 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Inference on Stopped Random Walks in Online Advertising
Feb 05, 2026We consider a causal inference problem frequently encountered in online advertising systems, where a publisher (e.g., Instagram, TikTok) interacts repeatedly with human users and advertisers by sporadically displaying to each user an advertisement selected through an auction. Each treatment corresponds to a parameter value of the advertising mechanism (e.g., auction reserve-price), and we want to estimate through experiments the corresponding long-term treatment effect (e.g., annual advertising revenue). In our setting, the treatment affects not only the instantaneous revenue from showing an ad, but also changes each user's interaction-trajectory, and each advertiser's bidding policy -- as the latter is constrained by a finite budget. In particular, each a treatment may even affect the size of the population, since users interact longer with a tolerable advertising mechanism. We drop the classical i.i.d. assumption and model the experiment measurements (e.g., advertising revenue) as a stopped random walk, and use a budget-splitting experimental design, the Anscombe Theorem, a Wald-like equation, and a Central Limit Theorem to construct confidence intervals for the long-term treatment effect.
Outperformance Score: A Universal Standardization Method for Confusion-Matrix-Based Classification Performance Metrics
May 11, 2025Many classification performance metrics exist, each suited to a specific application. However, these metrics often differ in scale and can exhibit varying sensitivity to class imbalance rates in the test set. As a result, it is difficult to use the nominal values of these metrics to interpret and evaluate classification performances, especially when imbalance rates vary. To address this problem, we introduce the outperformance score function, a universal standardization method for confusion-matrix-based classification performance (CMBCP) metrics. It maps any given metric to a common scale of $[0,1]$, while providing a clear and consistent interpretation. Specifically, the outperformance score represents the percentile rank of the observed classification performance within a reference distribution of possible performances. This unified framework enables meaningful comparison and monitoring of classification performance across test sets with differing imbalance rates. We illustrate how the outperformance scores can be applied to a variety of commonly used classification performance metrics and demonstrate the robustness of our method through experiments on real-world datasets spanning multiple classification applications.
Error Analysis of Shapley Value-Based Model Explanations: An Informative Perspective
Apr 21, 2024Shapley value attribution is an increasingly popular explainable AI (XAI) method, which quantifies the contribution of each feature to the model's output. However, recent work has shown that most existing methods to implement Shapley value attributions have some drawbacks. Due to these drawbacks, the resulting Shapley value attributions may provide biased or unreliable explanations, which fail to correctly capture the true intrinsic relationships between features and model outputs. Moreover, it is difficult to evaluate these explanation errors because the true underlying dependencies between features and model outputs are typically unknown. In this paper, we theoretically analyze the explanation errors of Shapley value attributions by decomposing the explanation error into two components: observation bias and structural bias. We also clarify the underlying causes of these two biases and demonstrate that there is a trade-off between them. Based on this error analysis framework, we develop two novel concepts: over-informative and under-informative explanations. We theoretically analyze the potential over-informativeness and under-informativeness of existing Shapley value attribution methods. Particularly for the widely deployed assumption-based Shapley value attributions, we affirm that they can easily be under-informative due to the distribution drift caused by distributional assumptions. We also propose a measurement tool to quantify the distribution drift that causes such errors.
