 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepacketLSTM: Dynamic LSTM Framework for Streaming Data with Varying Feature Space
Oct 22, 2024



We study the online learning problem characterized by the varying input feature space of streaming data. Although LSTMs have been employed to effectively capture the temporal nature of streaming data, they cannot handle the dimension-varying streams in an online learning setting. Therefore, we propose a dynamic LSTM-based novel method, called packetLSTM, to model the dimension-varying streams. The packetLSTM's dynamic framework consists of an evolving packet of LSTMs, each dedicated to processing one input feature. Each LSTM retains the local information of its corresponding feature, while a shared common memory consolidates global information. This configuration facilitates continuous learning and mitigates the issue of forgetting, even when certain features are absent for extended time periods. The idea of utilizing one LSTM per feature coupled with a dimension-invariant operator for information aggregation enhances the dynamic nature of packetLSTM. This dynamic nature is evidenced by the model's ability to activate, deactivate, and add new LSTMs as required, thus seamlessly accommodating varying input dimensions. The packetLSTM achieves state-of-the-art results on five datasets, and its underlying principle is extended to other RNN types, like GRU and vanilla RNN.
Online Learning under Haphazard Input Conditions: A Comprehensive Review and Analysis
Apr 07, 2024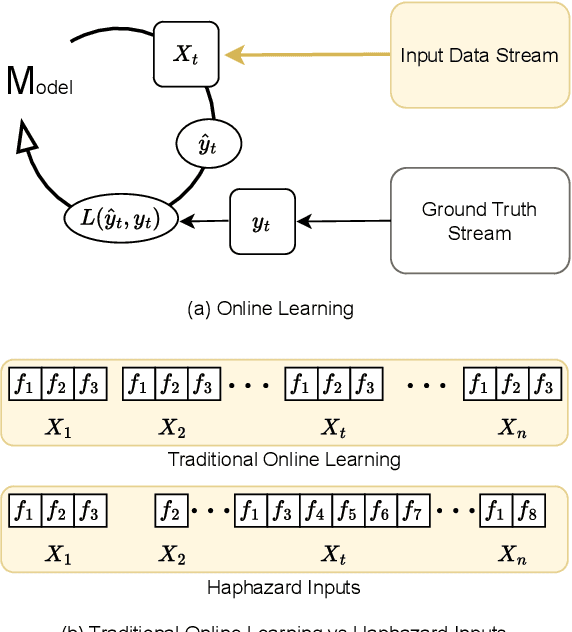
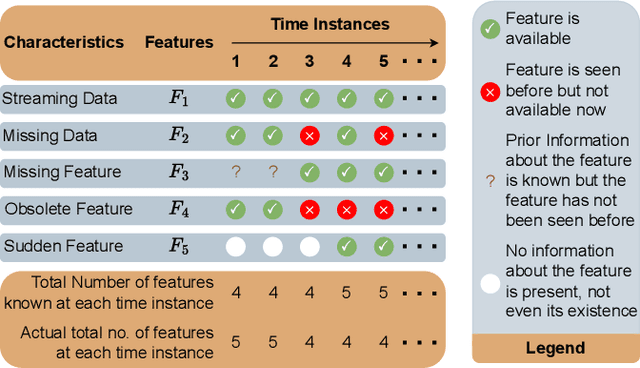
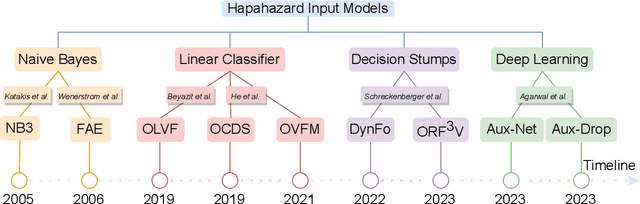
The domain of online learning has experienced multifaceted expansion owing to its prevalence in real-life applications. Nonetheless, this progression operates under the assumption that the input feature space of the streaming data remains constant. In this survey paper, we address the topic of online learning in the context of haphazard inputs, explicitly foregoing such an assumption. We discuss, classify, evaluate, and compare the methodologies that are adept at modeling