 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImmunoFOMO: Are Language Models missing what oncologists see?
Jun 13, 2025Language models (LMs) capabilities have grown with a fast pace over the past decade leading researchers in various disciplines, such as biomedical research, to increasingly explore the utility of LMs in their day-to-day applications. Domain specific language models have already been in use for biomedical natural language processing (NLP) applications. Recently however, the interest has grown towards medical language models and their understanding capabilities. In this paper, we investigate the medical conceptual grounding of various language models against expert clinicians for identification of hallmarks of immunotherapy in breast cancer abstracts. Our results show that pre-trained language models have potential to outperform large language models in identifying very specific (low-level) concepts.
Retrieve, Generate, Evaluate: A Case Study for Medical Paraphrases Generation with Small Language Models
Jul 23, 2024Recent surge in the accessibility of large language models (LLMs) to the general population can lead to untrackable use of such models for medical-related recommendations. Language generation via LLMs models has two key problems: firstly, they are prone to hallucination and therefore, for any medical purpose they require scientific and factual grounding; secondly, LLMs pose tremendous challenge to computational resources due to their gigantic model size. In this work, we introduce pRAGe, a pipeline for Retrieval Augmented Generation and evaluation of medical paraphrases generation using Small Language Models (SLM). We study the effectiveness of SLMs and the impact of external knowledge base for medical paraphrase generation in French.
Domain-specific or Uncertainty-aware models: Does it really make a difference for biomedical text classification?
Jul 17, 2024

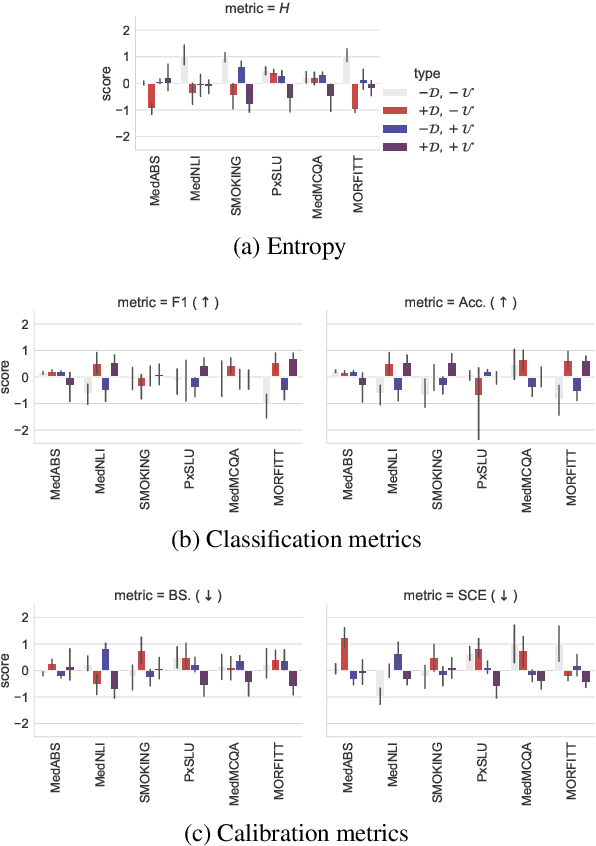
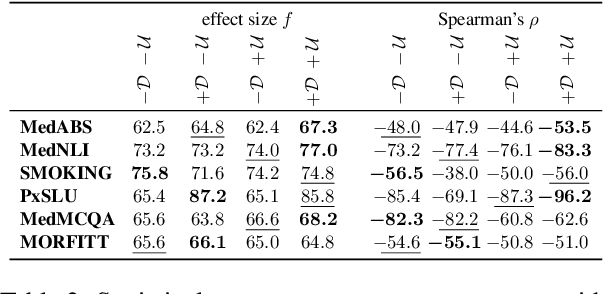
The success of pretrained language models (PLMs) across a spate of use-cases has led to significant investment from the NLP community towards building domain-specific foundational models. On the other hand, in mission critical settings such as biomedical applications, other aspects also factor in-chief of which is a model's ability to produce reasonable estimates of its own uncertainty. In the present study, we discuss these two desiderata through the lens of how they shape the entropy of a model's output probability distribution. We find that domain specificity and uncertainty awareness can often be successfully combined, but the exact task at hand weighs in much more strongly.