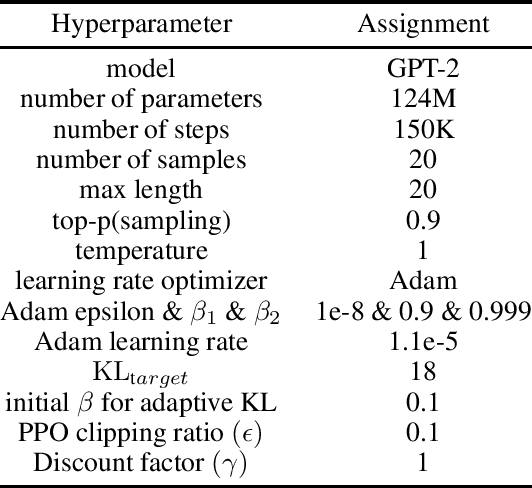
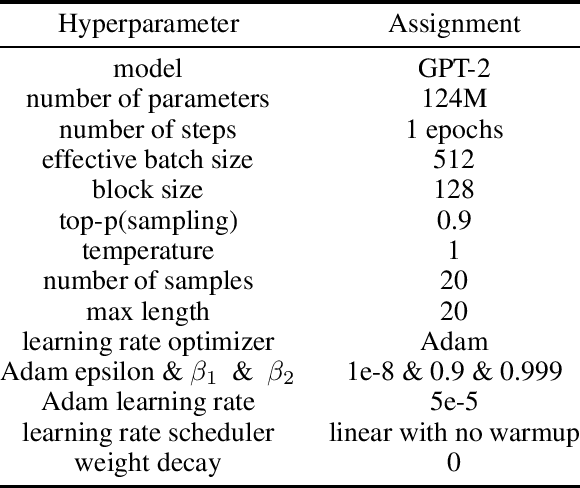
Reward Modeling for Mitigating Toxicity in Transformer-based Language Models
Feb 28, 2022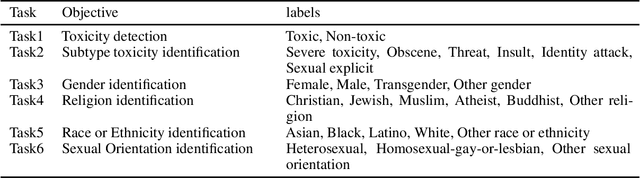

Transformer-based language models are able to generate fluent text and be efficiently adapted across various natural language generation tasks. However, language models that are pretrained on large unlabeled web text corpora have been shown to suffer from degenerating toxic content and social bias behaviors, consequently hindering their safe deployment. Various detoxification methods were proposed to mitigate the language model's toxicity; however, these methods struggled to detoxify language models when conditioned on prompts that contain specific social identities related to gender, race, or religion. In this study, we propose Reinforce-Detoxify; A reinforcement learning-based method for mitigating toxicity in language models. We address the challenge of safety in language models and propose a new reward model that is able to detect toxic content and mitigate unintended bias towards social identities in toxicity prediction. The experiments demonstrate that the Reinforce-Detoxify method for language model detoxification outperforms existing detoxification approaches in automatic evaluation metrics, indicating the ability of our approach in language model detoxification and less prone to unintended bias toward social identities in generated content.
Multi-resource allocation for federated settings: A non-homogeneous Markov chain model
Apr 26, 2021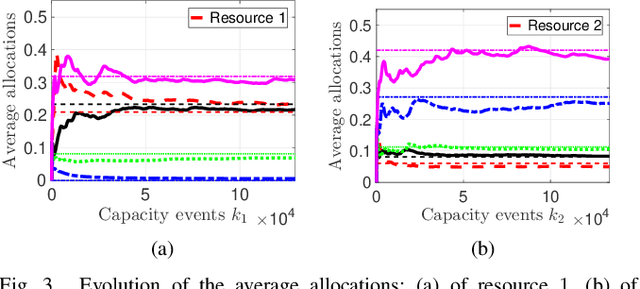
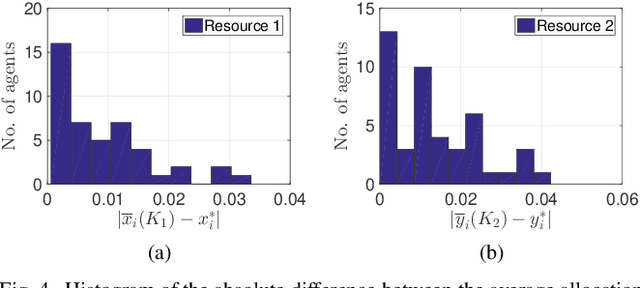
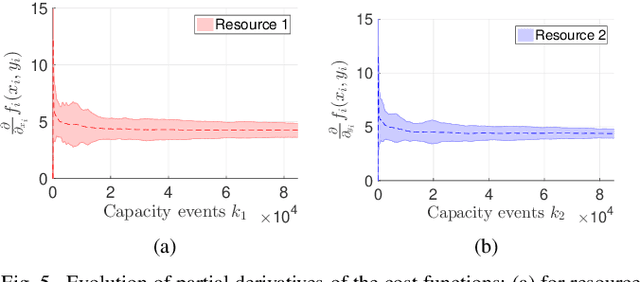
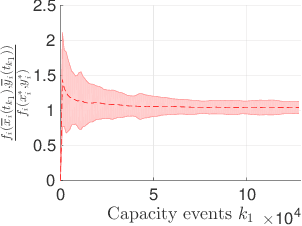
In a federated setting, agents coordinate with a central agent or a server to solve an optimization problem in which agents do not share their information with each other. Wirth and his co-authors, in a recent paper, describe how the basic additive-increase multiplicative-decrease (AIMD) algorithm can be modified in a straightforward manner to solve a class of optimization problems for federated settings for a single shared resource with no inter-agent communication. The AIMD algorithm is one of the most successful distributed resource