 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Associated Meta Learning for Clinical Prediction
Mar 05, 2023Rich Electronic Health Records (EHR), have created opportunities to improve clinical processes using machine learning methods. Prediction of the same patient events at different time horizons can have very different applications and interpretations; however, limited number of events in each potential time window hurts the effectiveness of conventional machine learning algorithms. We propose a novel time associated meta learning (TAML) method to make effective predictions at multiple future time points. We view time-associated disease prediction as classification tasks at multiple time points. Such closely-related classification tasks are an excellent candidate for model-based meta learning. To address the sparsity problem after task splitting, TAML employs a temporal information sharing strategy to augment the number of positive samples and include the prediction of related phenotypes or events in the meta-training phase. We demonstrate the effectiveness of TAML on multiple clinical datasets, where it consistently outperforms a range of strong baselines. We also develop a MetaEHR package for implementing both time-associated and time-independent few-shot prediction on EHR data.
A Multi-View Joint Learning Framework for Embedding Clinical Codes and Text Using Graph Neural Networks
Jan 27, 2023Learning to represent free text is a core task in many clinical machine learning (ML) applications, as clinical text contains observations and plans not otherwise available for inference. State-of-the-art methods use large language models developed with immense computational resources and training data; however, applying these models is challenging because of the highly varying syntax and vocabulary in clinical free text. Structured information such as International Classification of Disease (ICD) codes often succinctly abstracts the most important facts of a clinical encounter and yields good performance, but is often not as available as clinical text in real-world scenarios. We propose a \textbf{multi-view learning framework} that jointly learns from codes and text to combine the availability and forward-looking nature of text and better performance of ICD codes. The learned text embeddings can be used as inputs to predictive algorithms independent of the ICD codes during inference. Our approach uses a Graph Neural Network (GNN) to process ICD codes, and Bi-LSTM to process text. We apply Deep Canonical Correlation Analysis (DCCA) to enforce the two views to learn a similar representation of each patient. In experiments using planned surgical procedure text, our model outperforms BERT models fine-tuned to clinical data, and in experiments using diverse text in MIMIC-III, our model is competitive to a fine-tuned BERT at a tiny fraction of its computational effort.
