 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural GaLore: Accelerating GaLore for memory-efficient LLM Training and Fine-tuning
Oct 21, 2024



Training LLMs presents significant memory challenges due to growing size of data, weights, and optimizer states. Techniques such as data and model parallelism, gradient checkpointing, and offloading strategies address this issue but are often infeasible due to hardware constraints. To mitigate memory usage, alternative methods like Parameter-Efficient-Fine-Tuning (PEFT) and GaLore approximate weights or optimizer states. PEFT methods, such as LoRA, have gained popularity for fine-tuning LLMs, though they require a full-rank warm start. In contrast, GaLore allows full-parameter learning while being more memory-efficient. This work introduces Natural GaLore, a simple drop in replacement for AdamW, which efficiently applies the inverse Empirical Fisher Information Matrix to low-rank gradients using Woodbury's Identity. We demonstrate that incorporating second-order information speeds up optimization significantly, especially when the iteration budget is limited. Empirical pretraining on 60M, 130M, 350M, and 1.1B parameter Llama models on C4 data demonstrate significantly lower perplexity over GaLore without additional memory overhead. By fine-tuning RoBERTa on the GLUE benchmark using Natural GaLore, we demonstrate significant reduction in gap 86.05% vs 86.28% for full-finetuning. Furthermore, fine-tuning the TinyLlama 1.1B model for function calling using the TinyAgent framework shows that Natural GaLore achieving 83.09% accuracy on the TinyAgent dataset, significantly outperforms 16-bit LoRA at 80.06% and even surpasses GPT4-Turbo by 4%, all while using 30% less memory. All code to reproduce the results are available at: https://github.com/selfsupervised-ai/Natural-GaLore.git
Online Learning under Haphazard Input Conditions: A Comprehensive Review and Analysis
Apr 07, 2024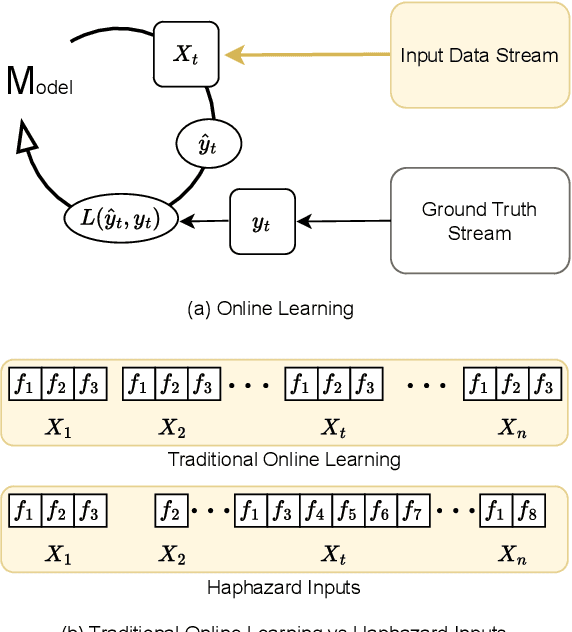
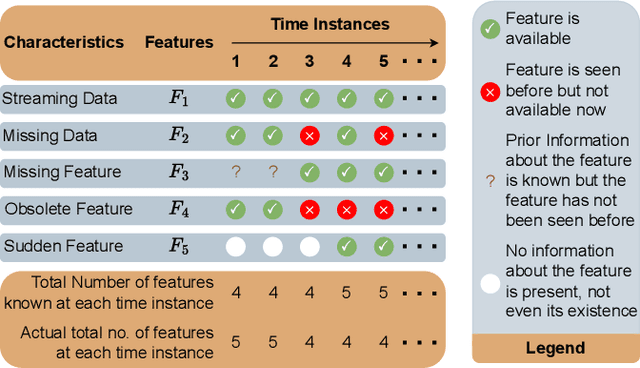
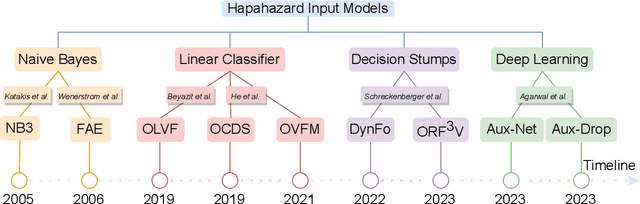
The domain of online learning has experienced multifaceted expansion owing to its prevalence in real-life applications. Nonetheless, this progression operates under the assumption that the input feature space of the streaming data remains constant. In this survey paper, we address the topic of online learning in the context of haphazard inputs, explicitly foregoing such an assumption. We discuss, classify, evaluate, and compare the methodologies that are adept at modeling haphazard inputs, additionally providing the corresponding code implementations and their carbon footprint. Moreover, we classify the datasets related to the field of haphazard inputs and introduce evaluation metrics specifically designed for datasets exhibiting imbalance. The code of each methodology can be found at https://github.com/Rohit102497/HaphazardInputsReview
Securing Social Spaces: Harnessing Deep Learning to Eradicate Cyberbullying
Apr 01, 2024



In today's digital world, cyberbullying is a serious problem that can harm the mental and physical health of people who use social media. This paper explains just how serious cyberbullying is and how it really affects indi-viduals exposed to it. It also stresses how important it is to find better ways to detect cyberbullying so that online spaces can be safer. Plus, it talks about how making more accurate tools to spot cyberbullying will be really helpful in the future. Our paper introduces a deep learning-based ap-proach, primarily employing BERT and BiLSTM architectures, to effective-ly address cyberbullying. This approach is designed to analyse large vol-umes of posts and predict potential instances of cyberbullying in online spaces. Our results demonstrate the superiority of the hateBERT model, an extension of BERT focused on hate speech detection, among the five mod-els, achieving an accuracy rate of 89.16%. This research is a significant con-tribution to "Computational Intelligence for Social Transformation," prom-ising a safer and more inclusive digital landscape.