allocation algorithms currently deployed in practice. It is best known as the backbone of the Internet and is also widely explored in other application areas. We extend the single-resource algorithm to multiple heterogeneous shared resources that emerge in smart cities, sharing economy, and many other applications. Our main results show the convergence of the average allocations to the optimal values. We model the system as a non-homogeneous Markov chain with place-dependent probabilities. Furthermore, simulation results are presented to demonstrate the efficacy of the algorithms and to highlight the main features of our analysis.
Bias-Corrected Peaks-Over-Threshold Estimation of the CVaR
Mar 08, 2021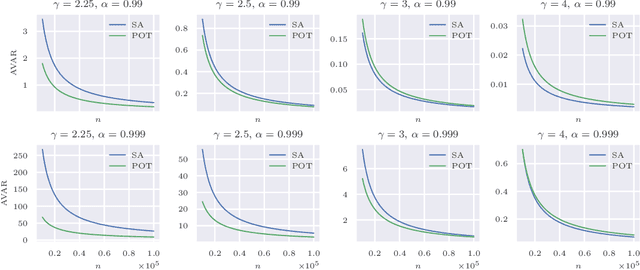
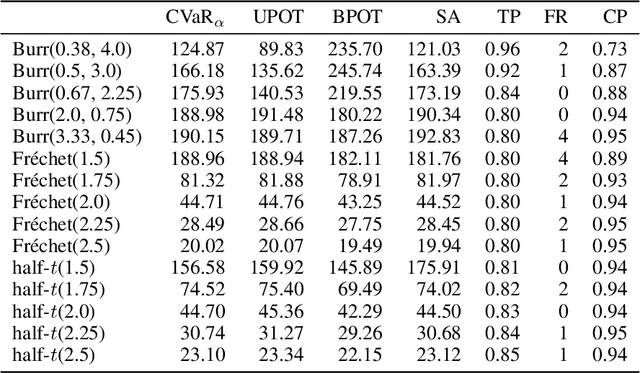
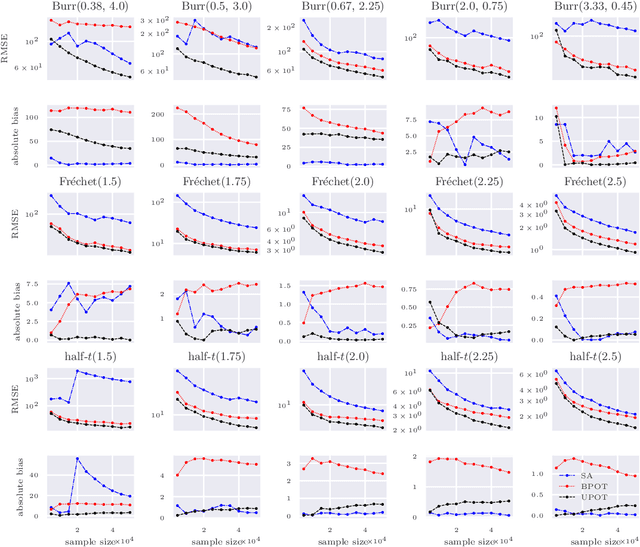
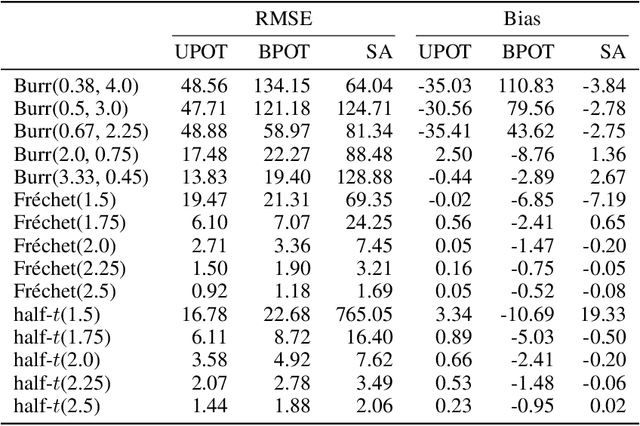
The conditional value-at-risk (CVaR) is a useful risk measure in fields such as machine learning, finance, insurance, energy, etc. When measuring very extreme risk, the commonly used CVaR estimation method of sample averaging does not work well due to limited data above the value-at-risk (VaR), the quantile corresponding to the CVaR level. To mitigate this problem, the CVaR can be estimated by extrapolating above a lower threshold than the VaR using a generalized Pareto distribution (GPD), which is often referred to as the peaks-over-threshold (POT) approach. This method often requires a very high threshold to fit well, leading to high variance in estimation, and can induce significant bias if the threshold is chosen too low. In this paper, we derive a new expression for the GPD approximation error of the CVaR, a bias term induced by the choice of threshold, as well as a bias correction method for the estimated GPD parameters. This leads to the derivation of a new estimator for the CVaR that we prove to be asymptotically unbiased. In a practical setting, we show through experiments that our estimator provides a significant performance improvement compared with competing CVaR estimators in finite samples. As a consequence of our bias correction method, it is also shown that a much lower threshold can be selected without introducing significant bias. This allows a larger portion of data to be be used in CVaR estimation compared with the typical POT approach, leading to more stable estimates. As secondary results, a new estimator for a second-order parameter of heavy-tailed distributions is derived, as well as a confidence interval for the CVaR which enables quantifying the level of variability in our estimator.
