 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Representation Bias in Fairness-Aware data Repair using Optimal Transport
Oct 03, 2024



Optimal transport (OT) has an important role in transforming data distributions in a manner which engenders fairness. Typically, the OT operators are learnt from the unfair attribute-labelled data, and then used for their repair. Two significant limitations of this approach are as follows: (i) the OT operators for underrepresented subgroups are poorly learnt (i.e. they are susceptible to representation bias); and (ii) these OT repairs cannot be effected on identically distributed but out-of-sample (i.e.\ archival) data. In this paper, we address both of these problems by adopting a Bayesian nonparametric stopping rule for learning each attribute-labelled component of the data distribution. The induced OT-optimal quantization operators can then be used to repair the archival data. We formulate a novel definition of the fair distributional target, along with quantifiers that allow us to trade fairness against damage in the transformed data. These are used to reveal excellent performance of our representation-bias-tolerant scheme in simulated and benchmark data sets.
Dataset Distillation from First Principles: Integrating Core Information Extraction and Purposeful Learning
Sep 02, 2024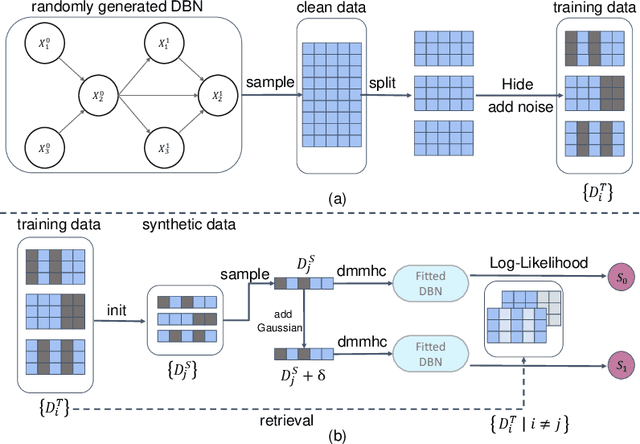
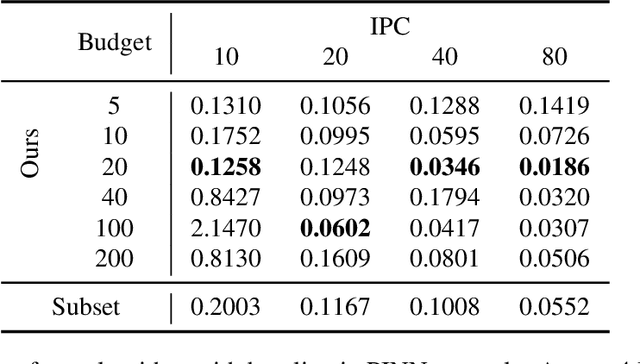
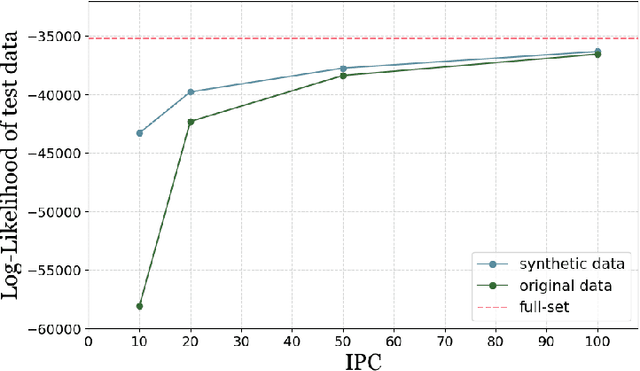
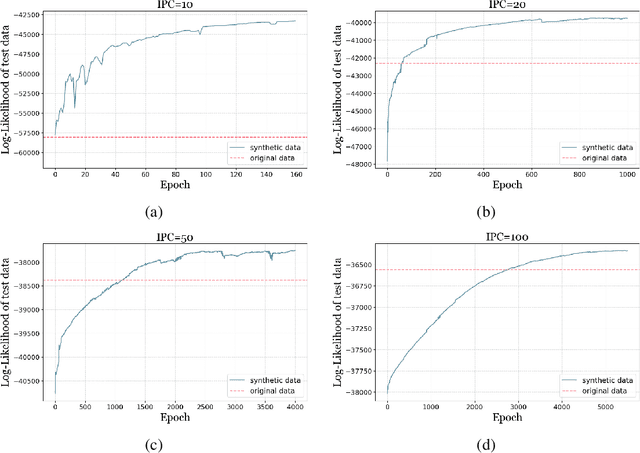
Dataset distillation (DD) is an increasingly important technique that focuses on constructing a synthetic dataset capable of capturing the core information in training data to achieve comparable performance in models trained on the latter. While DD has a wide range of applications, the theory supporting it is less well evolved. New methods of DD are compared on a common set of benchmarks, rather than oriented towards any particular learning task. In this work, we present a formal model of DD, arguing that a precise characterization of the underlying optimization problem must specify the inference task associated with the application of interest. Without this task-specific focus, the DD problem is under-specified, and the selection of a DD algorithm for a particular task is merely heuristic. Our formalization reveals novel applications of DD across different modeling environments. We analyze existing DD methods through this broader lens, highlighting their strengths and limitations in terms of accuracy and faithfulness to optimal DD operation. Finally, we present numerical results for two case studies important in contemporary settings. Firstly, we address a critical challenge in medical data analysis: merging the knowledge from different datasets composed of intersecting, but not identical, sets of features, in order to construct a larger dataset in what is usually a small sample setting. Secondly, we consider out-of-distribution error across boundary conditions for physics-informed neural networks (PINNs), showing the potential for DD to provide more physically faithful data. By establishing this general formulation of DD, we aim to establish a new research paradigm by which DD can be understood and from which new DD techniques can arise.