Self-explaining Hierarchical Model for Intraoperative Time Series
Oct 10, 2022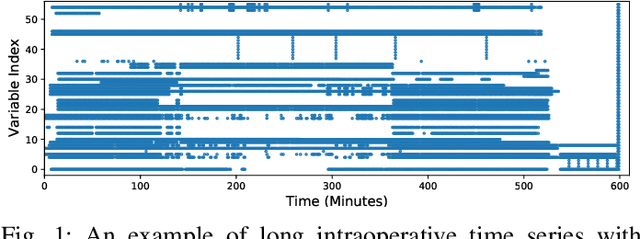
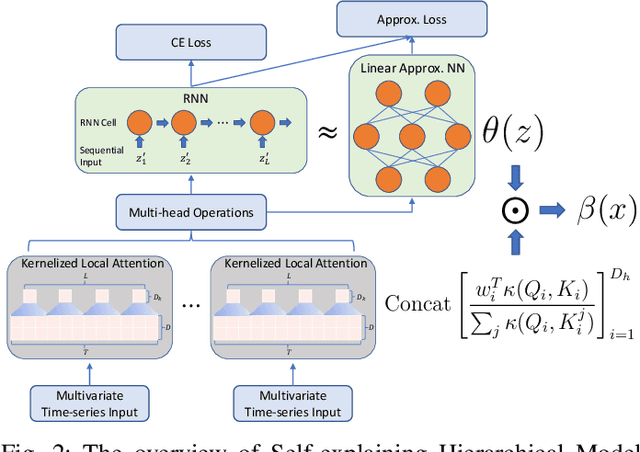
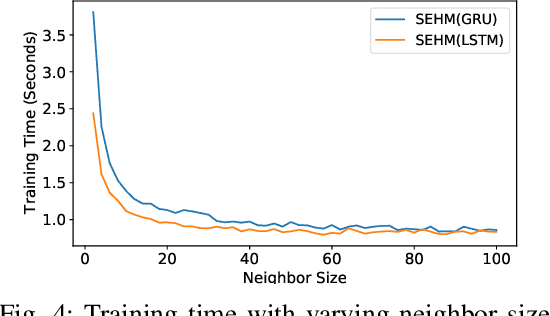
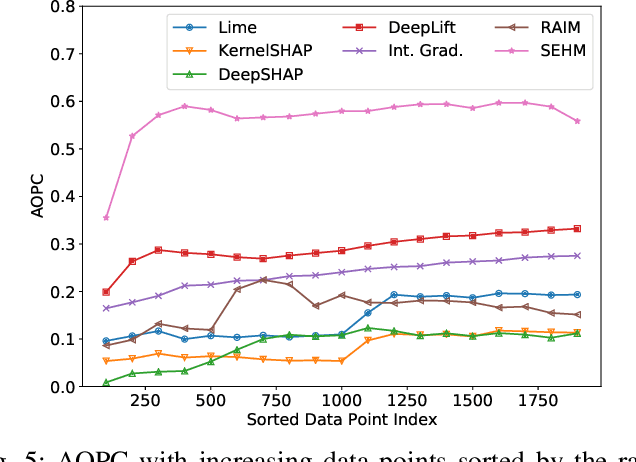
Major postoperative complications are devastating to surgical patients. Some of these complications are potentially preventable via early predictions based on intraoperative data. However, intraoperative data comprise long and fine-grained multivariate time series, prohibiting the effective learning of accurate models. The large gaps associated with clinical events and protocols are usually ignored. Moreover, deep models generally lack transparency. Nevertheless, the interpretability is crucial to assist clinicians in planning for and delivering postoperative care and timely interventions. Towards this end, we propose a hierarchical model combining the strength of both attention and recurrent models for intraoperative time series. We further develop an explanation module for the hierarchical model to interpret the predictions by providing contributions of intraoperative data in a fine-grained manner. Experiments on a large dataset of 111,888 surgeries with multiple outcomes and an external high-resolution ICU dataset show that our model can achieve strong predictive performance (i.e., high accuracy) and offer robust interpretations (i.e., high transparency) for predicted outcomes based on intraoperative time series.
Evaluation of Non-Invasive Thermal Imaging for detection of Viability of Onchocerciasis worms
Mar 23, 2022
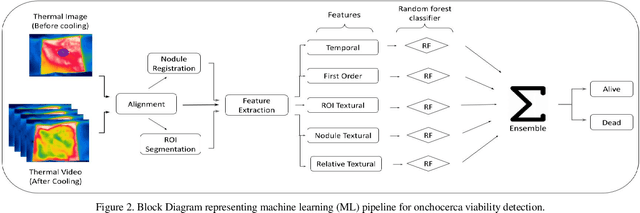
Onchocerciasis is causing blindness in over half a million people in the world today. Drug development for the disease is crippled as there is no way of measuring effectiveness of the drug without an invasive procedure. Drug efficacy measurement through assessment of viability of onchocerca worms requires the patients to undergo nodulectomy which is invasive, expensive, time-consuming, skill-dependent, infrastructure dependent and lengthy process. In this paper, we discuss the first-ever study that proposes use of machine learning over thermal imaging to non-invasively and accurately predict the viability of worms. The key contributions of the paper are (i) a unique thermal imaging protocol along with pre-processing steps such as alignment, registration and segmentation to extract interpretable features (ii) extraction of relevant semantic features (iii) development of accurate classifiers for detecting the existence of viable worms in a nodule. When tested on a prospective test data of 30 participants with 48 palpable nodules, we achieved an Area Under the Curve (AUC) of 0.85.
