 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVEREST: An Evidential, Tail-Aware Transformer for Rare-Event Time-Series Forecasting
Jan 26, 2026Forecasting rare events in multivariate time-series data is challenging due to severe class imbalance, long-range dependencies, and distributional uncertainty. We introduce EVEREST, a transformer-based architecture for probabilistic rare-event forecasting that delivers calibrated predictions and tail-aware risk estimation, with auxiliary interpretability via attention-based signal attribution. EVEREST integrates four components: (i) a learnable attention bottleneck for soft aggregation of temporal dynamics; (ii) an evidential head for estimating aleatoric and epistemic uncertainty via a Normal--Inverse--Gamma distribution; (iii) an extreme-value head that models tail risk using a Generalized Pareto Distribution; and (iv) a lightweight precursor head for early-event detection. These modules are jointly optimized with a composite loss (focal loss, evidential NLL, and a tail-sensitive EVT penalty) and act only at training time; deployment uses a single classification head with no inference overhead (approximately 0.81M parameters). On a decade of space-weather data, EVEREST achieves state-of-the-art True Skill Statistic (TSS) of 0.973/0.970/0.966 at 24/48/72-hour horizons for C-class flares. The model is compact, efficient to train on commodity hardware, and applicable to high-stakes domains such as industrial monitoring, weather, and satellite diagnostics. Limitations include reliance on fixed-length inputs and exclusion of image-based modalities, motivating future extensions to streaming and multimodal forecasting.
Stochastic Sample Approximations of (Local) Moduli of Continuity
Sep 18, 2025Modulus of local continuity is used to evaluate the robustness of neural networks and fairness of their repeated uses in closed-loop models. Here, we revisit a connection between generalized derivatives and moduli of local continuity, and present a non-uniform stochastic sample approximation for moduli of local continuity. This is of importance in studying robustness of neural networks and fairness of their repeated uses.
Learning Time-Varying Convexifications of Multiple Fairness Measures
Aug 19, 2025There is an increasing appreciation that one may need to consider multiple measures of fairness, e.g., considering multiple group and individual fairness notions. The relative weights of the fairness regularisers are a priori unknown, may be time varying, and need to be learned on the fly. We consider the learning of time-varying convexifications of multiple fairness measures with limited graph-structured feedback.
Sample Complexity of Bias Detection with Subsampled Point-to-Subspace Distances
Feb 04, 2025Sample complexity of bias estimation is a lower bound on the runtime of any bias detection method. Many regulatory frameworks require the bias to be tested for all subgroups, whose number grows exponentially with the number of protected attributes. Unless one wishes to run a bias detection with a doubly-exponential run-time, one should like to have polynomial complexity of bias detection for a single subgroup. At the same time, the reference data may be based on surveys, and thus come with non-trivial uncertainty. Here, we reformulate bias detection as a point-to-subspace problem on the space of measures and show that, for supremum norm, it can be subsampled efficiently. In particular, our probabilistically approximately correct (PAC) results are corroborated by tests on well-known instances.
Empirical Bayes for Dynamic Bayesian Networks Using Generalized Variational Inference
Jun 25, 2024
In this work, we demonstrate the Empirical Bayes approach to learning a Dynamic Bayesian Network. By starting with several point estimates of structure and weights, we can use a data-driven prior to subsequently obtain a model to quantify uncertainty. This approach uses a recent development of Generalized Variational Inference, and indicates the potential of sampling the uncertainty of a mixture of DAG structures as well as a parameter posterior.
Fairness in Ranking: Robustness through Randomization without the Protected Attribute
Mar 28, 2024There has been great interest in fairness in machine learning, especially in relation to classification problems. In ranking-related problems, such as in online advertising, recommender systems, and HR automation, much work on fairness remains to be done. Two complications arise: first, the protected attribute may not be available in many applications. Second, there are multiple measures of fairness of rankings, and optimization-based methods utilizing a single measure of fairness of rankings may produce rankings that are unfair with respect to other measures. In this work, we propose a randomized method for post-processing rankings, which do not require the availability of the protected attribute. In an extensive numerical study, we show the robustness of our methods with respect to P-Fairness and effectiveness with respect to Normalized Discounted Cumulative Gain (NDCG) from the baseline ranking, improving on previously proposed methods.
Learning quantum Hamiltonians at any temperature in polynomial time with Chebyshev and bit complexity
Feb 08, 2024We consider the problem of learning local quantum Hamiltonians given copies of their Gibbs state at a known inverse temperature, following Haah et al. [2108.04842] and Bakshi et al. [arXiv:2310.02243]. Our main technical contribution is a new flat polynomial approximation of the exponential function based on the Chebyshev expansion, which enables the formulation of learning quantum Hamiltonians as a polynomial optimization problem. This, in turn, can benefit from the use of moment/SOS relaxations, whose polynomial bit complexity requires careful analysis [O'Donnell, ITCS 2017]. Finally, we show that learning a $k$-local Hamiltonian, whose dual interaction graph is of bounded degree, runs in polynomial time under mild assumptions.