Generating Embroidery Patterns Using Image-to-Image Translation
Mar 05, 2020
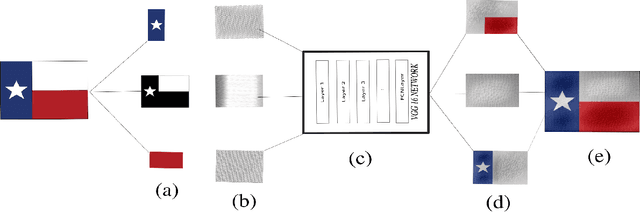

In many scenarios in computer vision, machine learning, and computer graphics, there is a requirement to learn the mapping from an image of one domain to an image of another domain, called Image-to-image translation. For example, style transfer, object transfiguration, visually altering the appearance of weather conditions in an image, changing the appearance of a day image into a night image or vice versa, photo enhancement, to name a few. In this paper, we propose two machine learning techniques to solve the embroidery image-to-image translation. Our goal is to generate a preview image which looks similar to an embroidered image, from a user-uploaded image. Our techniques are modifications of two existing techniques, neural style transfer, and cycle-consistent generative-adversarial network. Neural style transfer renders the semantic content of an image from one domain in the style of a different image in another domain, whereas a cycle-consistent generative adversarial network learns the mapping from an input image to output image without any paired training data, and also learn a loss function to train this mapping. Furthermore, the techniques we propose are independent of any embroidery attributes, such as elevation of the image, light-source, start, and endpoints of a stitch, type of stitch used, fabric type, etc. Given the user image, our techniques can generate a preview image which looks similar to an embroidered image. We train and test our propose techniques on an embroidery dataset which consist of simple 2D images. To do so, we prepare an unpaired embroidery dataset with more than 8000 user-uploaded images along with embroidered images. Empirical results show that these techniques successfully generate an approximate preview of an embroidered version of a user image, which can help users in decision making.
