 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Extraction of Bengali Root Verbs using Paninian Grammar
Paper and Code
Mar 31, 2020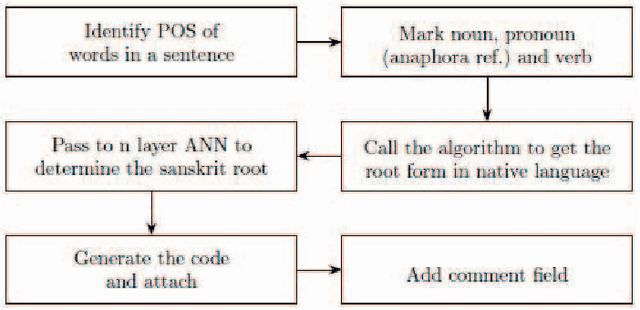
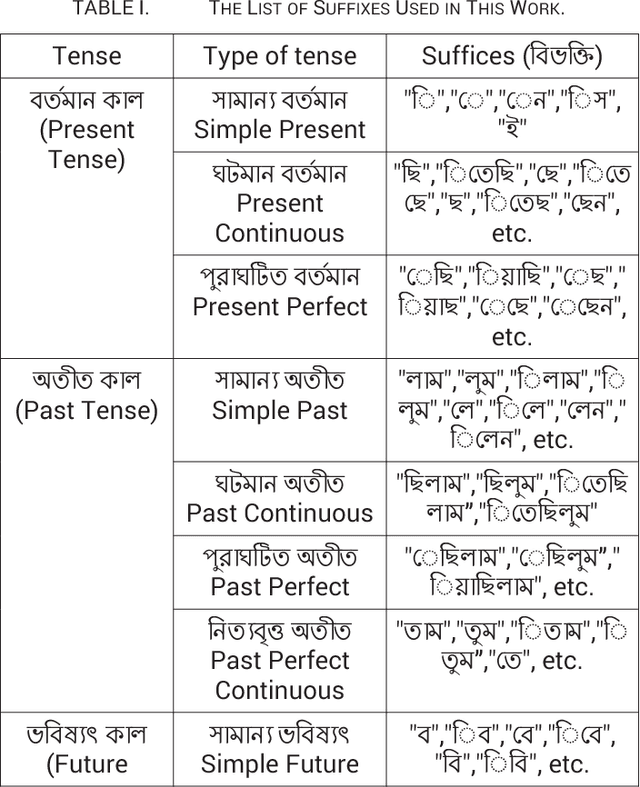

In this research work, we have proposed an algorithm based on supervised learning methodology to extract the root forms of the Bengali verbs using the grammatical rules proposed by Panini [1] in Ashtadhyayi. This methodology can be applied for the languages which are derived from Sanskrit. The proposed system has been developed based on tense, person and morphological inflections of the verbs to find their root forms. The work has been executed in two phases: first, the surface level forms or inflected forms of the verbs have been classified into a certain number of groups of similar tense and person. For this task, a standard pattern, available in Bengali language has been used. Next, a set of rules have been applied to extract the root form from the surface level forms of a verb. The system has been tested on 10000 verbs collected from the Bengali text corpus developed in the TDIL project of the Govt. of India. The accuracy of the output has been achieved 98% which is verified by a linguistic expert. Root verb identification is a key step in semantic searching, multi-sentence search query processing, understanding the meaning of a language, disambiguation of word sense, classification of the sentences etc.