 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Sample Approximations of (Local) Moduli of Continuity
Sep 18, 2025Modulus of local continuity is used to evaluate the robustness of neural networks and fairness of their repeated uses in closed-loop models. Here, we revisit a connection between generalized derivatives and moduli of local continuity, and present a non-uniform stochastic sample approximation for moduli of local continuity. This is of importance in studying robustness of neural networks and fairness of their repeated uses.
Learning Time-Varying Convexifications of Multiple Fairness Measures
Aug 19, 2025There is an increasing appreciation that one may need to consider multiple measures of fairness, e.g., considering multiple group and individual fairness notions. The relative weights of the fairness regularisers are a priori unknown, may be time varying, and need to be learned on the fly. We consider the learning of time-varying convexifications of multiple fairness measures with limited graph-structured feedback.
Learning Network Dismantling without Handcrafted Inputs
Aug 01, 2025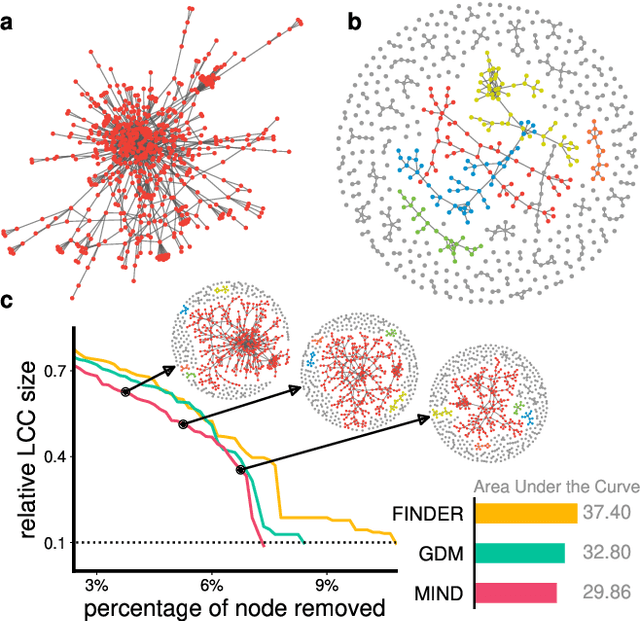

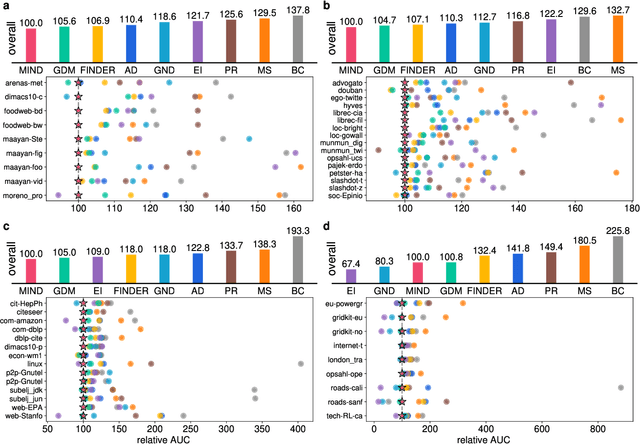
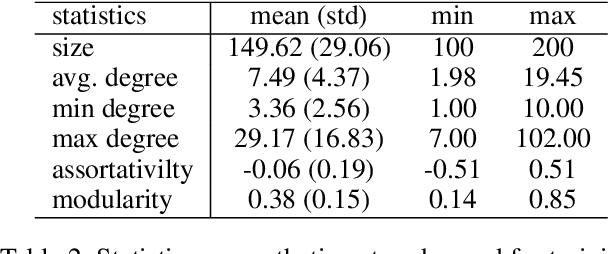
The application of message-passing Graph Neural Networks has been a breakthrough for important network science problems. However, the competitive performance often relies on using handcrafted structural features as inputs, which increases computational cost and introduces bias into the otherwise purely data-driven network representations. Here, we eliminate the need for handcrafted features by introducing an attention mechanism and utilizing message-iteration profiles, in addition to an effective algorithmic approach to generate a structurally diverse training set of small synthetic networks. Thereby, we build an expressive message-passing framework and use it to efficiently solve the NP-hard problem of Network Dismantling, virtually equivalent to vital node identification, with significant real-world applications. Trained solely on diversified synthetic networks, our proposed model -- MIND: Message Iteration Network Dismantler -- generalizes to large, unseen real networks with millions of nodes, outperforming state-of-the-art network dismantling methods. Increased efficiency and generalizability of the proposed model can be leveraged beyond dismantling in a range of complex network problems.