Risk-Averse Action Selection Using Extreme Value Theory Estimates of the CVaR
Dec 03, 2019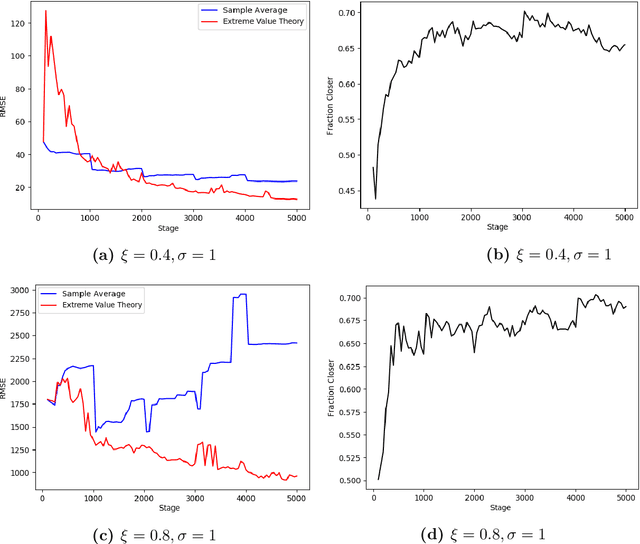
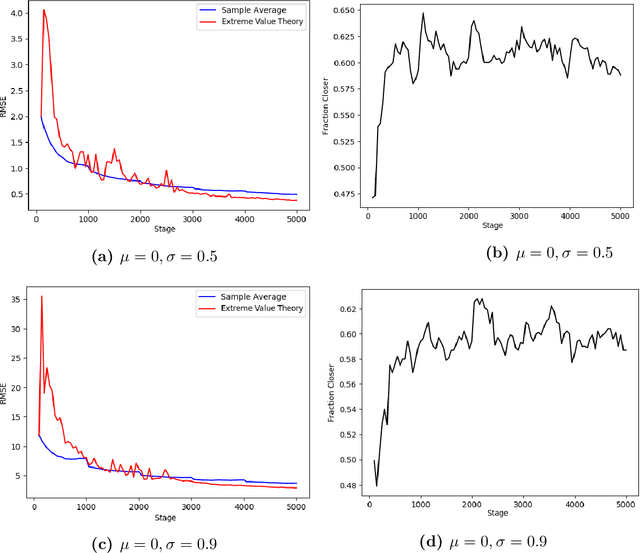
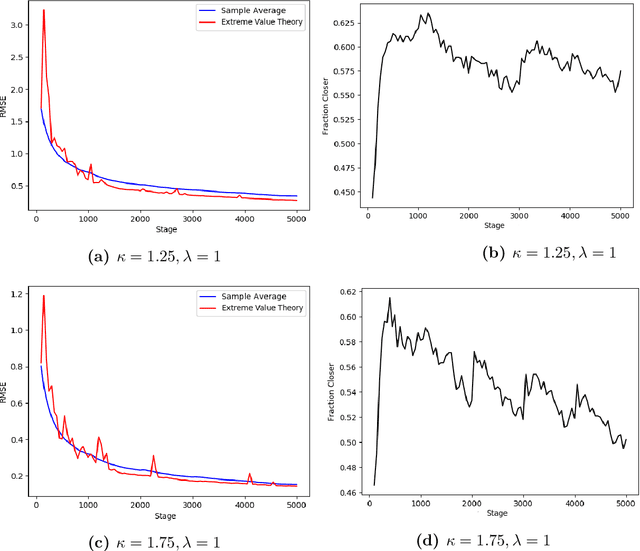
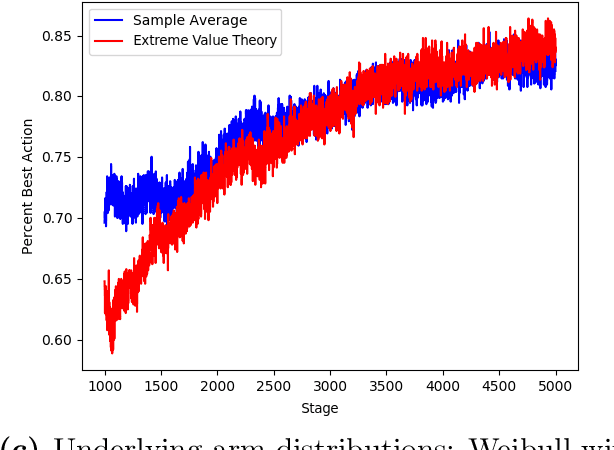
The Conditional Value-at-Risk (CVaR) is a useful risk measure in machine learning, finance, insurance, energy, etc. When the CVaR confidence parameter is very high, estimation by sample averaging exhibits high variance due to the limited number of samples above the corresponding threshold. To mitigate this problem, we present an estimation procedure for the CVaR that combines extreme value theory and a recently introduced method of automated threshold selection by Bader et al. (2018). Under appropriate conditions, we estimate the tail risk using a generalized Pareto distribution. We compare empirically this estimation procedure with the naive method of sample averaging, and show an improvement in accuracy for some specific cases. We also show how the estimation procedure can be used in reinforcement learning by applying our method to the multi-armed bandit problem where the goal is to avoid catastrophic risk.