Modelling Irregularly Sampled Time Series Without Imputation
Sep 15, 2023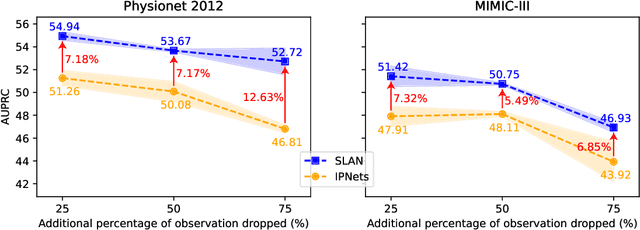
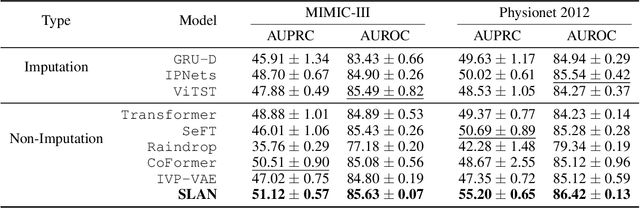
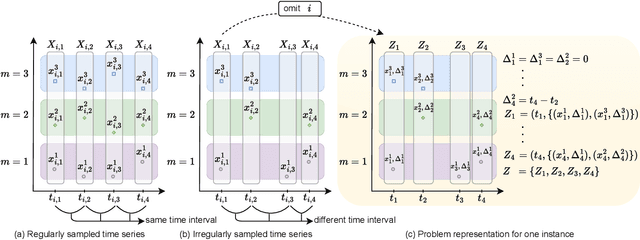
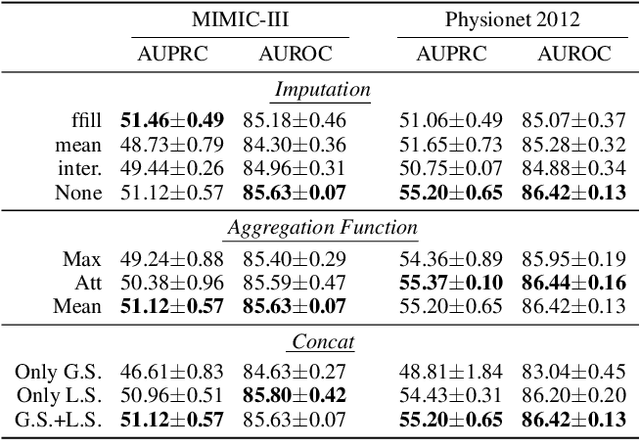
Modelling irregularly-sampled time series (ISTS) is challenging because of missing values. Most existing methods focus on handling ISTS by converting irregularly sampled data into regularly sampled data via imputation. These models assume an underlying missing mechanism leading to unwanted bias and sub-optimal performance. We present SLAN (Switch LSTM Aggregate Network), which utilizes a pack of LSTMs to model ISTS without imputation, eliminating the assumption of any underlying process. It dynamically adapts its architecture on the fly based on the measured sensors. SLAN exploits the irregularity information to capture each sensor's local summary explicitly and maintains a global summary state throughout the observational period. We demonstrate the efficacy of SLAN on publicly available datasets, namely, MIMIC-III, Physionet 2012 and Physionet 2019. The code is available at https://github.com/Rohit102497/SLAN.