Analysis and Detection of Multilingual Hate Speech Using Transformer Based Deep Learning
Jan 19, 2024Hate speech is harmful content that directly attacks or promotes hatred against members of groups or individuals based on actual or perceived aspects of identity, such as racism, religion, or sexual orientation. This can affect social life on social media platforms as hateful content shared through social media can harm both individuals and communities. As the prevalence of hate speech increases online, the demand for automated detection as an NLP task is increasing. In this work, the proposed method is using transformer-based model to detect hate speech in social media, like twitter, Facebook, WhatsApp, Instagram, etc. The proposed model is independent of languages and has been tested on Italian, English, German, Bengali. The Gold standard datasets were collected from renowned researcher Zeerak Talat, Sara Tonelli, Melanie Siegel, and Rezaul Karim. The success rate of the proposed model for hate speech detection is higher than the existing baseline and state-of-the-art models with accuracy in Bengali dataset is 89%, in English: 91%, in German dataset 91% and in Italian dataset it is 77%. The proposed algorithm shows substantial improvement to the benchmark method.
Improvement of electronic Governance and mobile Governance in Multilingual Countries with Digital Etymology using Sanskrit Grammar
Mar 31, 2020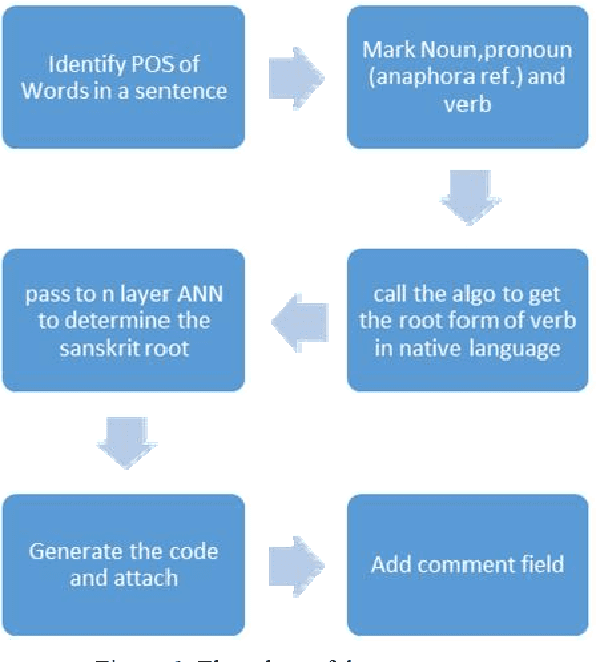

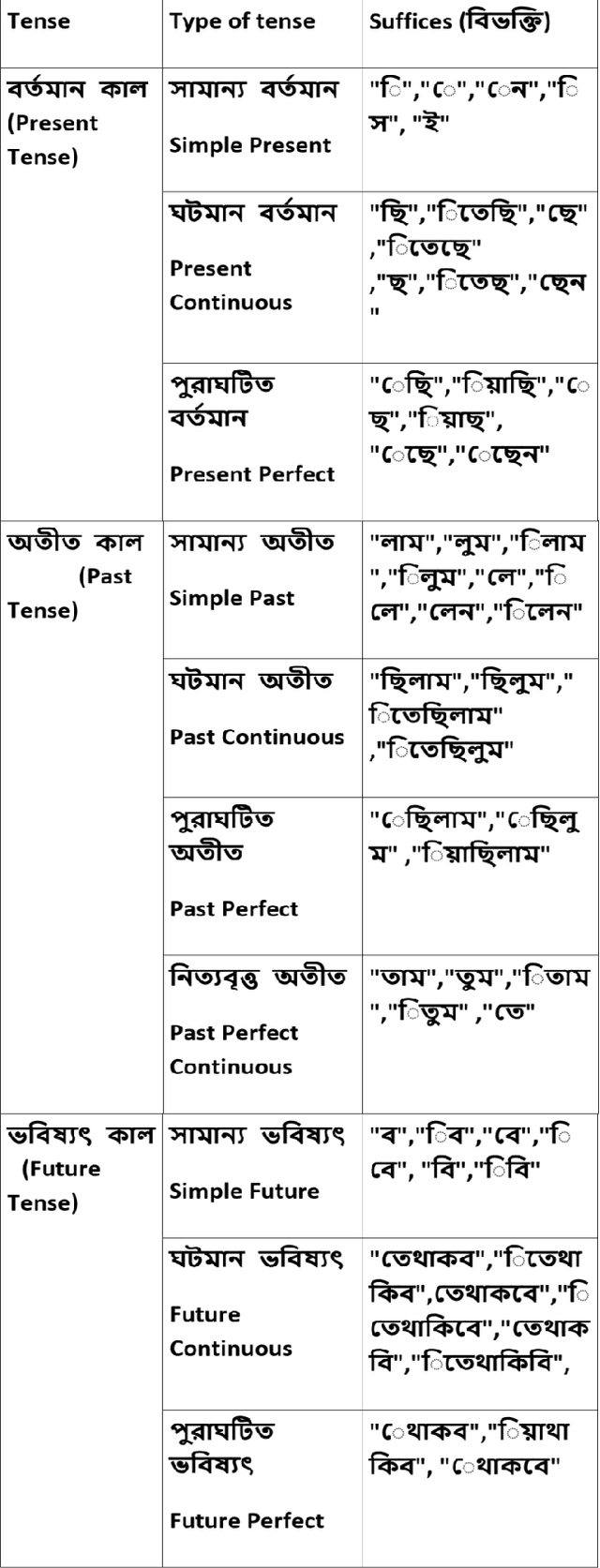
With huge improvement of digital connectivity (Wifi,3G,4G) and digital devices access to internet has reached in the remotest corners now a days. Rural people can easily access web or apps from PDAs, laptops, smartphones etc. This is an opportunity of the Government to reach to the citizen in large number, get their feedback, associate them in policy decision with e governance without deploying huge man, material or resourses. But the Government of multilingual countries face a lot of problem in successful implementation of Government to Citizen (G2C) and Citizen to Government (C2G) governance as the rural people tend and prefer to interact in their native languages. Presenting equal experience over web or app to different language group of speakers is a real challenge. In this