A Modulation Layer to Increase Neural Network Robustness Against Data Quality Issues
Jul 19, 2021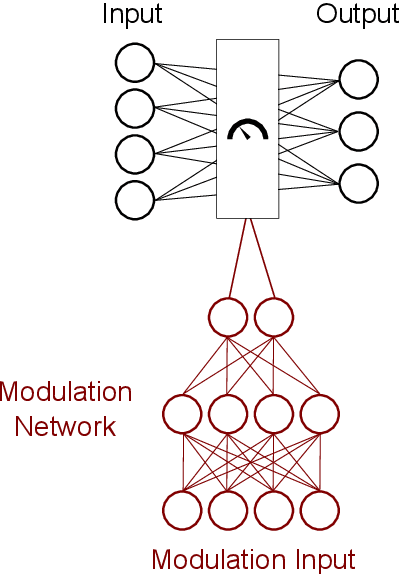
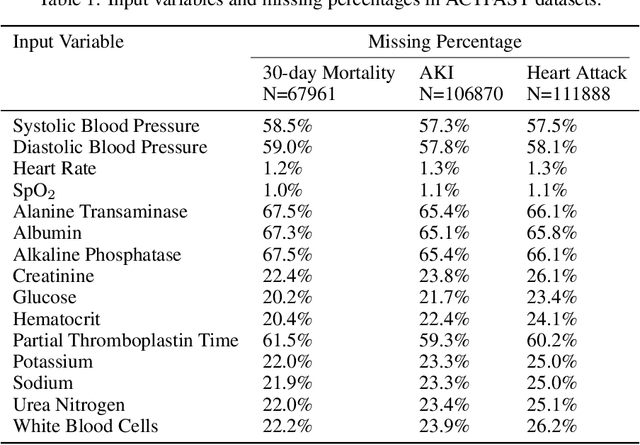
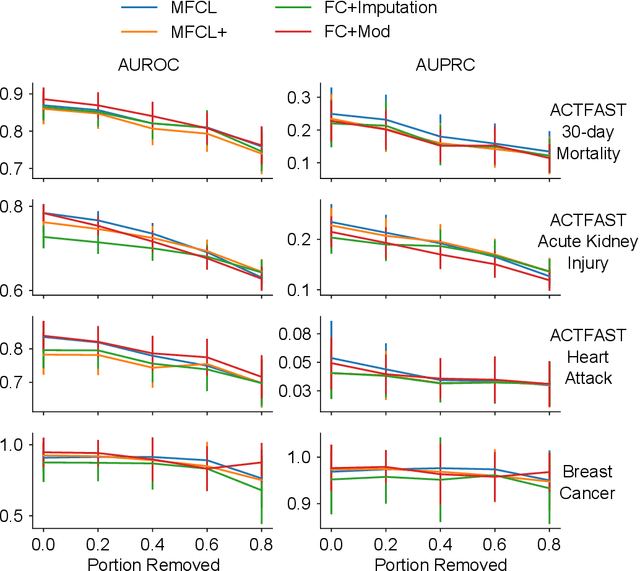

Data quality is a common problem in machine learning, especially in high-stakes settings such as healthcare. Missing data affects accuracy, calibration, and feature attribution in complex patterns. Developers often train models on carefully curated datasets to minimize missing data bias; however, this reduces the usability of such models in production environments, such as real-time healthcare records. Making machine learning models robust to missing data is therefore crucial for practical application. While some classifiers naturally handle missing data, others, such as deep neural networks, are not designed for unknown values. We propose a novel neural network modification to mitigate the impacts of missing data. The approach is inspired by neuromodulation that is performed by biological neural networks. Our proposal replaces the fixed weights of a fully-connected layer with a function of an additional input (reliability score) at each input, mimicking the ability of cortex to up- and down-weight inputs based on the presence of other data. The modulation function is jointly learned with the main task using a multi-layer perceptron. We tested our modulating fully connected layer on multiple classification, regression, and imputation problems, and it either improved performance or generated comparable performance to conventional neural network architectures concatenating reliability to the inputs. Models with modulating layers were more robust against degradation of data quality by introducing additional missingness at evaluation time. These results suggest that explicitly accounting for reduced information quality with a modulating fully connected layer can enable the deployment of artificial intelligence systems in real-time settings.