How to Dissect a Muppet: The Structure of Transformer Embedding Spaces
Jun 07, 2022
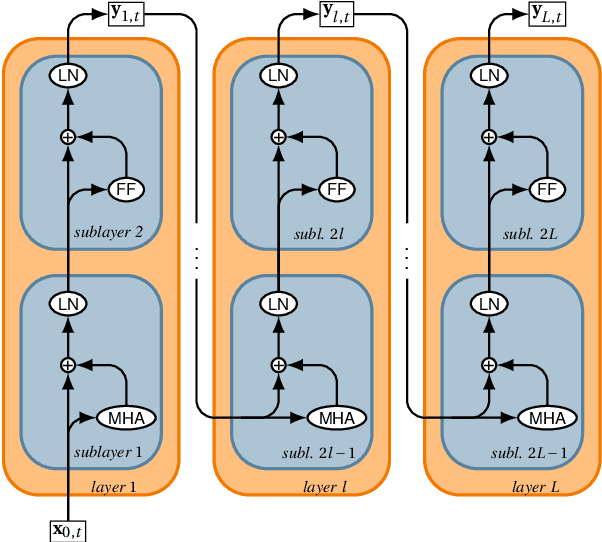
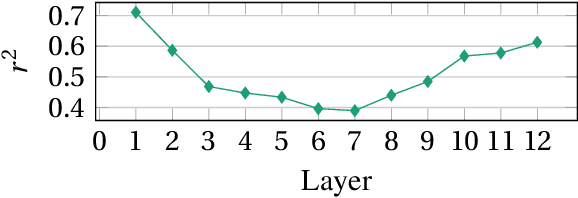
Pretrained embeddings based on the Transformer architecture have taken the NLP community by storm. We show that they can mathematically be reframed as a sum of vector factors and showcase how to use this reframing to study the impact of each component. We provide evidence that multi-head attentions and feed-forwards are not equally useful in all downstream applications, as well as a quantitative overview of the effects of finetuning on the overall embedding space. This approach allows us to draw connections to a wide range of previous studies, from vector space anisotropy to attention weights.
Semeval-2022 Task 1: CODWOE -- Comparing Dictionaries and Word Embeddings
May 27, 2022

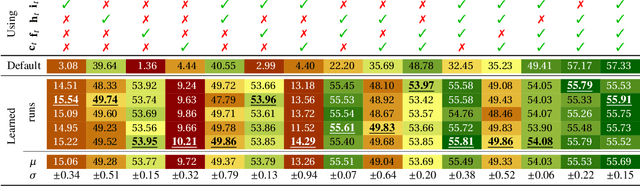
Word embeddings have advanced the state of the art in NLP across numerous tasks. Understanding the contents of dense neural representations is of utmost interest to the computational semantics community. We propose to focus on relating these opaque word vectors with human-readable definitions, as found in dictionaries. This problem naturally divides into two subtasks: converting definitions into embeddings, and converting embeddings into definitions. This task was conducted in a multilingual setting, using comparable sets of embeddings trained homogeneously.