research we have sorted out the problems faced by Indo Aryan speaking netizens which is in general also applicable to any language family groups or subgroups. Then we have tried to give probable solutions using Etymology. Etymology is used to correlate the words using their ROOT forms. In 5th century BC Panini wrote Astadhyayi where he depicted sutras or rules -- how a word is changed according to person,tense,gender,number etc. Later this book was followed in Western countries also to derive their grammar of comparatively new languages. We have trained our system for automatic root extraction from the surface level or morphed form of words using Panian Gramatical rules. We have tested our system over 10000 bengali Verbs and extracted the root form with 98% accuracy. We are now working to extend the program to successfully lemmatize any words of any language and correlate them by applying those rule sets in Artificial Neural Network.
Automatic Extraction of Bengali Root Verbs using Paninian Grammar
Mar 31, 2020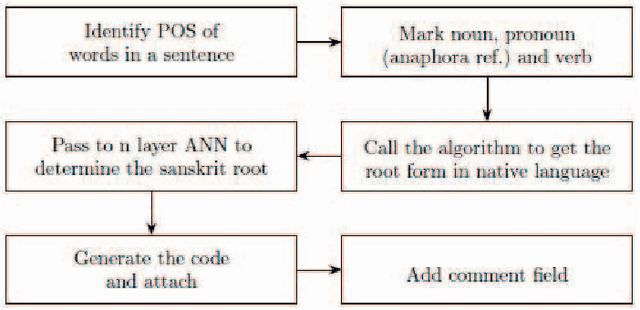

In this research work, we have proposed an algorithm based on supervised learning methodology to extract the root forms of the Bengali verbs using the grammatical rules proposed by Panini [1] in Ashtadhyayi. This methodology can be applied for the languages which are derived from Sanskrit. The proposed system has been developed based on tense, person and morphological inflections of the verbs to find their root forms. The work has been executed in two phases: first, the surface level forms or inflected forms of the verbs have been classified into a certain number of groups of similar tense and person. For this task, a standard pattern, available in Bengali language has been used. Next, a set of rules have been applied to extract the root form from the surface level forms of a verb. The system has been tested on 10000 verbs collected from the Bengali text corpus developed in the TDIL project of the Govt. of India. The accuracy of the output has been achieved 98% which is verified by a linguistic expert. Root verb identification is a key step in semantic searching, multi-sentence search query processing, understanding the meaning of a language, disambiguation of word sense, classification of the sentences etc.
