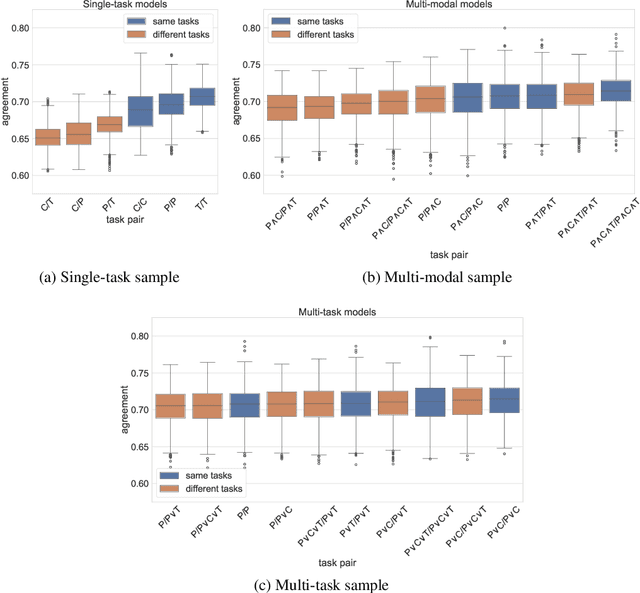
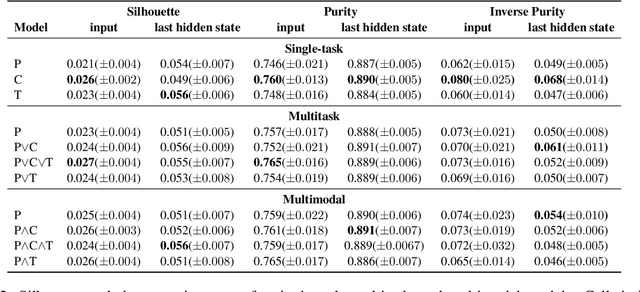
Grounding has been argued to be a crucial component towards the development of more complete and truly semantically competent artificial intelligence systems. Literature has divided into two camps: While some argue that grounding allows for qualitatively different generalizations, others believe it can be compensated by mono-modal data quantity. Limited empirical evidence has emerged for or against either position, which we argue is due to the methodological challenges that come with studying grounding and its effects on NLP systems. In this paper, we establish a methodological framework for studying what the effects are - if any - of providing models with richer input sources than text-only. The crux of it lies in the construction of comparable samples of populations of models trained on different input modalities, so that we can tease apart the qualitative effects of different input sources from quantifiable model performances. Experiments using this framework reveal qualitative differences in model behavior between cross-modally grounded, cross-lingually grounded, and ungrounded models, which we measure both at a global dataset level as well as for specific word representations, depending on how concrete their semantics is.
The Scenario Refiner: Grounding subjects in images at the morphological level
Sep 20, 2023Derivationally related words, such as "runner" and "running", exhibit semantic differences which also elicit different visual scenarios. In this paper, we ask whether Vision and Language (V\&L) models capture such distinctions at the morphological level, using a a new methodology and dataset. We compare the results from V\&L models to human judgements and find that models' predictions differ from those of human participants, in particular displaying a grammatical bias. We further investigate whether the human-model misalignment is related to model architecture. Our methodology, developed on one specific morphological contrast, can be further extended for testing models on capturing other nuanced language features.
Leverage Points in Modality Shifts: Comparing Language-only and Multimodal Word Representations
Jun 04, 2023Multimodal embeddings aim to enrich the semantic information in neural representations of language compared to text-only models. While different embeddings exhibit different applicability and performance on downstream tasks, little is known about the systematic representation differences attributed to the visual modality. Our paper compares word embeddings from three vision-and-language models (CLIP, OpenCLIP and Multilingual CLIP) and three text-only models, with static (FastText) as well as contextual representations (multilingual BERT; XLM-RoBERTa). This is the first large-scale study of the effect of visual grounding on language representations, including 46 semantic parameters. We identify meaning properties and relations that characterize words whose embeddings are most affected by the inclusion of visual modality in the training data; that is, points where visual grounding turns out most important. We find that the effect of visual modality correlates most with denotational semantic properties related to concreteness, but is also detected for several specific semantic classes, as well as for valence, a sentiment-related connotational property of linguistic expressions.
Towards leveraging latent knowledge and Dialogue context for real-world conversational question answering
Dec 17, 2022