haphazard inputs, additionally providing the corresponding code implementations and their carbon footprint. Moreover, we classify the datasets related to the field of haphazard inputs and introduce evaluation metrics specifically designed for datasets exhibiting imbalance. The code of each methodology can be found at https://github.com/Rohit102497/HaphazardInputsReview
Dense Video Captioning: A Survey of Techniques, Datasets and Evaluation Protocols
Nov 05, 2023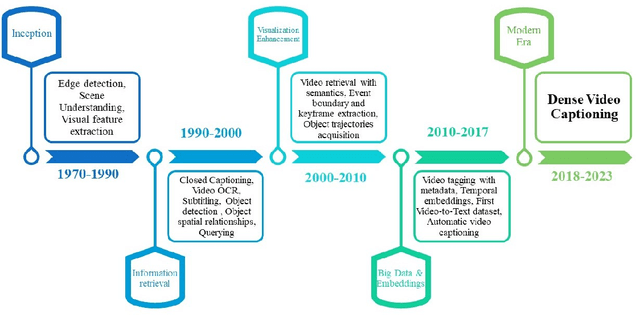
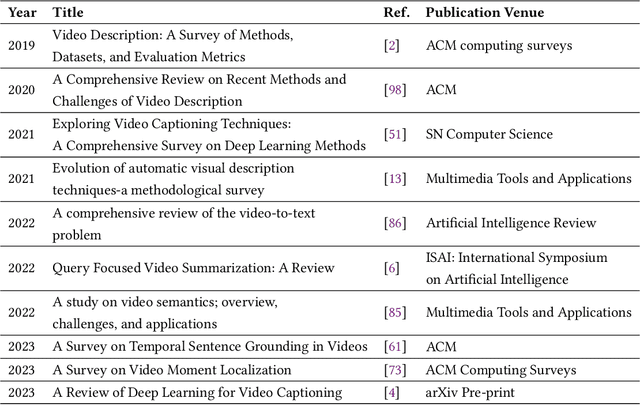
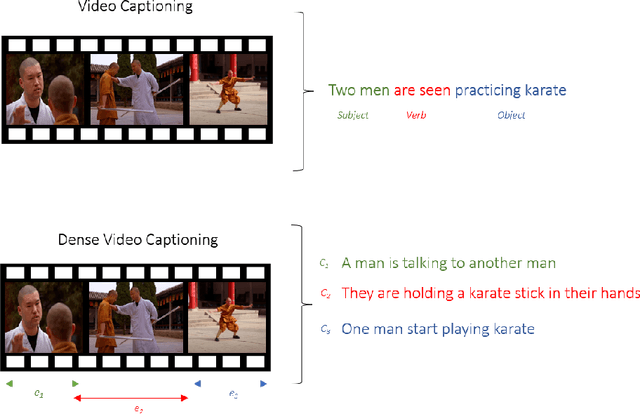

Untrimmed videos have interrelated events, dependencies, context, overlapping events, object-object interactions, domain specificity, and other semantics that are worth highlighting while describing a video in natural language. Owing to such a vast diversity, a single sentence can only correctly describe a portion of the video. Dense Video Captioning (DVC) aims at detecting and describing different events in a given video. The term DVC originated in the 2017 ActivityNet challenge, after which considerable effort has been made to address the challenge. Dense Video Captioning is divided into three sub-tasks: (1) Video Feature Extraction (VFE), (2) Temporal Event Localization (TEL), and (3) Dense Caption Generation (DCG). This review aims to discuss all the studies that claim to perform DVC along with its sub-tasks and summarize their results. We also discuss all the datasets that have been used for DVC. Lastly, we highlight some emerging challenges and future trends in the field.
Modelling Irregularly Sampled Time Series Without Imputation
Sep 15, 2023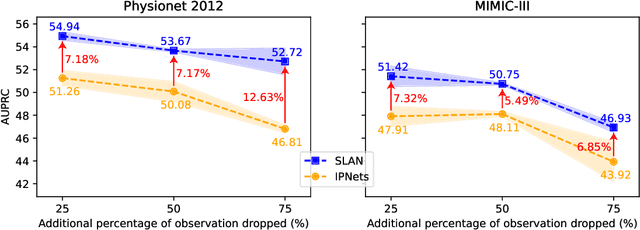
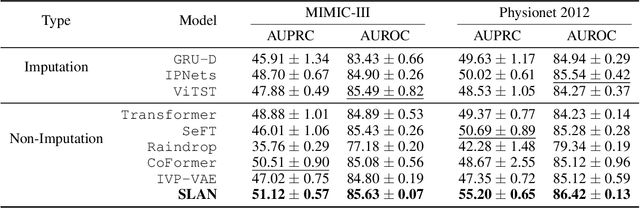
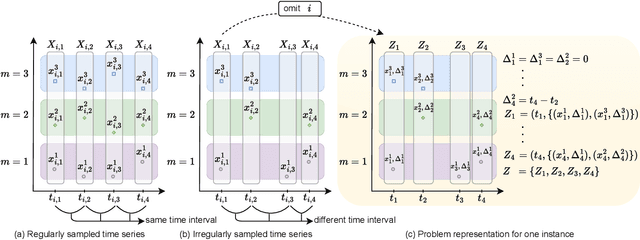
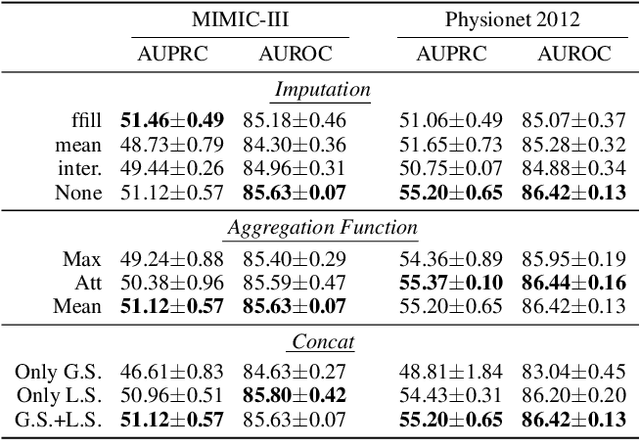