A Game Interface to Study Semantic Grounding in Text-Based Models
Aug 17, 2021
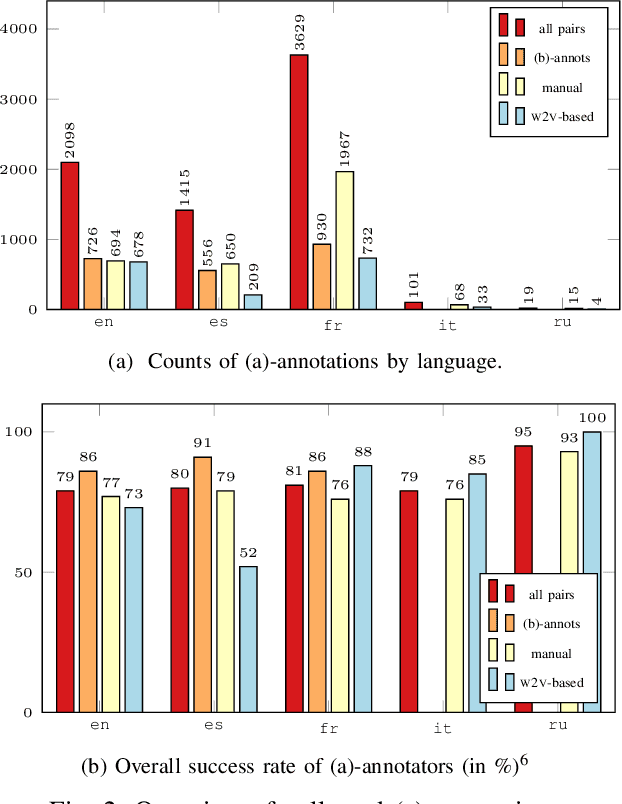
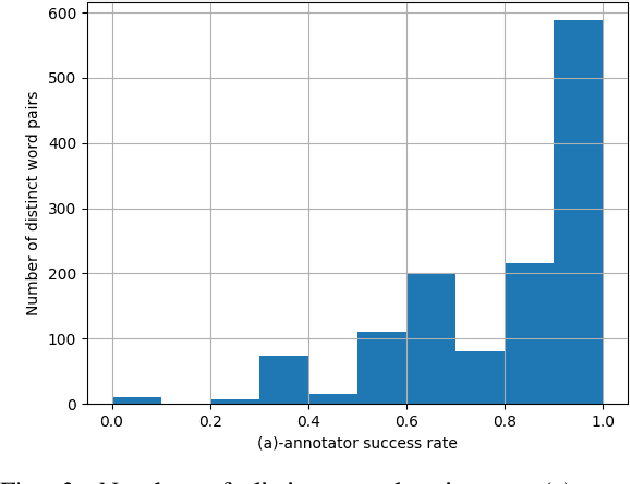
Can language models learn grounded representations from text distribution alone? This question is both central and recurrent in natural language processing; authors generally agree that grounding requires more than textual distribution. We propose to experimentally test this claim: if any two words have different meanings and yet cannot be distinguished from distribution alone, then grounding is out of the reach of text-based models. To that end, we present early work on an online game for the collection of human judgments on the distributional similarity of word pairs in five languages. We further report early results of our data collection campaign.
What do you mean, BERT? Assessing BERT as a Distributional Semantics Model
Nov 13, 2019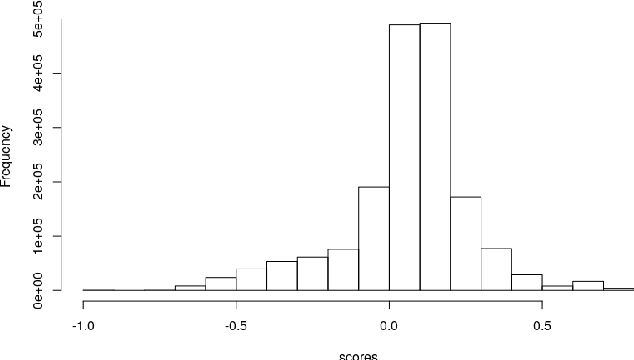
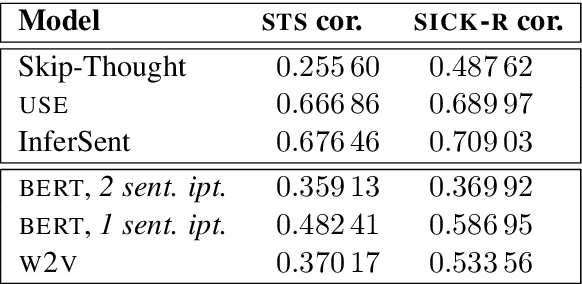
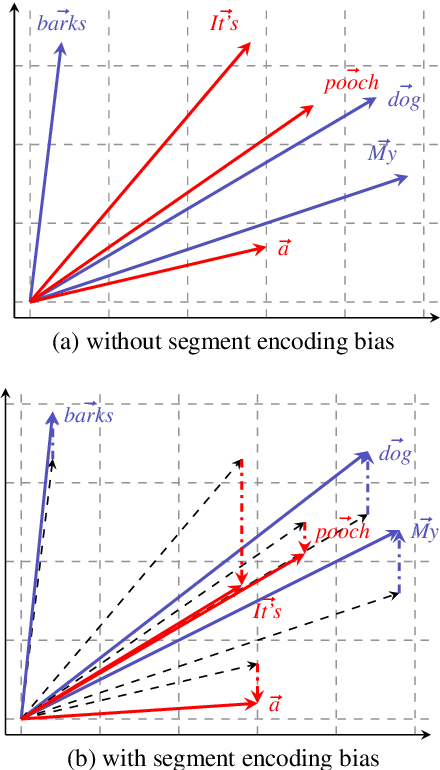
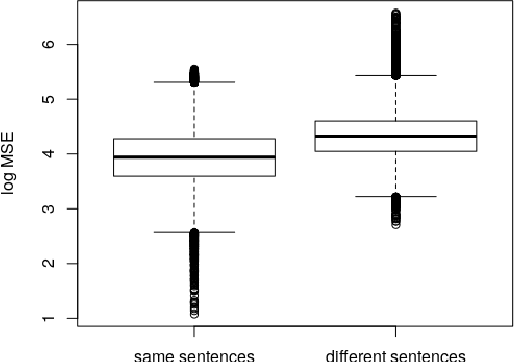
Contextualized word embeddings, i.e. vector representations for words in context, are naturally seen as an extension of previous noncontextual distributional semantic models. In this work, we focus on BERT, a deep neural network that produces contextualized embeddings and has set the