 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup-blind optimal transport to group parity and its constrained variants
Paper and Code
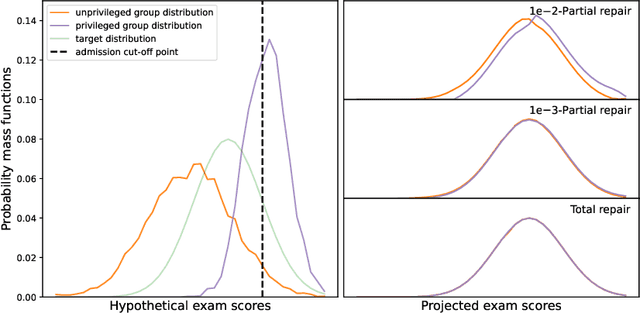
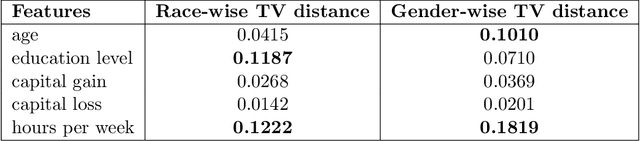
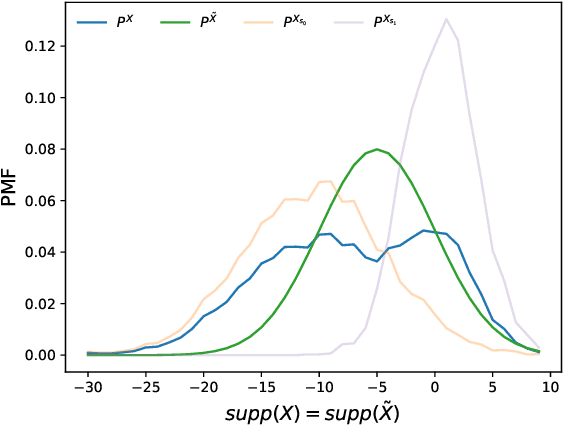
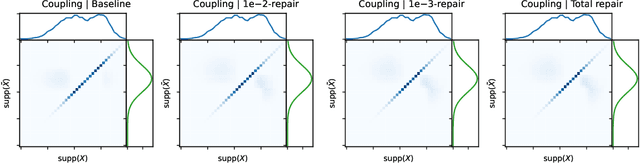
Fairness holds a pivotal role in the realm of machine learning, particularly when it comes to addressing groups categorised by sensitive attributes, e.g., gender, race. Prevailing algorithms in fair learning predominantly hinge on accessibility or estimations of these sensitive attributes, at least in the training process. We design a single group-blind projection map that aligns the feature distributions of both groups in the source data, achieving (demographic) group parity, without requiring values of the protected attribute for individual samples in the computation of the map, as well as its use. Instead, our approach utilises the feature distributions of the privileged and unprivileged groups in a boarder population and the essential assumption that the source data are unbiased representation of the population. We present numerical results on synthetic data and real data.