Randomized Transport Plans via Hierarchical Fully Probabilistic Design
Aug 04, 2024An optimal randomized strategy for design of balanced, normalized mass transport plans is developed. It replaces -- but specializes to -- the deterministic, regularized optimal transport (OT) strategy, which yields only a certainty-equivalent plan. The incompletely specified -- and therefore uncertain -- transport plan is acknowledged to be a random process. Therefore, hierarchical fully probabilistic design (HFPD) is adopted, yielding an optimal hyperprior supported on the set of possible transport plans, and consistent with prior mean constraints on the marginals of the uncertain plan. This Bayesian resetting of the design problem for transport plans -- which we call HFPD-OT -- confers new opportunities. These include (i) a strategy for the generation of a random sample of joint transport plans; (ii) randomized marginal contracts for individual source-target pairs; and (iii) consistent measures of uncertainty in the plan and its contracts. An application in algorithmic fairness is outlined, where HFPD-OT enables the recruitment of a more diverse subset of contracts -- than is possible in classical OT -- into the delivery of an expected plan. Also, it permits fairness proxies to be endowed with uncertainty quantifiers.
Optimal Transport for Fairness: Archival Data Repair using Small Research Data Sets
Mar 20, 2024With the advent of the AI Act and other regulations, there is now an urgent need for algorithms that repair unfairness in training data. In this paper, we define fairness in terms of conditional independence between protected attributes ($S$) and features ($X$), given unprotected attributes ($U$). We address the important setting in which torrents of archival data need to be repaired, using only a small proportion of these data, which are $S|U$-labelled (the research data). We use the latter to design optimal transport (OT)-based repair plans on interpolated supports. This allows {\em off-sample}, labelled, archival data to be repaired, subject to stationarity assumptions. It also significantly reduces the size of the supports of the OT plans, with correspondingly large savings in the cost of their design and of their {\em sequential\/} application to the off-sample data. We provide detailed experimental results with simulated and benchmark real data (the Adult data set). Our performance figures demonstrate effective repair -- in the sense of quenching conditional dependence -- of large quantities of off-sample, labelled (archival) data.
Fully Probabilistic Design for Optimal Transport
Dec 19, 2022The goal of this paper is to introduce a new theoretical framework for Optimal Transport (OT), using the terminology and techniques of Fully Probabilistic Design (FPD). Optimal Transport is the canonical method for comparing probability measures and has been successfully applied in a wide range of areas (computer vision Rubner et al. [2004], computer graphics Solomon et al. [2015], natural language processing Kusner et al. [2015], etc.). However, we argue that the current OT framework suffers from two shortcomings: first, it is hard to induce generic constraints and probabilistic knowledge in the OT problem; second, the current formalism does not address the question of uncertainty in the marginals, lacking therefore the mechanisms to design robust solutions. By viewing the OT problem as the optimal design of a probability density function with marginal constraints, we prove that OT is an instance of the more generic FPD framework. In this new setting, we can furnish the OT framework with the necessary mechanisms for processing probabilistic constraints and deriving uncertainty quantifiers, hence establishing a new extended framework, called FPD-OT. Our main contribution in this paper is to establish the connection between OT and FPD, providing new theoretical insights for both. This will lay the foundations for the application of FPD-OT in a subsequent work, notably in processing more sophisticated knowledge constraints, as well as in designing robust solutions in the case of uncertain marginals.