Reinforcement Learning with Algorithms from Probabilistic Structure Estimation
Mar 15, 2021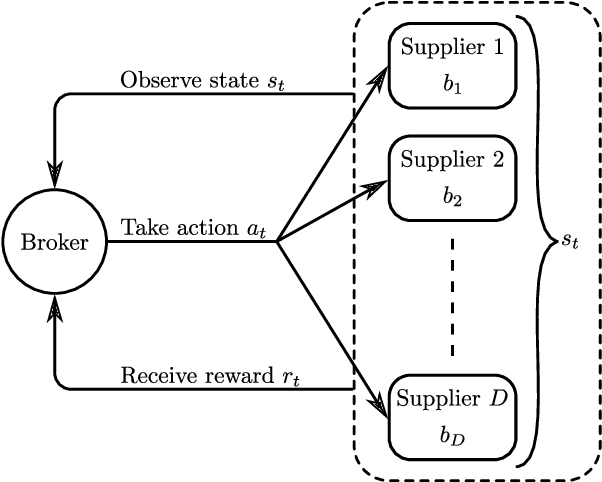
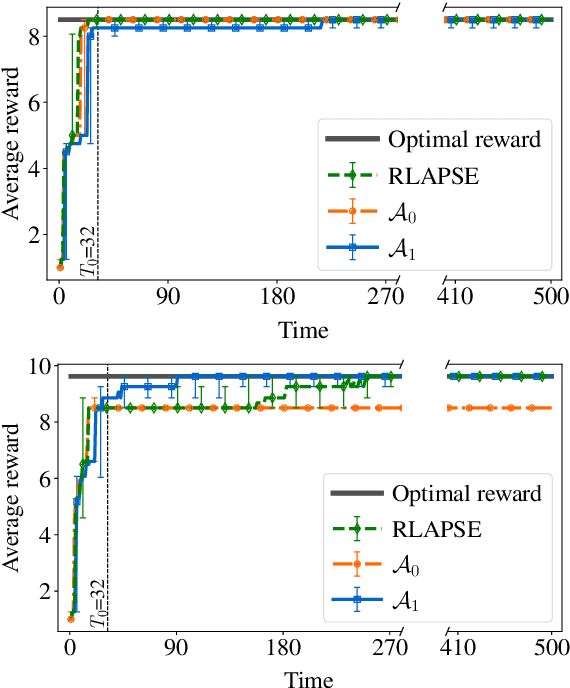
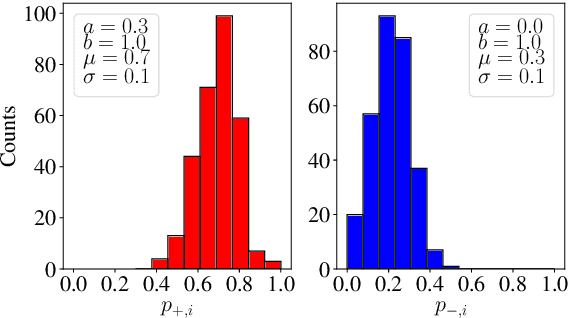
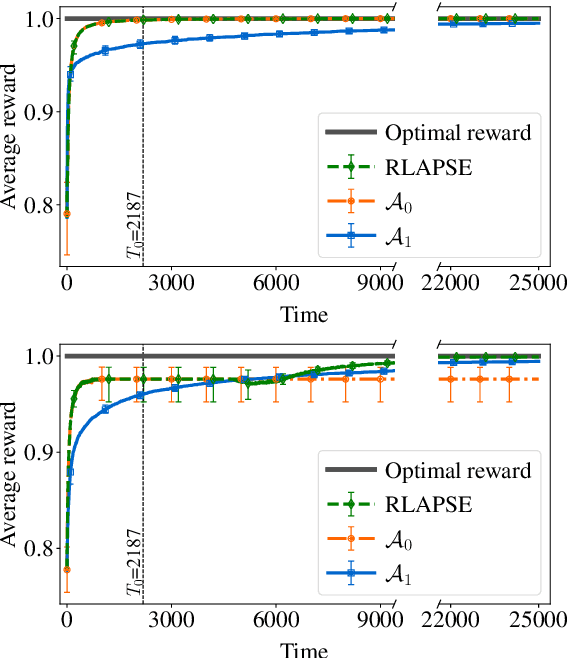
Reinforcement learning (RL) algorithms aim to learn optimal decisions in unknown environments through experience of taking actions and observing the rewards gained. In some cases, the environment is not influenced by the actions of the RL agent, in which case the problem can be modeled as a contextual multi-armed bandit and lightweight \emph{myopic} algorithms can be employed. On the other hand, when the RL agent's actions affect the environment, the problem must be modeled as a Markov decision process and more complex RL algorithms are required which take the future effects of actions into account. Moreover, in many modern RL settings, it is unknown from the outset whether or not the agent's actions will impact the environment and it is often not possible to determine which RL algorithm is most fitting. In this work, we propose to avoid this dilemma entirely and incorporate a choice mechanism into our RL framework. Rather than assuming a specific problem structure, we use a probabilistic structure estimation procedure based on a likelihood-ratio (LR) test to make a more informed selection of learning algorithm. We derive a sufficient condition under which myopic policies are optimal, present an LR test for this condition, and derive a bound on the regret of our framework. We provide examples of real-world scenarios where our framework is needed and provide extensive simulations to validate our approach.