Overcoming Representation Bias in Fairness-Aware data Repair using Optimal Transport
Oct 03, 2024



Optimal transport (OT) has an important role in transforming data distributions in a manner which engenders fairness. Typically, the OT operators are learnt from the unfair attribute-labelled data, and then used for their repair. Two significant limitations of this approach are as follows: (i) the OT operators for underrepresented subgroups are poorly learnt (i.e. they are susceptible to representation bias); and (ii) these OT repairs cannot be effected on identically distributed but out-of-sample (i.e.\ archival) data. In this paper, we address both of these problems by adopting a Bayesian nonparametric stopping rule for learning each attribute-labelled component of the data distribution. The induced OT-optimal quantization operators can then be used to repair the archival data. We formulate a novel definition of the fair distributional target, along with quantifiers that allow us to trade fairness against damage in the transformed data. These are used to reveal excellent performance of our representation-bias-tolerant scheme in simulated and benchmark data sets.
Randomized Transport Plans via Hierarchical Fully Probabilistic Design
Aug 04, 2024An optimal randomized strategy for design of balanced, normalized mass transport plans is developed. It replaces -- but specializes to -- the deterministic, regularized optimal transport (OT) strategy, which yields only a certainty-equivalent plan. The incompletely specified -- and therefore uncertain -- transport plan is acknowledged to be a random process. Therefore, hierarchical fully probabilistic design (HFPD) is adopted, yielding an optimal hyperprior supported on the set of possible transport plans, and consistent with prior mean constraints on the marginals of the uncertain plan. This Bayesian resetting of the design problem for transport plans -- which we call HFPD-OT -- confers new opportunities. These include (i) a strategy for the generation of a random sample of joint transport plans; (ii) randomized marginal contracts for individual source-target pairs; and (iii) consistent measures of uncertainty in the plan and its contracts. An application in algorithmic fairness is outlined, where HFPD-OT enables the recruitment of a more diverse subset of contracts -- than is possible in classical OT -- into the delivery of an expected plan. Also, it permits fairness proxies to be endowed with uncertainty quantifiers.
Reinforcement Learning with Adaptive Control Regularization for Safe Control of Critical Systems
Apr 23, 2024



Reinforcement Learning (RL) is a powerful method for controlling dynamic systems, but its learning mechanism can lead to unpredictable actions that undermine the safety of critical systems. Here, we propose RL with Adaptive Control Regularization (RL-ACR) that ensures RL safety by combining the RL policy with a control regularizer that hard-codes safety constraints over forecasted system behaviors. The adaptability is achieved by using a learnable "focus" weight trained to maximize the cumulative reward of the policy combination. As the RL policy improves through off-policy learning, the focus weight improves the initial sub-optimum strategy by gradually relying more on the RL policy. We demonstrate the effectiveness of RL-ACR in a critical medical control application and further investigate its performance in four classic control environments.
Optimal Transport for Fairness: Archival Data Repair using Small Research Data Sets
Mar 20, 2024With the advent of the AI Act and other regulations, there is now an urgent need for algorithms that repair unfairness in training data. In this paper, we define fairness in terms of conditional independence between protected attributes ($S$) and features ($X$), given unprotected attributes ($U$). We address the important setting in which torrents of archival data need to be repaired, using only a small proportion of these data, which are $S|U$-labelled (the research data). We use the latter to design optimal transport (OT)-based repair plans on interpolated supports. This allows {\em off-sample}, labelled, archival data to be repaired, subject to stationarity assumptions. It also significantly reduces the size of the supports of the OT plans, with correspondingly large savings in the cost of their design and of their {\em sequential\/} application to the off-sample data. We provide detailed experimental results with simulated and benchmark real data (the Adult data set). Our performance figures demonstrate effective repair -- in the sense of quenching conditional dependence -- of large quantities of off-sample, labelled (archival) data.