Modelling irregularly-sampled time series (ISTS) is challenging because of missing values. Most existing methods focus on handling ISTS by converting irregularly sampled data into regularly sampled data via imputation. These models assume an underlying missing mechanism leading to unwanted bias and sub-optimal performance. We present SLAN (Switch LSTM Aggregate Network), which utilizes a pack of LSTMs to model ISTS without imputation, eliminating the assumption of any underlying process. It dynamically adapts its architecture on the fly based on the measured sensors. SLAN exploits the irregularity information to capture each sensor's local summary explicitly and maintains a global summary state throughout the observational period. We demonstrate the efficacy of SLAN on publicly available datasets, namely, MIMIC-III, Physionet 2012 and Physionet 2019. The code is available at https://github.com/Rohit102497/SLAN.
Aux-Drop: Handling Haphazard Inputs in Online Learning Using Auxiliary Dropouts
Mar 09, 2023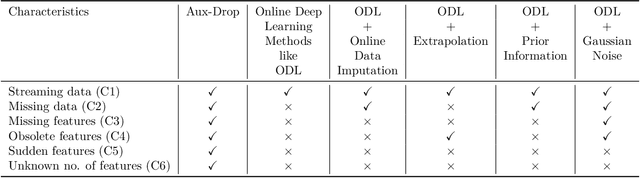
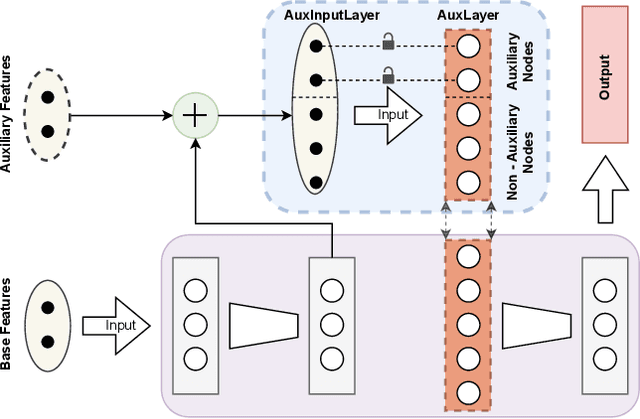
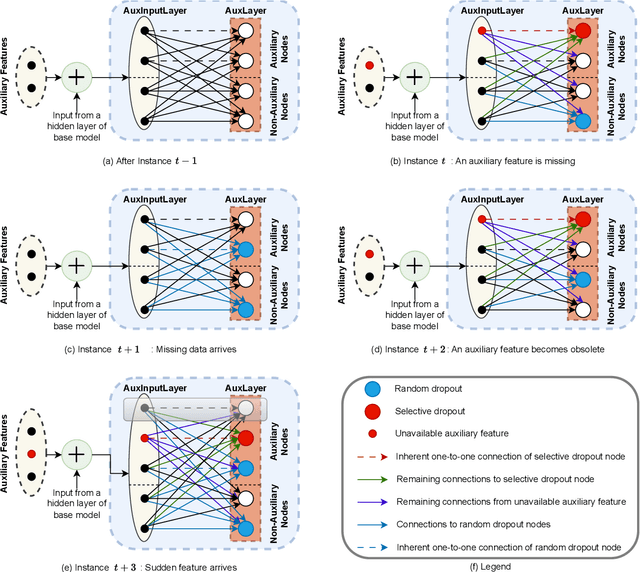

Many real-world applications based on online learning produce streaming data that is haphazard in nature, i.e., contains missing features, features becoming obsolete in time, the appearance of new features at later points in time and a lack of clarity on the total number of input features. These challenges make it hard to build a learnable system for such applications, and almost no work exists in deep learning that addresses this issue. In this paper, we present Aux-Drop, an auxiliary dropout regularization strategy for online learning that handles the haphazard input features in an effective manner. Aux-Drop adapts the conventional dropout regularization scheme for the haphazard input feature space ensuring that the final output is minimally impacted by the chaotic appearance of such features. It helps to prevent the co-adaptation of especially the auxiliary and base features, as well as reduces the strong dependence of the output on any of the auxiliary inputs of the model. This helps in better learning for scenarios where certain features disappear in time or when new features are to be modeled. The efficacy of Aux-Drop has been demonstrated through extensive numerical experiments on SOTA benchmarking datasets that include Italy Power Demand, HIGGS, SUSY and multiple UCI datasets.