In many real-world scenarios, the absence of external knowledge source like Wikipedia restricts question answering systems to rely on latent internal knowledge in limited dialogue data. In addition, humans often seek answers by asking several questions for more comprehensive information. As the dialog becomes more extensive, machines are challenged to refer to previous conversation rounds to answer questions. In this work, we propose to leverage latent knowledge in existing conversation logs via a neural Retrieval-Reading system, enhanced with a TFIDF-based text summarizer refining lengthy conversational history to alleviate the long context issue. Our experiments show that our Retrieval-Reading system can exploit retrieved background knowledge to generate significantly better answers. The results also indicate that our context summarizer significantly helps both the retriever and the reader by introducing more concise and less noisy contextual information.
Generating image captions with external encyclopedic knowledge
Oct 10, 2022

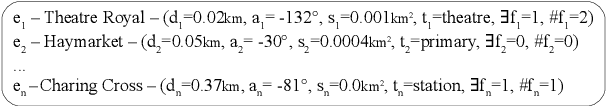

Accurately reporting what objects are depicted in an image is largely a solved problem in automatic caption generation. The next big challenge on the way to truly humanlike captioning is being able to incorporate the context of the image and related real world knowledge. We tackle this challenge by creating an end-to-end caption generation system that makes extensive use of image-specific encyclopedic data. Our approach includes a novel way of using image location to identify relevant open-domain facts in an external knowledge base, with their subsequent integration into the captioning pipeline at both the encoding and decoding stages. Our system is trained and tested on a new dataset with naturally produced knowledge-rich captions, and achieves significant improvements over multiple baselines. We empirically demonstrate that our approach is effective for generating contextualized captions with encyclopedic knowledge that is both factually accurate and relevant to the image.
How to Dissect a Muppet: The Structure of Transformer Embedding Spaces
Jun 07, 2022
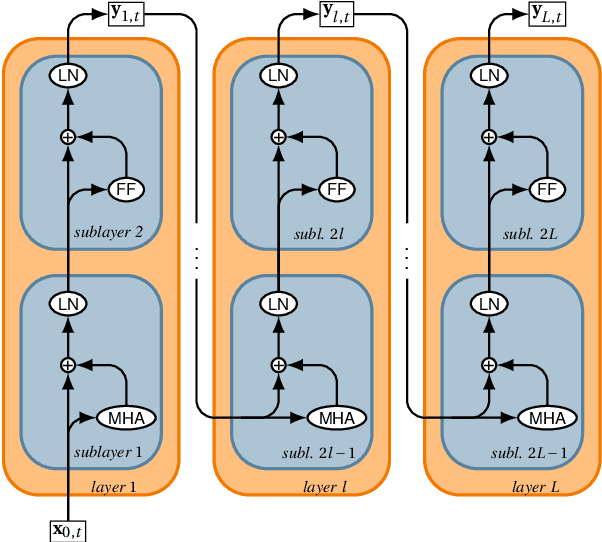
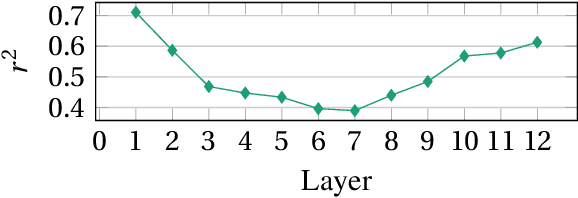
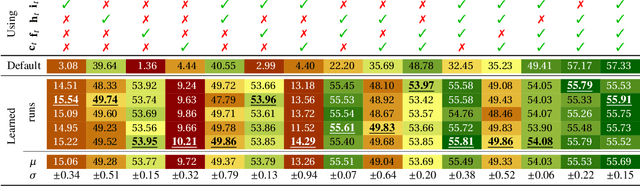
Pretrained embeddings based on the Transformer architecture have taken the NLP community by storm. We show that they can mathematically be reframed as a sum of vector factors and showcase how to use this reframing to study the impact of each component. We provide evidence that multi-head attentions and feed-forwards are not equally useful in all downstream applications, as well as a quantitative overview of the effects of finetuning on the overall embedding space. This approach allows us to draw connections to a wide range of previous studies, from vector space anisotropy to attention weights.