Fully probabilistic design for knowledge fusion between Bayesian filters under uniform disturbances
Sep 22, 2021


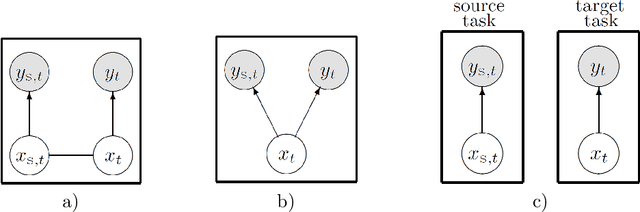
This paper considers the problem of Bayesian transfer learning-based knowledge fusion between linear state-space processes driven by uniform state and observation noise processes. The target task conditions on probabilistic state predictor(s) supplied by the source filtering task(s) to improve its own state estimate. A joint model of the target and source(s) is not required and is not elicited. The resulting decision-making problem for choosing the optimal conditional target filtering distribution under incomplete modelling is solved via fully probabilistic design (FPD), i.e. via appropriate minimization of Kullback-Leibler divergence (KLD). The resulting FPD-optimal target learner is robust, in the sense that it can reject poor-quality source knowledge. In addition, the fact that this Bayesian transfer learning (BTL) scheme does not depend on a model of interaction between the source and target tasks ensures robustness to the misspecification of such a model. The latter is a problem that affects conventional transfer learning methods. The properties of the proposed BTL scheme are demonstrated via extensive simulations, and in comparison with two contemporary alternatives.
Transferring model structure in Bayesian transfer learning for Gaussian process regression
Jan 18, 2021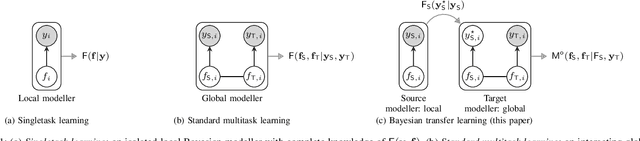



Bayesian transfer learning (BTL) is defined in this paper as the task of conditioning a target probability distribution on a transferred source distribution. The target globally models the interaction between the source and target, and conditions on a probabilistic data predictor made available by an independent local source modeller. Fully probabilistic design is adopted to solve this optimal decision-making problem in the target. By successfully transferring higher moments of the source, the target can reject unreliable source knowledge (i.e. it achieves robust transfer). This dual-modeller framework means that the source's local processing of raw data into a transferred predictive distribution -- with compressive possibilities -- is enriched by (the possible expertise of) the local source model. In addition, the introduction of the global target modeller allows correlation between the source and target tasks -- if known to the target -- to be accounted for. Important consequences emerge. Firstly, the new scheme attains the performance of fully modelled (i.e. conventional) multitask learning schemes in (those rare) cases where target model misspecification is avoided. Secondly, and more importantly, the new dual-modeller framework is robust to the model misspecification that undermines conventional multitask learning. We thoroughly explore these issues in the key context of interacting Gaussian process regression tasks. Experimental evidence from both synthetic and real data settings validates our technical findings: that the proposed BTL framework enjoys robustness in transfer while also being robust to model misspecification.
A Variational Bayes Approach to Decoding in a Phase-Uncertain Digital Receiver
Jul 04, 2011
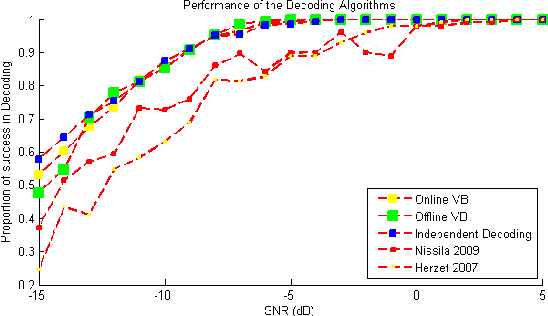
This paper presents a Bayesian approach to symbol and phase inference in a phase-unsynchronized digital receiver. It primarily extends [Quinn 2011] to the multi-symbol case, using the variational Bayes (VB) approximation to deal with the combinatorial complexity of the phase inference in this case. The work provides a fully Bayesian extension of the EM-based framework underlying current turbo-synchronization methods, since it induces a von Mises prior on the time-invariant phase parmeter. As a result, we achieve tractable iterative algorithms with improved robustness in low SNR regimes, compared to the current EM-based approaches. As a corollary to our analysis we also discover the importance of prior regularization in elegantly tackling the significant problem of phase ambiguity.