Fully Probabilistic Design for Optimal Transport
Dec 19, 2022The goal of this paper is to introduce a new theoretical framework for Optimal Transport (OT), using the terminology and techniques of Fully Probabilistic Design (FPD). Optimal Transport is the canonical method for comparing probability measures and has been successfully applied in a wide range of areas (computer vision Rubner et al. [2004], computer graphics Solomon et al. [2015], natural language processing Kusner et al. [2015], etc.). However, we argue that the current OT framework suffers from two shortcomings: first, it is hard to induce generic constraints and probabilistic knowledge in the OT problem; second, the current formalism does not address the question of uncertainty in the marginals, lacking therefore the mechanisms to design robust solutions. By viewing the OT problem as the optimal design of a probability density function with marginal constraints, we prove that OT is an instance of the more generic FPD framework. In this new setting, we can furnish the OT framework with the necessary mechanisms for processing probabilistic constraints and deriving uncertainty quantifiers, hence establishing a new extended framework, called FPD-OT. Our main contribution in this paper is to establish the connection between OT and FPD, providing new theoretical insights for both. This will lay the foundations for the application of FPD-OT in a subsequent work, notably in processing more sophisticated knowledge constraints, as well as in designing robust solutions in the case of uncertain marginals.
Closed-Loop View of the Regulation of AI: Equal Impact across Repeated Interactions
Sep 03, 2022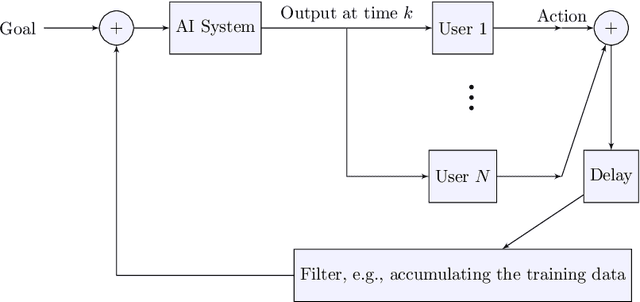
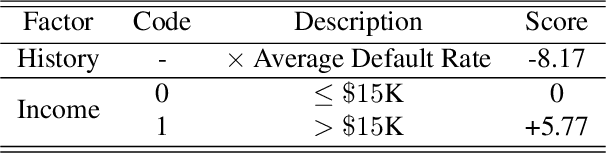
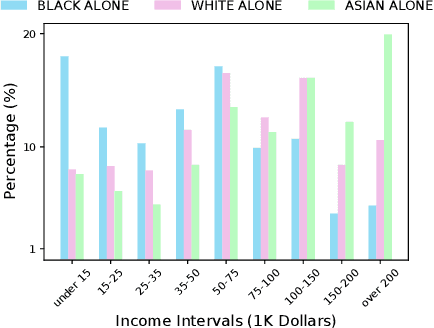
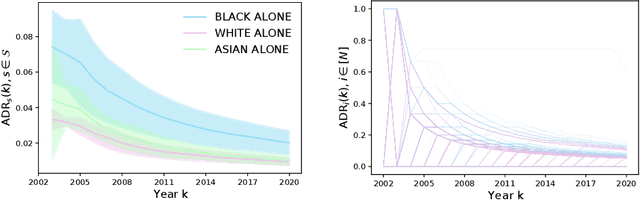
There has been much recent interest in the regulation of AI. We argue for a view based on civil-rights legislation, built on the notions of equal treatment and equal impact. In a closed-loop view of the AI system and its users, the equal treatment concerns one pass through the loop. Equal impact, in our view, concerns the long-run average behaviour across repeated interactions. In order to establish the existence of the average and its properties, one needs to study the ergodic properties of the closed-loop and its unique stationary measure.