A Scheme for Dynamic Risk-Sensitive Sequential Decision Making
Jul 09, 2019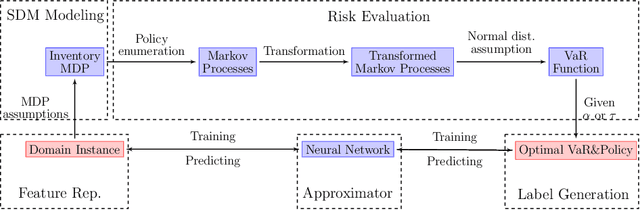
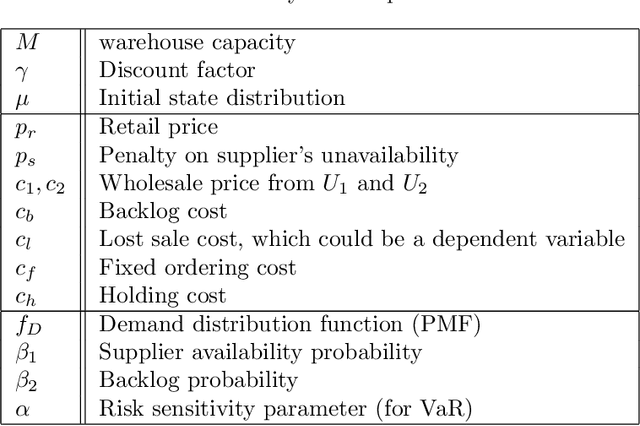
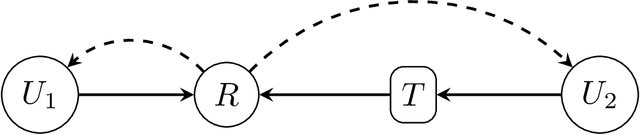
We present a scheme for sequential decision making with a risk-sensitive objective and constraints in a dynamic environment. A neural network is trained as an approximator of the mapping from parameter space to space of risk and policy with risk-sensitive constraints. For a given risk-sensitive problem, in which the objective and constraints are, or can be estimated by, functions of the mean and variance of return, we generate a synthetic dataset as training data. Parameters defining a targeted process might be dynamic, i.e., they might vary over time, so we sample them within specified intervals to deal with these dynamics. We show that: i). Most risk measures can be estimated using return variance; ii). By virtue of the state-augmentation transformation, practical problems modeled by Markov decision processes with stochastic rewards can be solved in a risk-sensitive scenario; and iii). The proposed scheme is validated by a numerical experiment.
