 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Intelligence on the Edge: Interpretable Cardiac Pattern Localisation Using Reinforcement Learning
Aug 29, 2025Matched filters are widely used to localise signal patterns due to their high efficiency and interpretability. However, their effectiveness deteriorates for low signal-to-noise ratio (SNR) signals, such as those recorded on edge devices, where prominent noise patterns can closely resemble the target within the limited length of the filter. One example is the ear-electrocardiogram (ear-ECG), where the cardiac signal is attenuated and heavily corrupted by artefacts. To address this, we propose the Sequential Matched Filter (SMF), a paradigm that replaces the conventional single matched filter with a sequence of filters designed by a Reinforcement Learning agent. By formulating filter design as a sequential decision-making process, SMF adaptively design signal-specific filter sequences that remain fully interpretable by revealing key patterns driving the decision-making. The proposed SMF framework has strong potential for reliable and interpretable clinical decision support, as demonstrated by its state-of-the-art R-peak detection and physiological state classification performance on two challenging real-world ECG datasets. The proposed formulation can also be extended to a broad range of applications that require accurate pattern localisation from noise-corrupted signals.
Learning Network Dismantling without Handcrafted Inputs
Aug 01, 2025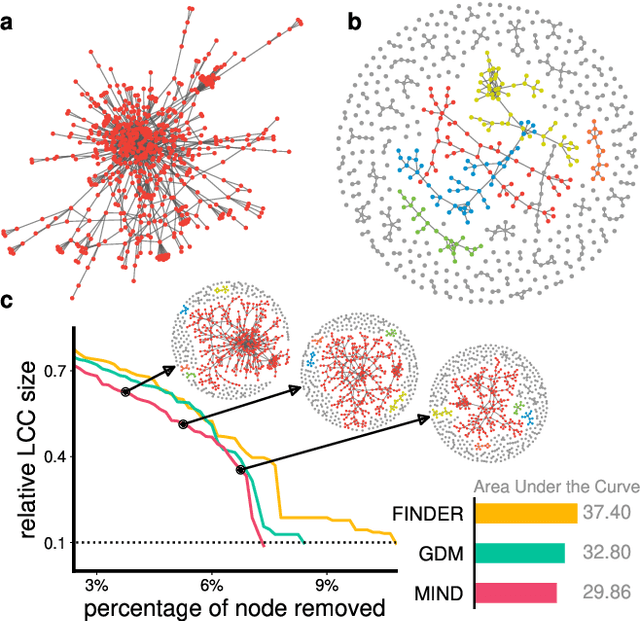

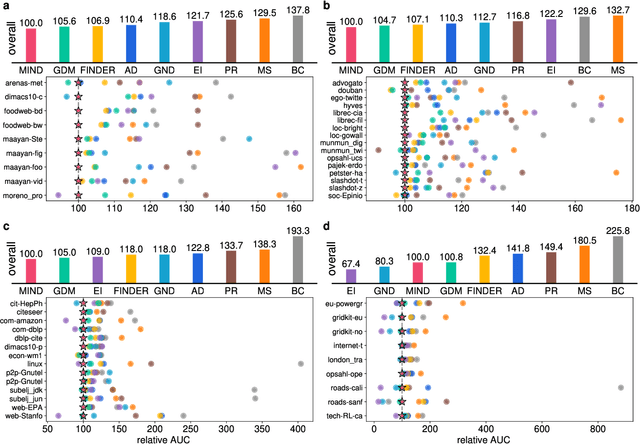
The application of message-passing Graph Neural Networks has been a breakthrough for important network science problems. However, the competitive performance often relies on using handcrafted structural features as inputs, which increases computational cost and introduces bias into the otherwise purely data-driven network representations. Here, we eliminate the need for handcrafted features by introducing an attention mechanism and utilizing message-iteration profiles, in addition to an effective algorithmic approach to generate a structurally diverse training set of small synthetic networks. Thereby, we build an expressive message-passing framework and use it to efficiently solve the NP-hard problem of Network Dismantling, virtually equivalent to vital node identification, with significant real-world applications. Trained solely on diversified synthetic networks, our proposed model -- MIND: Message Iteration Network Dismantler -- generalizes to large, unseen real networks with millions of nodes, outperforming state-of-the-art network dismantling methods. Increased efficiency and generalizability of the proposed model can be leveraged beyond dismantling in a range of complex network problems.
Induced Modularity and Community Detection for Functionally Interpretable Reinforcement Learning
Jan 28, 2025



Interpretability in reinforcement learning is crucial for ensuring AI systems align with human values and fulfill the diverse related requirements including safety, robustness and fairness. Building on recent approaches to encouraging sparsity and locality in neural networks, we demonstrate how the penalisation of non-local weights leads to the emergence of functionally independent modules in the policy network of a reinforcement learning agent. To illustrate this, we demonstrate the emergence of two parallel modules for assessment of movement along the X and Y axes in a stochastic Minigrid environment. Through the novel application of community detection algorithms, we show how these modules can be automatically identified and their functional roles verified through direct intervention on the network weights prior to inference. This establishes a scalable framework for reinforcement learning interpretability through functional modularity, addressing challenges regarding the trade-off between completeness and cognitive tractability of reinforcement learning explanations.
Reinforcement Learning with Adaptive Control Regularization for Safe Control of Critical Systems
Apr 23, 2024