Reinforcement Learning with Algorithms from Probabilistic Structure Estimation
Mar 15, 2021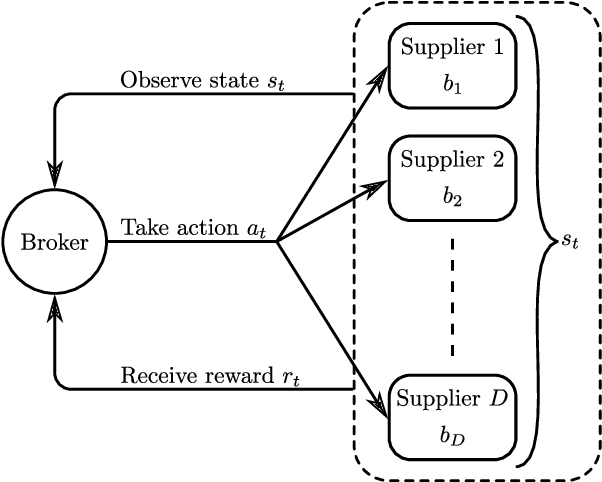
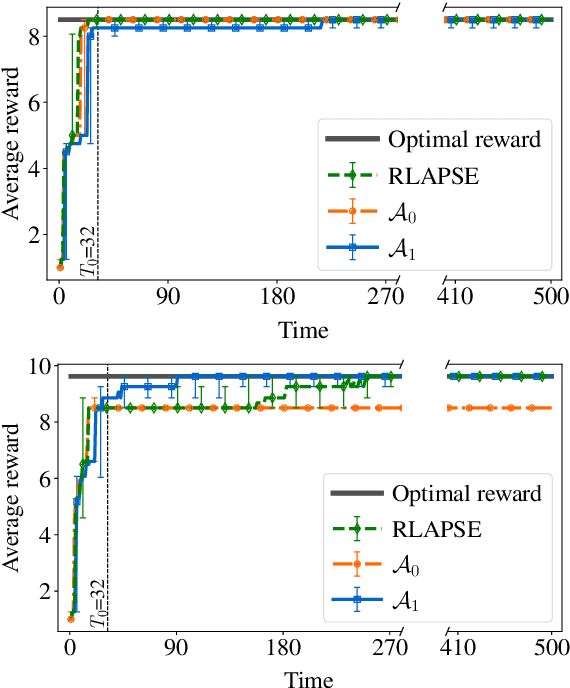
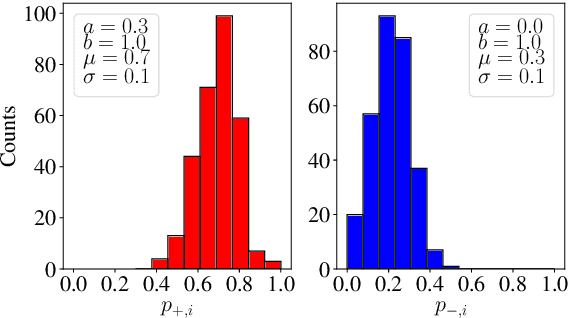
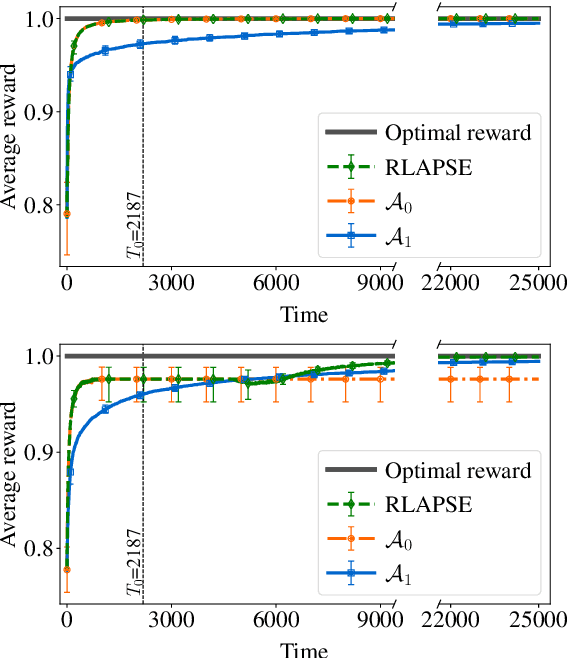
Reinforcement learning (RL) algorithms aim to learn optimal decisions in unknown environments through experience of taking actions and observing the rewards gained. In some cases, the environment is not influenced by the actions of the RL agent, in which case the problem can be modeled as a contextual multi-armed bandit and lightweight \emph{myopic} algorithms can be employed. On the other hand, when the RL agent's actions affect the environment, the problem must be modeled as a Markov decision process and more complex RL algorithms are required which take the future effects of actions into account. Moreover, in many modern RL settings, it is unknown from the outset whether or not the agent's actions will impact the environment and it is often not possible to determine which RL algorithm is most fitting. In this work, we propose to avoid this dilemma entirely and incorporate a choice mechanism into our RL framework. Rather than assuming a specific problem structure, we use a probabilistic structure estimation procedure based on a likelihood-ratio (LR) test to make a more informed selection of learning algorithm. We derive a sufficient condition under which myopic policies are optimal, present an LR test for this condition, and derive a bound on the regret of our framework. We provide examples of real-world scenarios where our framework is needed and provide extensive simulations to validate our approach.