Variance-Based Risk Estimations in Markov Processes via Transformation with State Lumping
Jul 09, 2019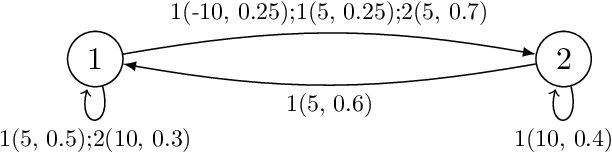
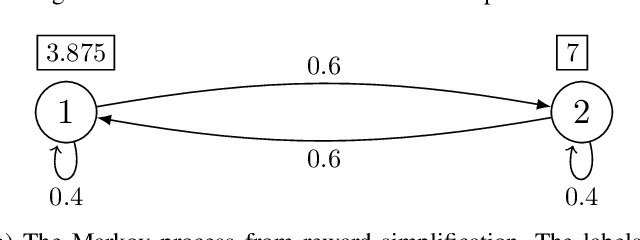
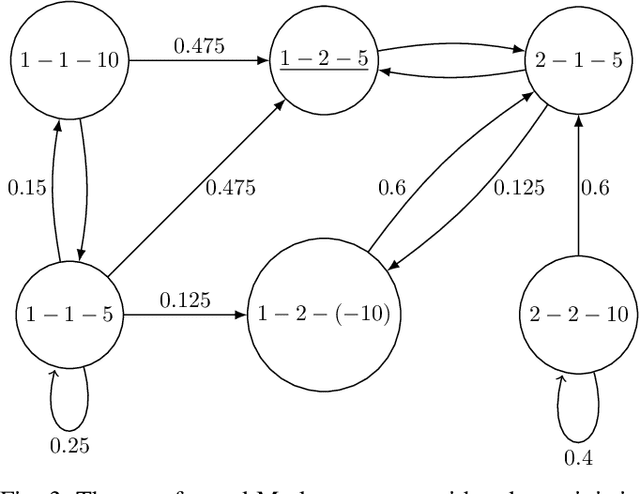
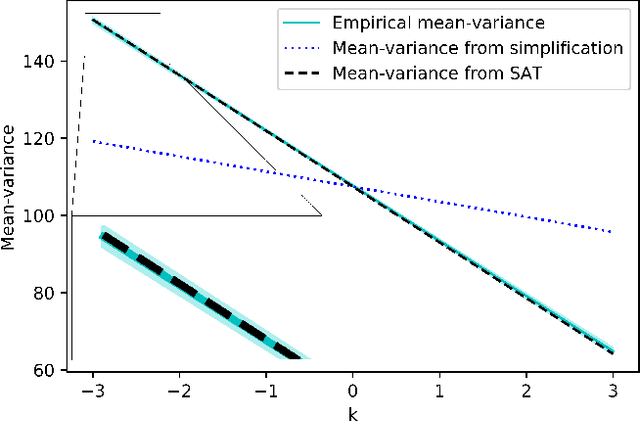
Variance plays a crucial role in risk-sensitive reinforcement learning, and most risk measures can be analyzed via variance. In this paper, we consider two law-invariant risks as examples: mean-variance risk and exponential utility risk. With the aid of the state-augmentation transformation (SAT), we show that, the two risks can be estimated in Markov decision processes (MDPs) with a stochastic transition-based reward and a randomized policy. To relieve the enlarged state space, a novel definition of isotopic states is proposed for state lumping, considering the special structure of the transformed transition probability. In the numerical experiment, we illustrate state lumping in the SAT, errors from a naive reward simplification, and the validity of the SAT for the two risk estimations.