Reinforcement Learning (RL) is a powerful method for controlling dynamic systems, but its learning mechanism can lead to unpredictable actions that undermine the safety of critical systems. Here, we propose RL with Adaptive Control Regularization (RL-ACR) that ensures RL safety by combining the RL policy with a control regularizer that hard-codes safety constraints over forecasted system behaviors. The adaptability is achieved by using a learnable "focus" weight trained to maximize the cumulative reward of the policy combination. As the RL policy improves through off-policy learning, the focus weight improves the initial sub-optimum strategy by gradually relying more on the RL policy. We demonstrate the effectiveness of RL-ACR in a critical medical control application and further investigate its performance in four classic control environments.
Single-cell phase-contrast tomograms data encoded by 3D Zernike descriptors
Jul 11, 2022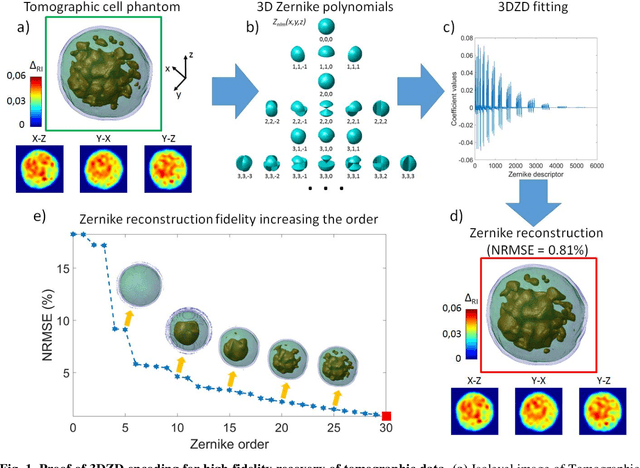
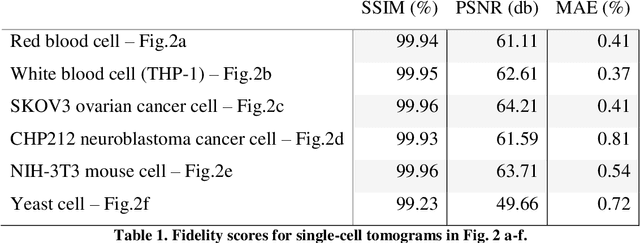
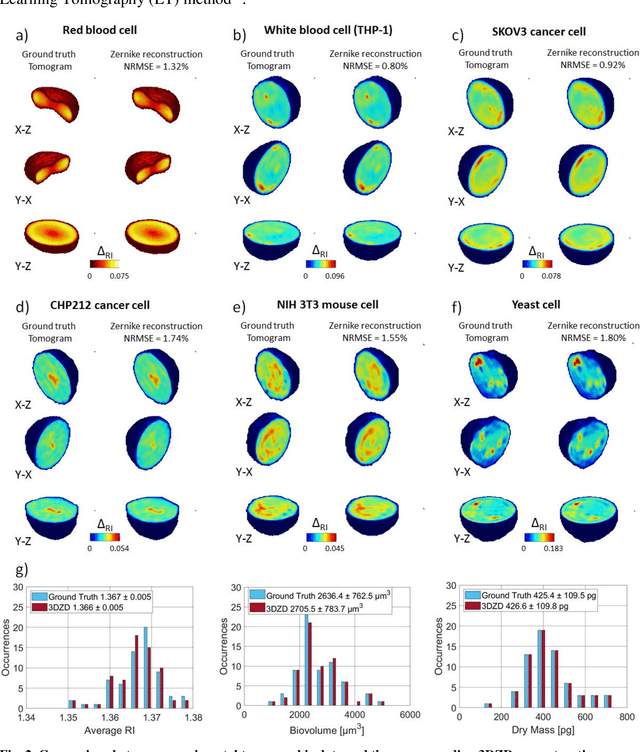
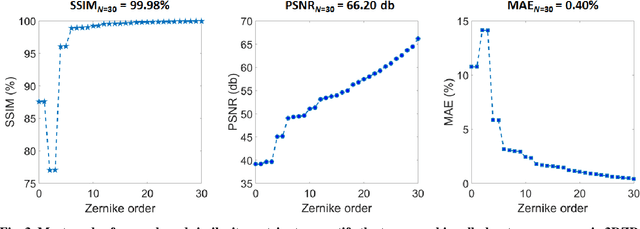
Phase-contrast tomographic flow cytometry combines quantitative 3D analysis of unstained single cells and high-throughput. A crucial issue of this method is the storage and management of the huge amount of 3D tomographic data. Here we show an effective quasi lossless compression of tomograms data through 3D Zernike descriptors, unlocking data management tasks and computational pipelines that were unattainable until now.
Driving Reinforcement Learning with Models
Nov 11, 2019


Over the years, Reinforcement Learning (RL) established itself as a convenient paradigm to learn optimal policies from data. However, most RL algorithms achieve optimal policies by exploring all the possible actions and this, in real-world scenarios, is often infeasible or impractical due to e.g. safety constraints. Motivated by this, in this paper we propose to augment RL with Model Predictive Control (MPC), a popular model-based control algorithm that allows to optimally control a system while satisfying a set of constraints. The result is an algorithm, the MPC-augmented RL algorithm (MPCaRL) that makes use of MPC to both drive how RL explores the actions and to modify the corresponding rewards. We demonstrate the effectiveness of the MPCaRL by letting it play against the Atari game Pong. The results obtained highlight the ability of the algorithm to learn general tasks with essentially no training.