MABNet: Master Assistant Buddy Network with Hybrid Learning for Image Retrieval
Mar 06, 2023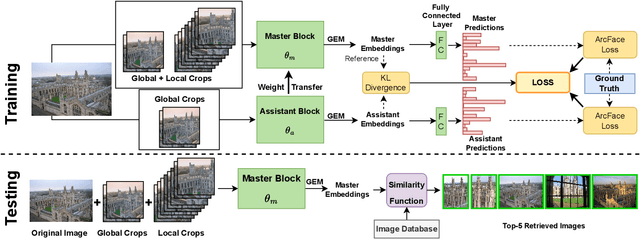


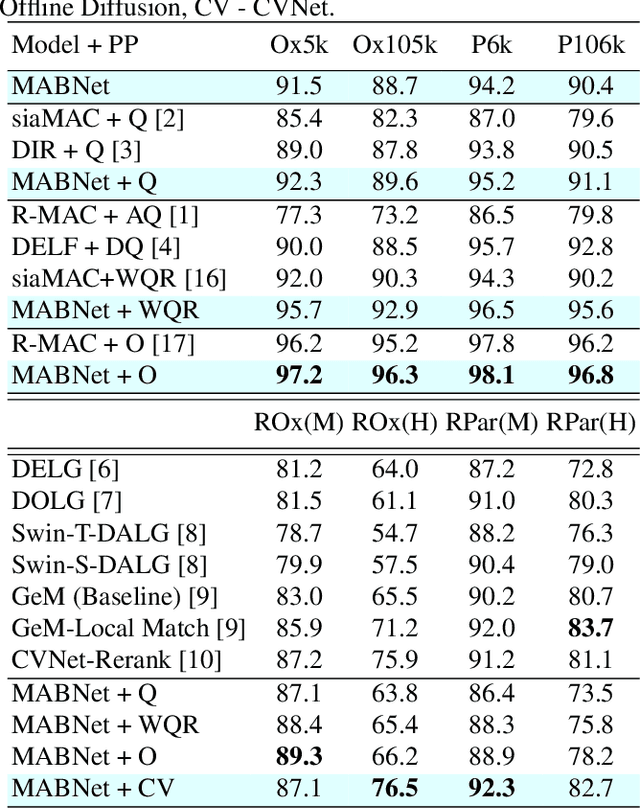
Image retrieval has garnered growing interest in recent times. The current approaches are either supervised or self-supervised. These methods do not exploit the benefits of hybrid learning using both supervision and self-supervision. We present a novel Master Assistant Buddy Network (MABNet) for image retrieval which incorporates both learning mechanisms. MABNet consists of master and assistant blocks, both learning independently through supervision and collectively via self-supervision. The master guides the assistant by providing its knowledge base as a reference for self-supervision and the assistant reports its knowledge back to the master by weight transfer. We perform extensive experiments on public datasets with and without post-processing.
MiShape: 3D Shape Modelling of Mitochondria in Microscopy
Mar 02, 2023



Fluorescence microscopy is a quintessential tool for observing cells and understanding the underlying mechanisms of life-sustaining processes of all living organisms. The problem of extracting 3D shape of mitochondria from fluorescence microscopy images remains unsolved due to the complex and varied shapes expressed by mitochondria and the poor resolving capacity of these microscopes. We propose an approach to bridge this gap by learning a shape prior for mitochondria termed as MiShape, by leveraging high-resolution electron microscopy data. MiShape is a generative model learned using implicit representations of mitochondrial shapes. It provides a shape distribution that can be used to generate infinite realistic mitochondrial shapes. We demonstrate the representation power of MiShape and its utility for 3D shape reconstruction given a single 2D fluorescence image or a small 3D stack of 2D slices. We also showcase applications of our method by deriving simulated fluorescence microscope datasets that have realistic 3D ground truths for the problem of 2D segmentation and microscope-to-microscope transformation.