state-of-the-art in several semantic tasks, and study the semantic coherence of its embedding space. While showing a tendency towards coherence, BERT does not fully live up to the natural expectations for a semantic vector space. In particular, we find that the position of the sentence in which a word occurs, while having no meaning correlates, leaves a noticeable trace on the word embeddings and disturbs similarity relationships.
Mark my Word: A Sequence-to-Sequence Approach to Definition Modeling
Nov 13, 2019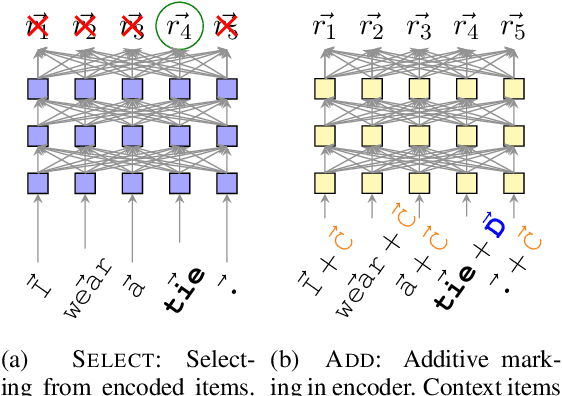
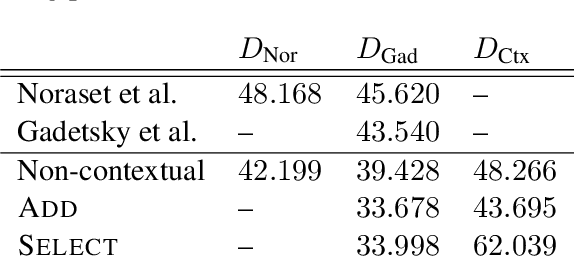


Defining words in a textual context is a useful task both for practical purposes and for gaining insight into distributed word representations. Building on the distributional hypothesis, we argue here that the most natural formalization of definition modeling is to treat it as a sequence-to-sequence task, rather than a word-to-sequence task: given an input sequence with a highlighted word, generate a contextually appropriate definition for it. We implement this approach in a Transformer-based sequence-to-sequence model. Our proposal allows to train contextualization and definition generation in an end-to-end fashion, which is a conceptual improvement over earlier works. We achieve state-of-the-art results both in contextual and non-contextual definition modeling.