Generating Likely Counterfactuals Using Sum-Product Networks
Jan 25, 2024



Due to user demand and recent regulation (GDPR, AI Act), decisions made by AI systems need to be explained. These decisions are often explainable only post hoc, where counterfactual explanations are popular. The question of what constitutes the best counterfactual explanation must consider multiple aspects, where "distance from the sample" is the most common. We argue that this requirement frequently leads to explanations that are unlikely and, therefore, of limited value. Here, we present a system that provides high-likelihood explanations. We show that the search for the most likely explanations satisfying many common desiderata for counterfactual explanations can be modeled using mixed-integer optimization (MIO). In the process, we propose an MIO formulation of a Sum-Product Network (SPN) and use the SPN to estimate the likelihood of a counterfactual, which can be of independent interest. A numerical comparison against several methods for generating counterfactual explanations is provided.
Joint Problems in Learning Multiple Dynamical Systems
Nov 03, 2023Clustering of time series is a well-studied problem, with applications ranging from quantitative, personalized models of metabolism obtained from metabolite concentrations to state discrimination in quantum information theory. We consider a variant, where given a set of trajectories and a number of parts, we jointly partition the set of trajectories and learn linear dynamical system (LDS) models for each part, so as to minimize the maximum error across all the models. We present globally convergent methods and EM heuristics, accompanied by promising computational results.
Group-blind optimal transport to group parity and its constrained variants
Oct 17, 2023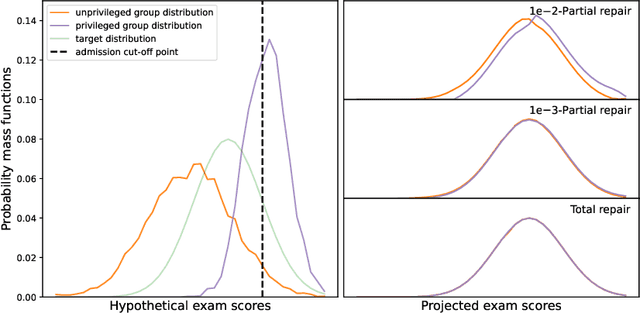
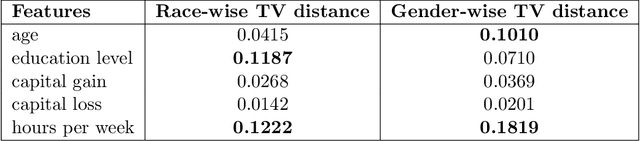
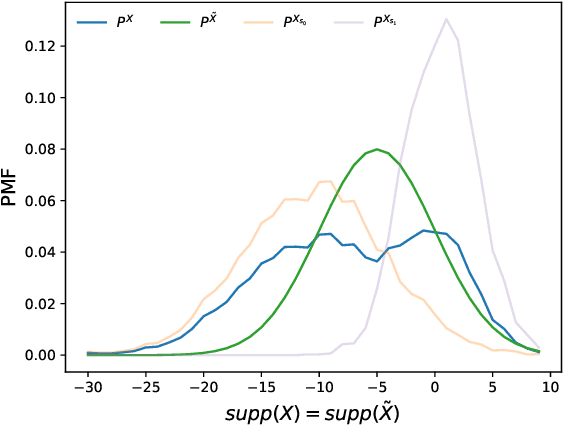
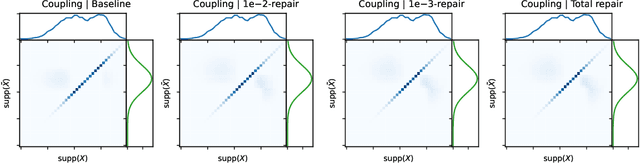
Fairness holds a pivotal role in the realm of machine learning, particularly when it comes to addressing groups categorised by sensitive attributes, e.g., gender, race. Prevailing algorithms in fair learning predominantly hinge on accessibility or estimations of these sensitive attributes, at least in the training process. We design a single group-blind projection map that aligns the feature distributions of both groups in the source data, achieving (demographic) group parity, without requiring values of the protected attribute for individual samples in the computation of the map, as well as its use. Instead, our approach utilises the feature distributions of the privileged and unprivileged groups in a boarder population and the essential assumption that the source data are unbiased representation of the population. We present numerical results on synthetic data and real data.