A Novel Approach to Enhance the Performance of Semantic Search in Bengali using Neural Net and other Classification Techniques
Nov 04, 2019
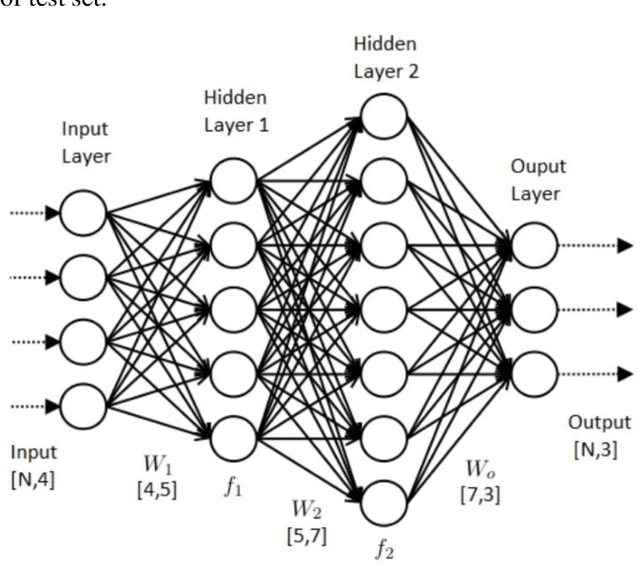

Search has for a long time been an important tool for users to retrieve information. Syntactic search is matching documents or objects containing specific keywords like user-history, location, preference etc. to improve the results. However, it is often possible that the query and the best answer have no term or very less number of terms in common and syntactic search can not perform properly in such cases. Semantic search, on the other hand, resolves these issues but suffers from lack of annotation, absence of WordNet in case of low resource languages. In this work, we have demonstrated an end to end procedure to improve the performance of semantic search using semi-supervised and unsupervised learning algorithms. An available Bengali repository was chosen to have seven types of semantic properties primarily to develop the system. Performance has been tested using Support Vector Machine, Naive Bayes, Decision Tree and Artificial Neural Network (ANN). Our system has achieved the efficiency to predict the correct semantics using knowledge base over the time of learning. A repository containing around a million sentences, a product of TDIL project of Govt. of India, was used to test our system at first instance. Then the testing has been done for other languages. Being a cognitive system it may be very useful for improving user satisfaction in e-Governance or m-Governance in the multilingual environment and also for other applications.
A Variational Bayes Approach to Decoding in a Phase-Uncertain Digital Receiver
Jul 04, 2011
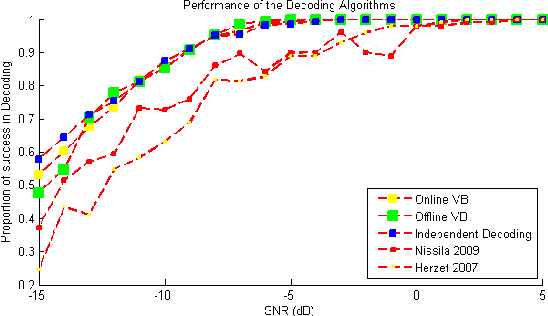
This paper presents a Bayesian approach to symbol and phase inference in a phase-unsynchronized digital receiver. It primarily extends [Quinn 2011] to the multi-symbol case, using the variational Bayes (VB) approximation to deal with the combinatorial complexity of the phase inference in this case. The work provides a fully Bayesian extension of the EM-based framework underlying current turbo-synchronization methods, since it induces a von Mises prior on the time-invariant phase parmeter. As a result, we achieve tractable iterative algorithms with improved robustness in low SNR regimes, compared to the current EM-based approaches. As a corollary to our analysis we also discover the importance of prior regularization in elegantly tackling the significant problem of phase ambiguity.